

こんにちは、すきとほる疫学徒です。
【初心者のためのRで医療ビックデータ解析】シリーズは、「これまでデータの解析を行ったことがない人」を対象にして、Rで医療ビックデータを解析する方法をわかりやすく解説していきます。
全てのシリーズを受講し終えた時点で、「診療報酬データやレジストリーといった医療大規模データを、自立して解析できる」状態になることを目指しております。
全研究者、Rユーザー化計画、ここに始動す。
こちらの記事はパート2になりますので、まずパート1をお読み頂いてから、この先に進んで頂けますと、より一層Rの勉強が楽しめるかと思われます。
Rをインストールしよう
前回の記事では「Rがいかに素晴らしいか」ということを熱弁して参りました。
そんな私の記事を読んだ皆さんは、もはやRにメロメロになり、今すぐにでもRを触りたくてうずうずしているはず。
ということで、今回はいよいよRのインストール方法をお伝えいたします!
これまで説明してきたRの魅力ですが、実はRという解析ツールはそれ単体では100%を引き出すことができません。
R Studioという開発環境(アプリみたいなもん)を通してRを使う必要があります。
というわけで、まずはお手持ちのパソコンにRとR Studioをインストールしていきましょう。
ユーザー名を英語にしよう
皆さん、使用しているパソコンのユーザー名は英語ですか?日本語ですか?
なんと悲しいことに、R、そしてR Studioは日本語ユーザー名ではうまく動きません。
理由は、日本語ユーザー名を使うことでパス名に日本語が含まれてしまうからです。
パスって何?
って感じですよね。
パスとは、Rにパソコン内のどこかからデータを呼び出す時や、Rからパソコン内のどこかにデータを保存する時に使用する、住所のようなものです。
例えばこのような感じで。
/Users/Sukitohoru/Desktop/R_file/Test/Missing.R
Usersの後のところが、皆さんがパソコンで使っているユーザー名になります。
もし日本語のユーザー名を使っていると、このようにパスにも日本語が紛れ込んでしまうことになり、Rがうまく読み込んでくれないんですね。
ですので日本語ユーザー名を使用している方は、ユーザー名を変更するか、それか新たに英語のアカウントを作成し、そちらでRを使用するようにしましょう。
RおよびR studioのダウンロード
英語のユーザー名のアカウントが用意できたら、いよいよRのダウンロードに進んでいきましょう。
WindowsとMacでダウンロード方法が異なるために、それぞれ説明してきます。
Windowsの方
こちらのリンクから、Rのダウンロードページにログインしてください。
こんな画面がでてきましたでしょうか?
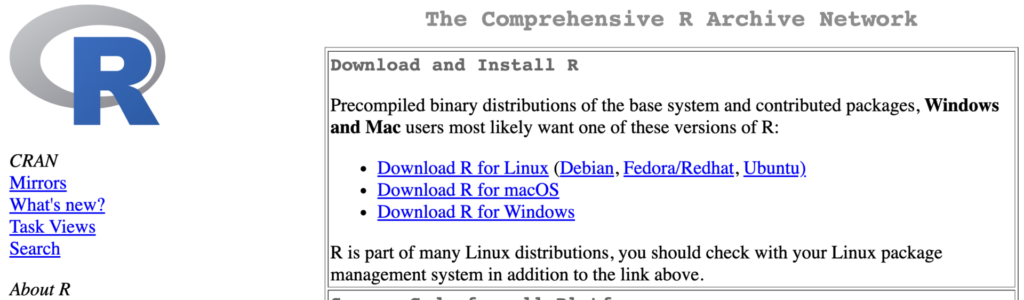
そしたら、”Download R for Windows”
をクリックしてください。
するとこんな画面になりますので、”base”をクリックしましょう。

そんであとは、”Download R 4.1.3 for Windows”をクリックです。
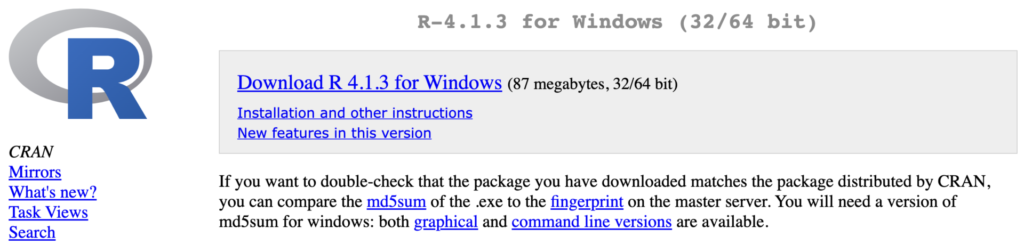
そうするとダウンロードが始まりますので、あとはダウンロードしたファイルを実行してあげればインストールの完了です。
なお、RはOnedriveなどのクラウド系のフォルダに入れてしまうとうまく作動しませんので、必ずローカル環境に保存するようにしましょう。
ちなみに、上の4.1.3というのはRのバージョンでして、iPhoneのOSなどと同じようにRも定期的なアップデートを行なっております。
ですので、皆さんも適時Rをアップデートしていく必要がありますが、それはまた今後ご説明します。
Rがインストールできたら、次はR Studioです。
こちらのリンクからダウンロードページにアクセスしてください。
するとこんな感じで、「あんたのパソコンにおすすめなのはこのバージョンやでー!」って、自動でダウンロードすべきファイルを指示してくれます。
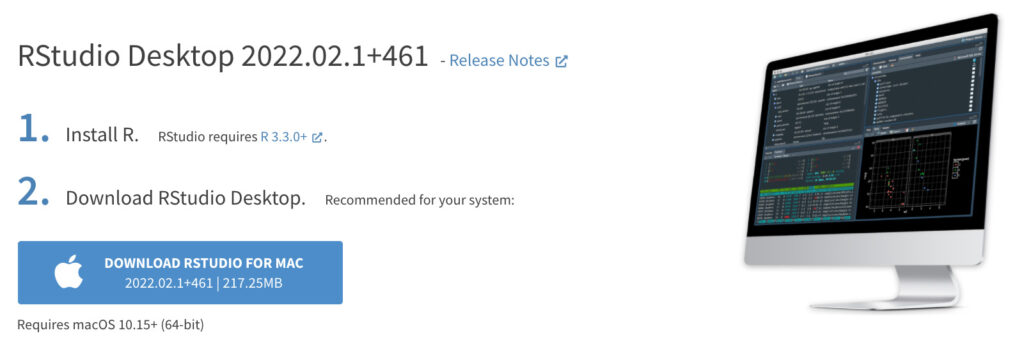
優しいですよね、R Studio。
もはやこの時点でRとR Studioのユーザビリティの違いがびしばし伝わってくる気がします。
これからもR Studioの優しさに包まれていきましょう。
R同様に、クリックすれば自動でダウンロードが始まります。
ダウンロードが終われば、ファイルをクリックしてインストールをスタート、それで完了です。
なお、R同様にR Studioもクラウド系ファイルだとうまく動かないことがありますので、必ずローカル環境に保存してあげましょう。
以上で、R Studioを使う準備は完了です。
RとR Studioがインストールされた段階で、勝手に紐付けが完了しますので、あとはR Studioを開いてやるだけで、いつでもRを使えるようになります。
こんな感じで、R Studioのアイコンがアプリとして表示されているはず。

ちなみに、こっちがRのアイコンです。

皆さんが使うのは、RではなくR Studioですので、間違ってこっちのRのアイコンをクリックしてはなりません。
「あれ、なんか私のRだけみんなのと違うんだけど」と、長らく路頭に迷うことになります。
Macの方
*Windowsの説明とほぼ重複していますので、そちらをご覧になった方はスキップしてください。
こちらのリンクから、Rのダウンロードページにログインしてください。
こんな画面がでてきましたでしょうか?
そしたら、”Download R for macOS”
をクリックしてください。
するとこんな画面になりますので、MacのOSに合わせて”R-4.1.3.pkg”か”R-4.1.3-arm64.pkg”をクリックしましょう。
M1以降のMacを使っている方は、二番目のやつですね。
なお、OSによってはRがうまく作動しない場合があるため、インストール前に必ずパソコンのOSを最新の状態にアップデートしておくことを推奨します。

ちなみに、Mac OSは画面左上のAppleマークから、”About This Mac”で確認できます。
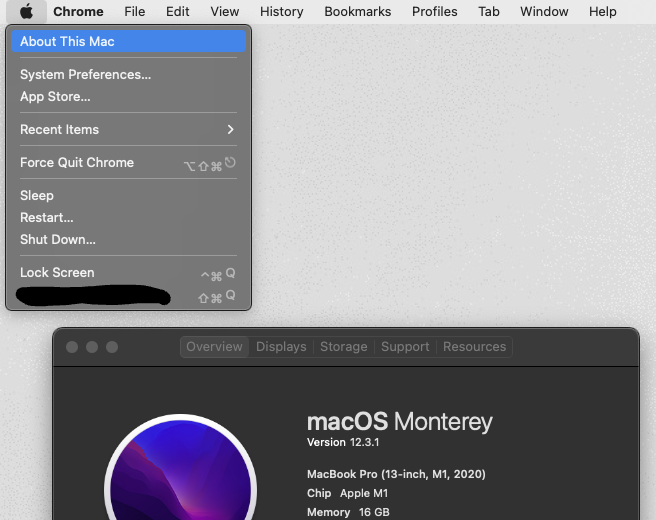
ファイルをクリックするとダウンロードが始まりますので、あとはダウンロードしたファイルを実行してあげればインストールの完了です。
なお、RはOnedriveなどのクラウド系のフォルダに入れてしまうとうまく作動しませんので、必ずローカル環境に保存するようにしましょう。
次のステップですが、Macの場合はWindowsよりもインストールべきファイルが一つ多くなります。
先ほどRをインストールした画面を見ていただくと、このように”XQuarts”という記載があります。
インストールしたRのバージョンの記載にあるXQuartsをクリックし、ダウンロード、そしてインストールしてあげましょう。

R、XQuartzがインストールできたら、次はR Studioです。
こちらのリンクからダウンロードページにアクセスしてください。
するとこんな感じで、「あんたのパソコンにおすすめなのはこのバージョンやでー!」って、自動でダウンロードすべきファイルを指示してくれます。
優しいですよね、R studio。
もはやこの時点でRとR Studioのユーザビリティの違いがびしばし伝わってくる気がします。
これからもR Studioの優しさに包まれていきましょう。
R同様に、クリックすれば自動でダウンロードが始まります。
ダウンロードが終われば、ファイルをクリックしてインストールをスタート、それで完了です。
なお、R同様にR Studioもクラウド系ファイルだとうまく動かないことがありますので、必ずローカル環境に保存してあげましょう。
以上で、R Studioを使う準備は完了です。
RとR Studioがインストールされた段階で、勝手に紐付けが完了しますので、あとはR Studioを開いてやるだけで、いつでもRを使えるようになります。
こんな感じで、R Studioのアイコンがアプリとして表示されているはず。
ちなみに、こっちがRのアイコンです。
皆さんが使うのは、RではなくR Studioですので、間違ってこっちのRのアイコンをクリックしてはなりません。
「あれ、なんか私のRだけみんなのと違うんだけど」と、長らく路頭に迷うことになります。
R Studioをいじってみよう
今日はインストールの方法だけをお伝えするつもりだったのですが、せっかくインストールしたままお預けなんてのも寂しい気がするので、少しだけR Studioに触ってみましょう!
先ほどのR Studioのアイコンをクリックして頂くと、こんな画面が立ち上がるはずです*。
*私はあれこれカスタマイズしているので、初期バージョンとは少し見た目が変わっているかもしれません。
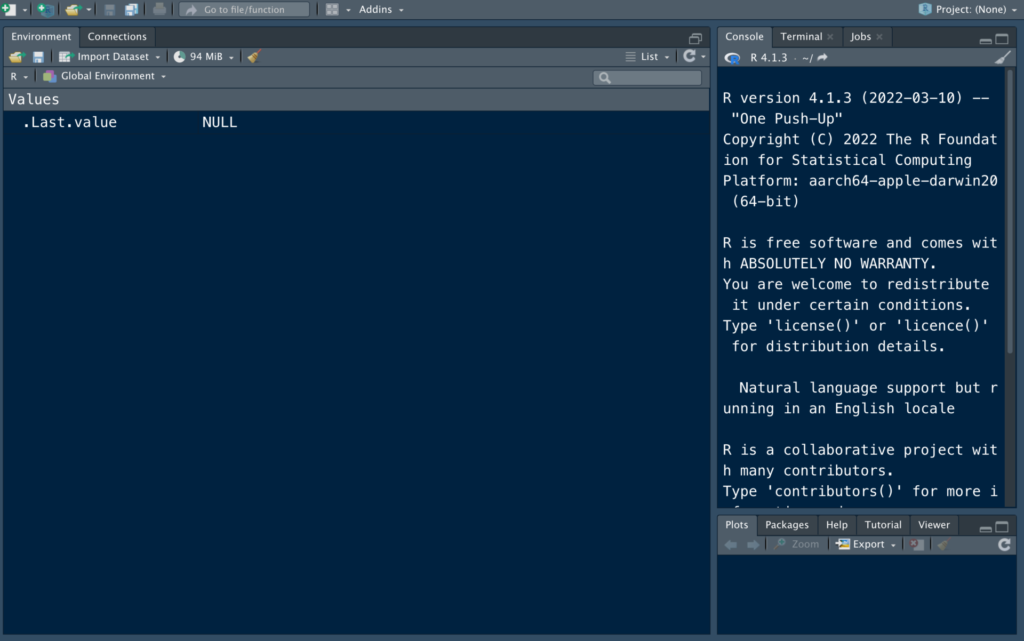
「なんか色んなとこに色んな表記があってよう分からん」と思うかも知れませんが、それはまた次回説明しますので、今回は置いておきます。
そしたら、左上のノートアイコンをクリックしてあげて、さらに”R Script”をクリックです。
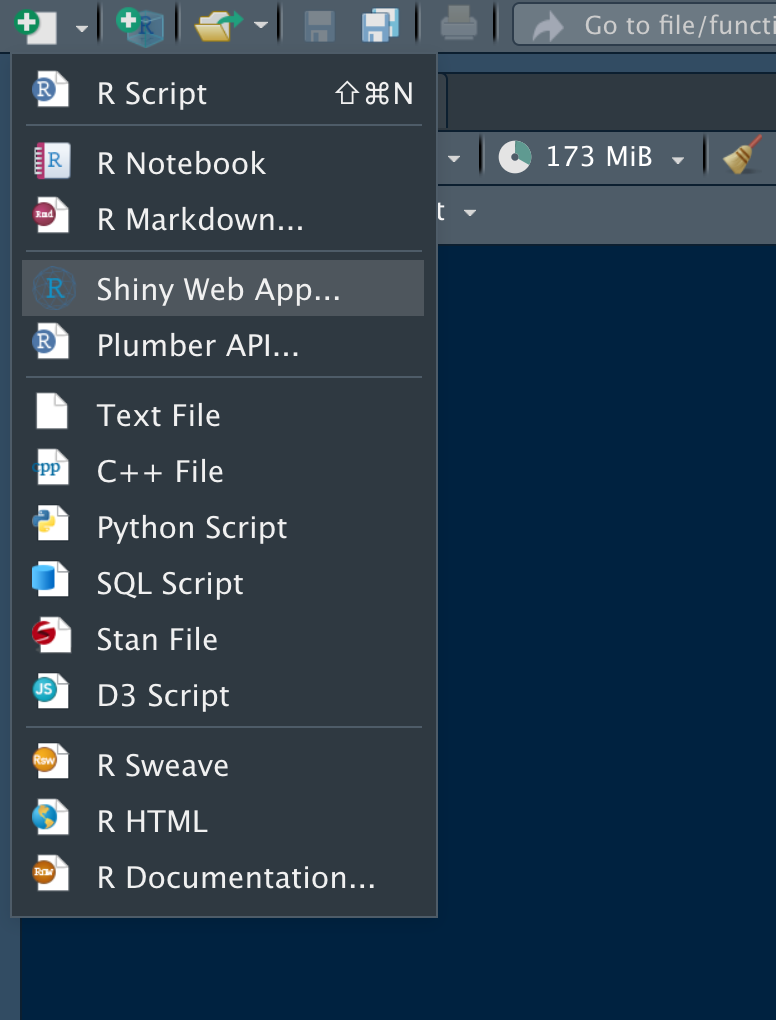
すると、こんな感じで”Untitled1”と書かれたスペース(Sourceと呼びます)が展開されているはずです。
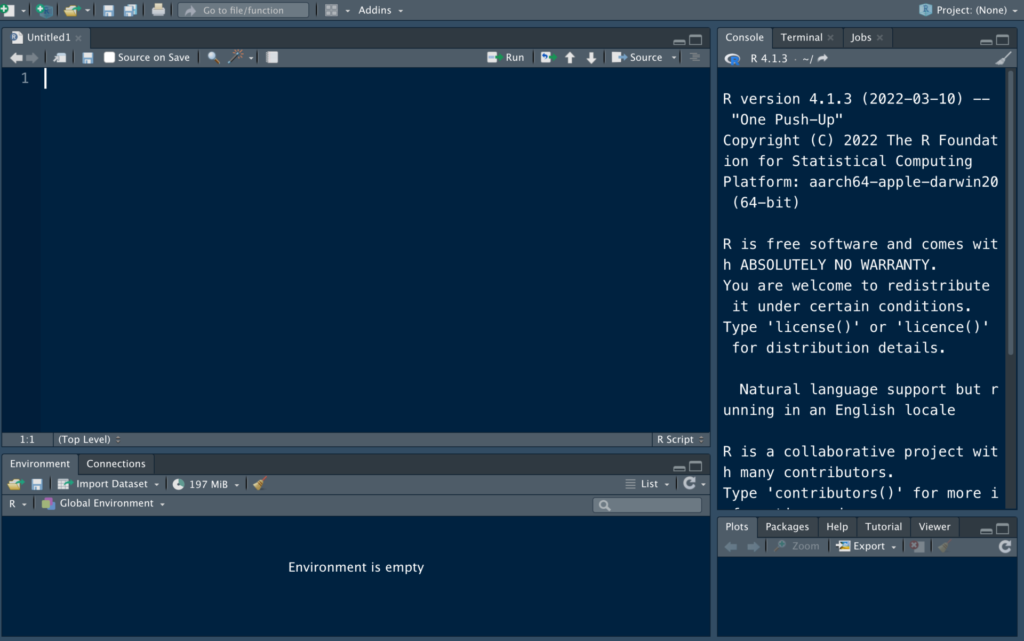
このスクリプトが、いわゆる”コードを書く”場所になります。
Rでは、ロードされたデータセットに対して、このSourceに書かれたコードを指示として飛ばしてやることで、データをクリーニングしたり、変数を作ったり、グラフを描いたり、多変量回帰なんかの統計解析を行うことになります。
余談ですが、基本的にRにおいては加工したデータセットではなく、このSourceに書かれたコード自体を保存します。
つまり、一旦Rを閉じて、作業を再開するときには、再びデータセットに対してコードから指示を出し、データの加工をしていく必要があるわけですね。
なぜ加工したデータセットではなく、コード自体を中心に作業を進めていくかというと、解析の再現性を担保するためです。
仮にコードが保存されず、加工されたデータセットのみが手元に残るのだとしたら、色々と都合の悪いことがおきてくるんです。
「あれ、この変数ってどうやって作ったんだっけ?」
「このコホートって、どんな除外基準で抽出したんだっけ?」
とかですね。
解析というのは、個人のパソコンの中で作業が完結してしまうため、どうしてもブラックボックス的な性質があります。
ですので、何らかのコードの打ち間違いをしていたり、人によっては恣意的に自分の都合の良いようにデータを操作してしまうということが起こり得るわけです。
そんな時も、コードが残っていれば何度でも、誰でも解析の整合性を確認することができます。
そうした事情を加味してか、最近はJournalによっては解析に使用したデータセットと、コードを提出させるところも増えてきましたね。
また、加工したデータセットではなくコードをベースにして作業を進めていくことで、過去に戻ってデータセットを修正するということが容易になります。
SPSSのように、加工したデータセットをベースにした解析ツールでは、「しまった、必要な変数を間違って削除してしまった!」、「除外する対象集団を間違えてしまった!」なんて時には、いちいちバックアップとして保存してあったデータセットを開き、そこから作業をリスタートせねばなりません。
必然的にデータセットの数が増えていき、うまく管理しないと「めっちゃ大量にデータセットがあるんだけど、最新のやつどれだっけな…」と迷子になること間違いなしです(私だけかもしれませんが)。
そんな時、コードベースで解析を進めるRであれば、スクリプト上の修正したい箇所にカーソルを持っていき、コードを打ち直せば、簡単に修正作業を行うことができるわけですね。
「いちいちコードを走らせて、毎回データセットをゼロから加工するのって面倒じゃない?」
と思うかもしれませんが、よっぽど思いデータセットを使わない限りは、Rは最初から最後まで瞬時にオーダーを完了してくれます。
ただ数百万人のClaims dataで、多重代入法といった比較的負荷の重い処理を施すと、解析終了まで数日間かかるということもあります。
大学院時代、教授面談の日に結果をお見せできるよう、面談日から逆算して数日前に解析を走らせておき、いざ面談当日にパソコンを開いてみたらRがフリーズしていたなんていう状況に遭遇し、戦慄したことを思い出します。。。
前も言いましたが、StataやSASなんかの有料ソフトと比べると、どうしてもRは解析負荷に対して脆弱になってしまうんです。
なので、負荷のかかる解析を実行した日には、終了するまでの数時間〜数日間は「あー、大丈夫かな、頼むからフリーズしてないでくれよ。。。」と四六時中ふあんがよぎっていました。
さすがにRを開くたびにそれだけ時間のかかる処理を毎回施すわけにもいかないので、私はいつも負荷の重い解析が終わった時点でデータセットごと保存し、次の時点からはそのデータセットをロードするようにしています。
でも、もし後々「ここ修正しよう」と思ったポイントが、データセットの保存時点より前だったら、結局そこに戻り、再び数日間かけて解析をやり直さねばならないので、悲しい気持ちになります。
こういう時には、解析をRunする前に不要な変数はとにかく削除しておき、少しでもデータを軽くしておくのが吉ですね。
閑話休題。
話がそれてしまいましたが、このチャプターの目的は「とりあえずRに触ってみよう」でしたね。
ではまず、先ほど開いたスクリプト(上の画像でカーソルがある部分です)に
1 + 1
と打ち込んでみましょう。
これで、命令を出すためのコードが書けました。
そうしたら次はRに対して「このコードを実行しなさい!」という命令を出します。
”1+1”と同じ行にカーソルを合わせて、Sourceの右上にある”Run”を押してあげましょう。
そうすると、画面の右側のConsoleという枠に、計算結果である”2″が表示されているはずです。
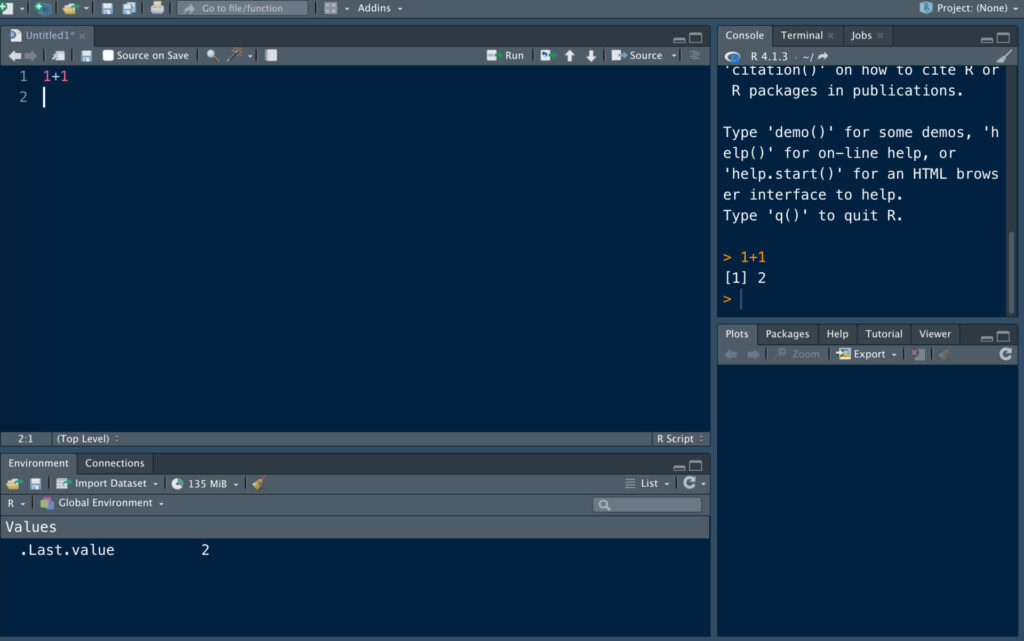
もちろん、足し算だけではなく、色んな計算も。
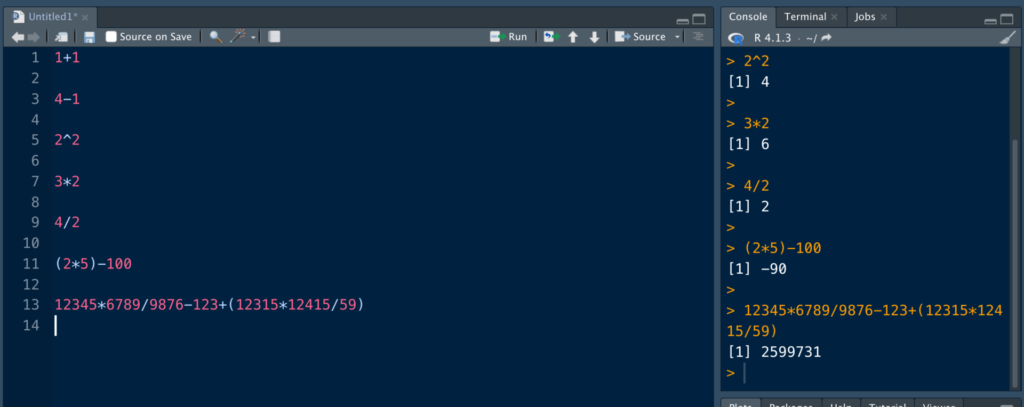
+:足し算
-:引き算
^:乗数
*:掛け算
/:割り算
です。
ちなみに、コードを実行するたびにいちいちRunをクリックするのは超絶面倒ですので、ショートカットを使用しましょう。
Windows:Ctrl + Enter
Mac:Command + Enter
です。
ショートカットを入力すると、解析単位ごとに解析を走らせてくれます(”1+1″、 “4-1″など)。
なので、上に書いたコードを全て実行したい時には、全部で7回Enterを押す必要があるわけですね(CtrlもしくはCommandは押しっぱなしでOKです)。
過去に作成したスクリプトを全て実行するときなどは、何度もなんどもEnterを押すのは面倒だと思いますので、そういう時にはまとめて実行したいコードをカーソルで選択して、一度だけEnterを押してやれば、選択された範囲内のコードが全て実行されます。
これで!
もう!
あなたも!
Rユーザーです!!!
「コードなんて書いたことないからどうしたらいいかわかんないよ」
「なんか難しそうだし、ほんとにできるかな」
って不安に思われていた方もいらっしゃるかもしれません。
でも大丈夫!
もちろん、実装したい解析によって複雑度は様々ですが、結局のところやることは「ルールに則ってインプットをして、欲しいアウトプットを出す」ということに過ぎません。
(わたし個人の)感覚としては、数学の方程式を解いたり、パズルゲームにチャレンジしている時に近いです。
「あれとこれを、この順番で組み合わせると、あっちがこうなるから、こっちにこれを足してあげて、んで最後にそれをここにもってきて」みたいな。
ルールを覚えるまでにはある程度の反復練習が必要かもしれませんが、よほど特別な解析をしない限りは、医療大規模データベースの解析に必要なルール(コード)というのは限られています。
実際、私もこれまでRを使って何度も国内外の医療大規模データベースの解析を行なってきましたが、使用したコードというのは殆どオーバーラップしています。
なので、使うデータベースまで同じという場合は、結構な部分を前に書いたコードのコピペで対応できちゃったりもします。
さすがに最終的に使う解析であったり、使用する変数はプロジェクトごとに差がありますので、その部分だけコードを変えてあげるという感じです。
さて、記事も長くなってきましたので、今日はここまでとしましょう。
R Studioはそのまま閉じてしまってください。
閉じる際に「コード保存してないけどいいんか?!」みたいな警告が出ますが、今回は全て無視して閉じてしまって大丈夫です。
このシリーズ記事『初心者のためのRで医療ビックデータ解析』では、Rで医療ビックデータを解析するたえに必要なテクニックを、最初から最後までゆっくりと、シンプルに解説していきますので、どうぞ皆さま長らくお付き合い頂けますと幸いです。
終わりに
いかがでしたでしょうか?
次回はR Studioの見方や、おすすめの設定、そしてファイルの保存方法、データセットの読み込み方などを解説していきたいと思います。
できるだけ多くの方に楽しく、簡単にRをマスターする機会を提供したいと思っておりますので、もし「ふーん、いい記事じゃん」と思ってくださった方がおりましたら、この記事の下部のシェアボタンから、記事をシェアして頂けますとありがたく思います。
すきとほる疫学徒からのお願い
本ブログは、読者の方が自由に記事の金額を決められるPay What You Want方式を採用しています。
「勉強になった!」、「次も読みたい!」と本ブログに価値を感じてくださった場合は、以下のボタンをクリックし、ご自身が感じた価値に見合うだけの寄付を頂戴できますと幸いです。
もちろん価値を感じなかった方、また学生さんなど金銭的に厳しい状況にある方からのご寄付は不要です。
引き続き情報発信していく活力になりますので、ぜひお気持ちに反しない範囲でご寄付をお願い致します!






