

こんにちは、すきとほる疫学徒です。
アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。
私が観測できている範囲でも、使用可能な医療DBが日にひに増えてきており、医療DB研究を行う研究者には、「使用可能な医療DBを把握し、それぞれの正しい使いどころをアセスメントする能力」が求められるようになってきました。
そのような医療DBの乱立の中で、日本薬剤疫学会をはじめとし、いくつかの機関、研究者が主だった医療DBの概要を説明してくださっております。
こちらの記事では「もう一歩進んだ医療DBの理解を」をテーマに、それぞれの医療DBがどのようなリサーチクエスチョンと相性が良いかということを、具体例を添えて実践的に説明していきたいと思います。
なお、医療DBの運営者、設立年、サンプルサイズ、母集団、収集されている項目などの基礎的な情報には触れませんので、それらの情報は以下の日本薬剤疫学会による日本で使用可能な医療DBのまとめをご参照ください。
https://sites.google.com/view/jspe-database-ja2020/%E3%83%9B%E3%83%BC%E3%83%A0
・それぞれの医療DBを使った代表的な研究
・それぞれの医療DBが得意とするリサーチクエスチョン

「RWD研究の支援をしてほしい」というご相談を多くの企業様から頂戴するので、企業様向けに正式に窓口を設置しました。
以下のアドレスに連絡頂ければ私に直通しますので、「1時間の無料相談」も含めてお気軽にご連絡ください(3営業日以内にお返事させて頂きます)。無料相談は大変ご盛況となっており、先着順にて対応させて頂いております。
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
私が経営するmMEDICI株式会社ではRWD利活用支援を事業の柱の一つとしており、以下の強みを有しています。「企業の」RWD研究においては日本トップクラスの解像度と経験値を有する自信がありますので、ぜひ無料相談でご体験くださいませ。
- 元大手外資の日本・グローバル出身の疫学専門家が全案件を担当するので、「企業の」RWD研究に高い解像度を有しています
- ただ成果物を納品するだけでなく、グローバルやKOLとの合意形成、社内プレゼン、規制当局対応などRWD研究の「プロセス」も全てまきとれます
- 企業のRWD研究を幾度となく経験しており、企画立案から論文化までの全フェーズを一気通貫で対応できます
- アカデミアのRWD研究者と広い繋がりを有しており、必要に応じた専門人材のアサインが可能です
- RWD研究だけでなく、事業立案、マーケ、広報、営業などのRWDビジネスも全て対応可能です
以下に私の実績を記載させて頂きます。
- 大手外資製薬2社にて、部門唯一の疫学専門家として活動をリード
- 「RWDビジネスの教科書」の書籍を出版(サイドバーをご覧ください)
- 企業でのRWD研究の経験は50本以上
- 製造販売後データベース調査のリード経験多数
- これまで製薬、CRO、コンサル、総合商社、ヘルステックなど10社以上の企業のRWD研究・RWDビジネスを支援
- 50組織以上にRWD研修を提供
- 全体統括・講師を勤めたJapan RWD Summitでは初回から約1,700名の集客を実現
無料相談では、以下のような内容を含め企業様の「RWD」と名のつく相談でしたら全て対応させて頂きます。
- このテーマでRWD研究はできるの?
- RWD研究っていくらくらいかかるの?
- RWD研究ってどんなプロセスでやれば良いの?
- 製造販売後データベース調査のやり方を教えてほしい
- RWD研究をするにはどんな専門家を雇えば良いの?
- 自社のRWDサービスを売りたいんだけど、強みはどこ?集客はどうすれば良い?
無料相談は先着順での対応となりますので、ご希望の企業様はぜひお早めのコンタクトをお願い致します!
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
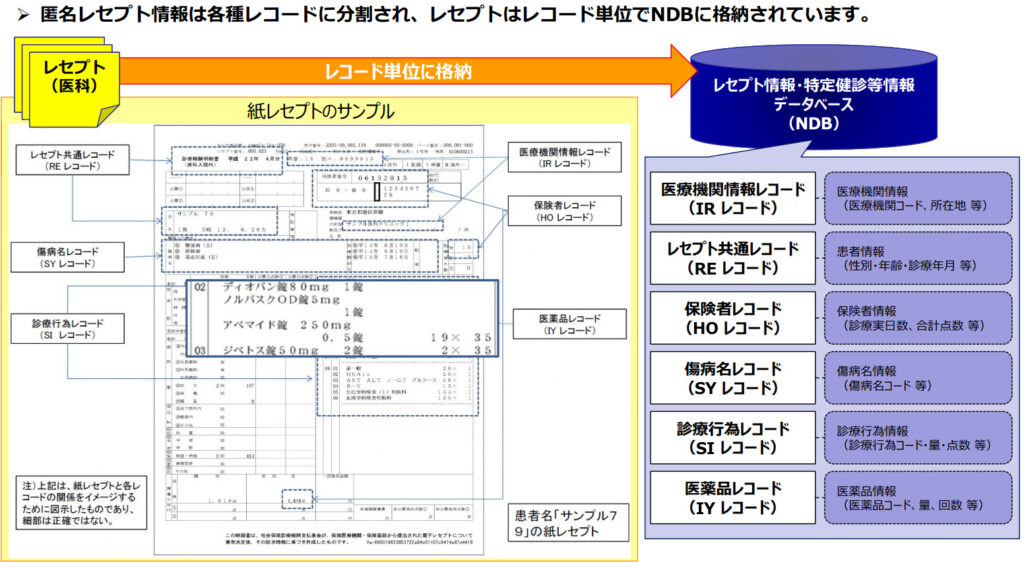
NDB(ナショナルデータベース)の説明
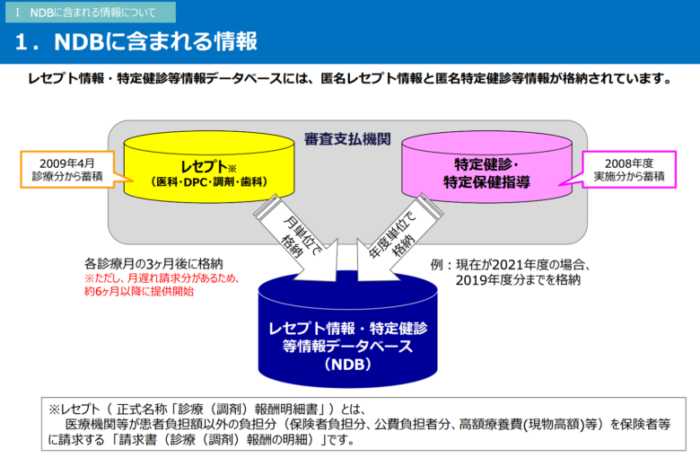
NDBは厚生労働省が管理するレセプト、特定健診&特定保健指導の情報から構成されるデータベースです。
特定健診&特定保健指導の結果は40歳以上75歳未満の一部の方しかデータが入っていませんので、ここでは単純に「NDBはレセプトデータベースだ」と考えましょう(将来的には拡充されるのですが)。
特定健診についてはこちらの記事で詳細に説明しています。
こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]

NDB(ナショナルデータベース)の特徴
悉皆性の高さ
NDBは日本で最も悉皆性の高いデータベースです。
日本全国から電子化レセプトを収集し、99%の日本国民が対象とされています。
また、JMDCが健康保険からのみレセプトを集めるデータベースだったのに対して、NDBデータベースは日本に存在する全てのタイプの保険者からレセプトを集めています。
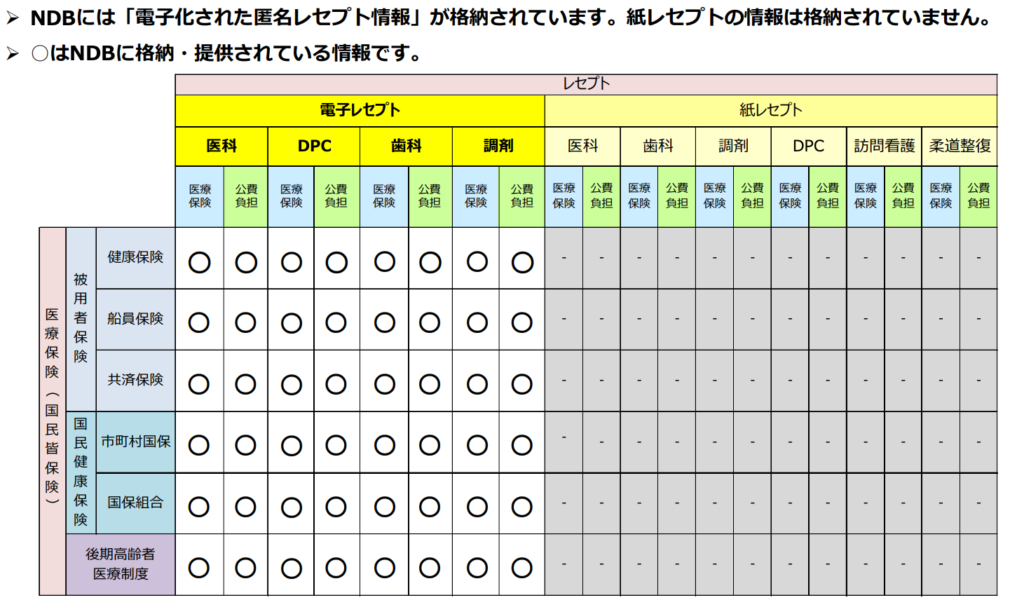
保険の種類は大きく以下の3つです。
- 主として中から大規模の企業で働く国民がカバーされる被用者保険
- 小規模な企業や自営業、非正規などで働く国民がカバーされる国民健康保険
- 日本の全ての75際以上の高齢者がカバーされる後期高齢者医療制度
ただし、全てのレセプトが収集されているわけではなく、あくあでも対象は「電子化されたレセプト」のみです。
紙レセプトは収集されません。
ですので、NDBを使う際には「この研究のTarget Populationと実際に収集されるStudy Populationがどれだけずれているか(Generalizability)」ということを意識して研究をする必要があります。
さて、ではどのような集団で紙レセプトが多く使われているのでしょう。
以下の図の赤枠が全レセプトに占める紙レセプトの割合です。
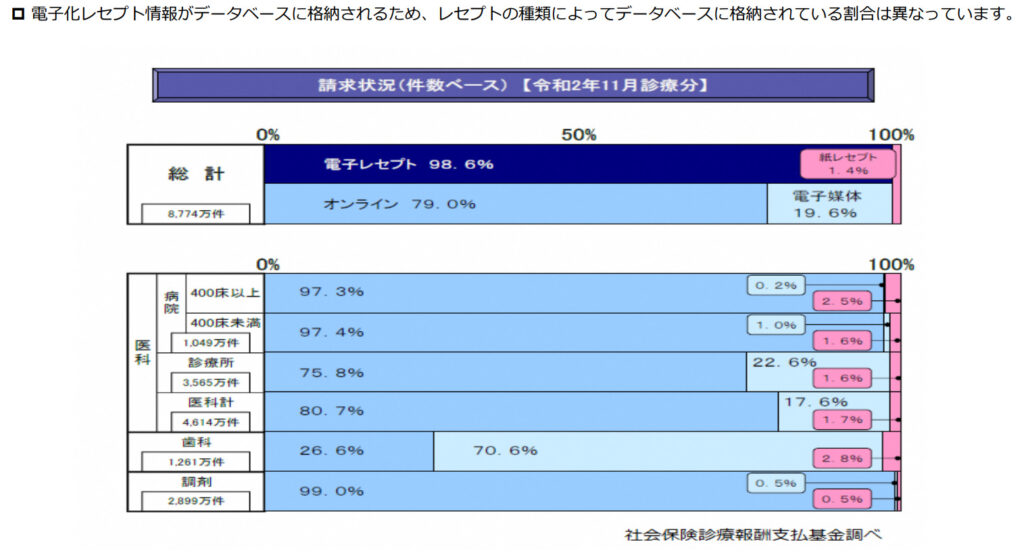
大病院は電子、診療所は紙かと思いきや、どうやら医科レセプトの中だと400床以上の病院で紙レセプト割合が2.5%と最も高くなっているようです。
なお、全体に占める紙レセプトの割合は1.4%でした。
ここで注意が必要なのが、このデータが令和2年11月診療分のデータであるという点です。
紙レセプトから電子レセプト化への変更は年々進んできたため、過去のデータでは上記の%よりも紙レセプトの割合が多く、そのため研究のGeneralizabilityが年度ごとに異なるという特徴があります。

患者の追跡性能のポテンシャルの高さ
JMDCやDPCデータベースが特定の保険者・医療機関からのみデータを集めているのに対し、NDBは保険者・医療機関を問わずに全ての電子レセプトを集めていますので、より長く患者を追跡するポテンシャルを秘めています。
なぜ「追跡できる」ではなく「追跡するポテンシャルがある」と書いているのか。
それは、残念ながらNDBには保険者・医療機関をまたいで患者を一意に特定するユニークIDが存在しないからです。
一国民に一つ与えられるID(マイナンバーのようなもの)のデータが格納されていれば、そのIDを用いて患者を紐づけることができますが、それが存在しないわけですね。
「じゃあ患者の紐付けができないのか」というとそうではなくて、完璧ではないのですがNDBにはハッシュ値1とハッシュ値2という患者紐付けのためのIDが格納されています。
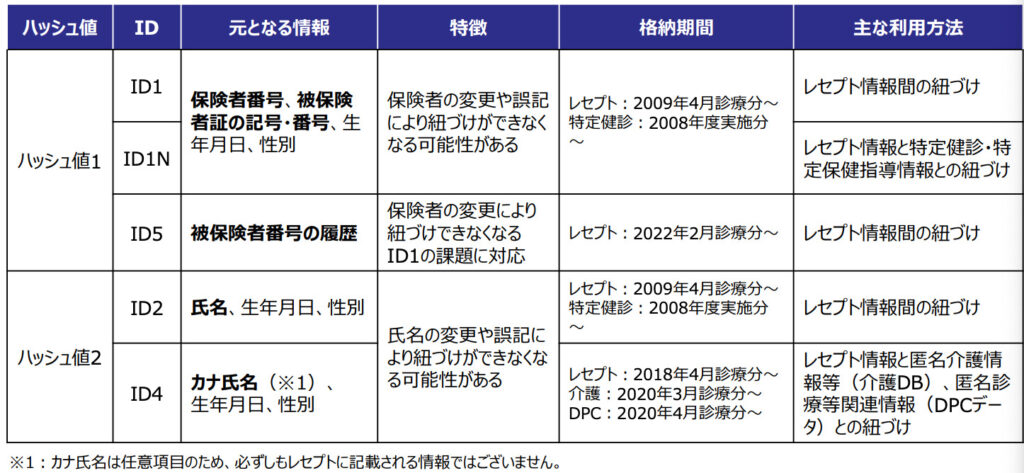
上のように、保険者番号、被保険者証の記号・番号、生年月日、性別などを任意で組み合わせることで何パターンかのハッシュ値を作成します。
ハッシュ値はレセプトごとに作成されますので、ハッシュ値をもとにレセプト間を結合すれば、同じ患者を追いかけたレセプト群を作成することができるというわけですね。
イメージはこんな感じ。
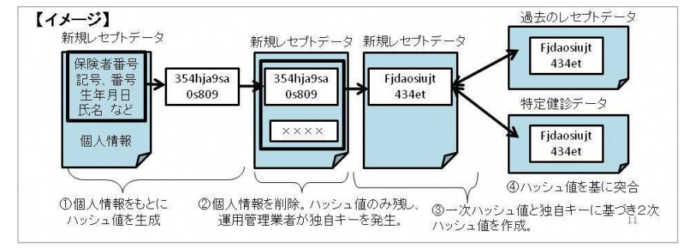
ただしこのハッシュ値、完璧ではありません。
保険者番号を使ったものは保険者が変われば(転職や後期高齢者保険への加入など)ハッシュ値も変わりますし、同じく氏名を使ったものも結婚などで苗字が変わればハッシュ値も変わります。
NDBが構造的に最大の追跡可能性を発揮するポテンシャルがあるデータベースであることは確かですが、そのためには国民全員に一意に振られるIDがNDBに格納される日を待たねばなりません。
データの種類の多さ
NDBは日本国民のほぼ全体をカバーするサンプルサイズの悉皆性の高さに加えて、多種多様なデータを含んでいます。

病院や診療所で発生する医科レセプトに加えて、歯科レセプト、調剤レセプト、そして訪問看護に関連した医療費などですね。
また、令和2年10月からは介護保険のレセプトとも結合が開始され、これによって訪問診療や通所サービス、老健施設への入所など、介護保険で賄われる介護サービスの情報も入手できるようになりました。
加えて、NDBは将来的には国が管理する様々なデータベースとの結合が予定されています。

台湾やデンマークでは既に共通IDを用いて各種データベースを結合したAll in Oneなデータベースが存在し、そのため非常に有意義なデータベース研究が数多く出版されていますが、日本もそのような研究環境がいつか実現されるかもしれませんね。
大きな期待が寄せられます。
データの提供形態が3種類ある
NDBには3種類の提供形態があります。
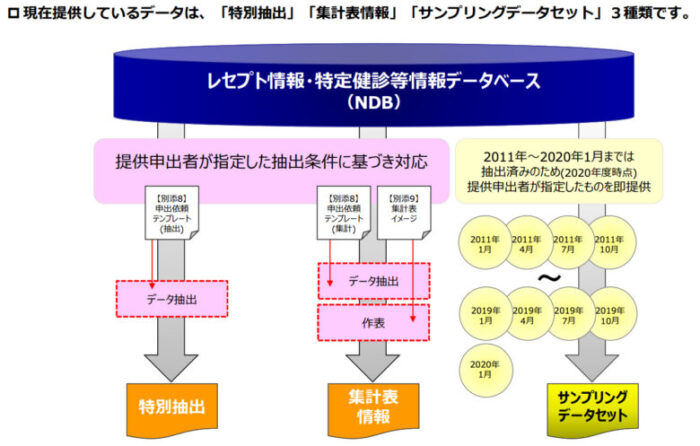
- 特別抽出:依頼者のリクエストに応じて特定の患者、変数の個別データを提供
- 依頼者のリクエストに応じて非個別の集計データを提供
- 依頼者のリクエストに応じて特定月の1%~10%のサンプリングされた個別データを提供
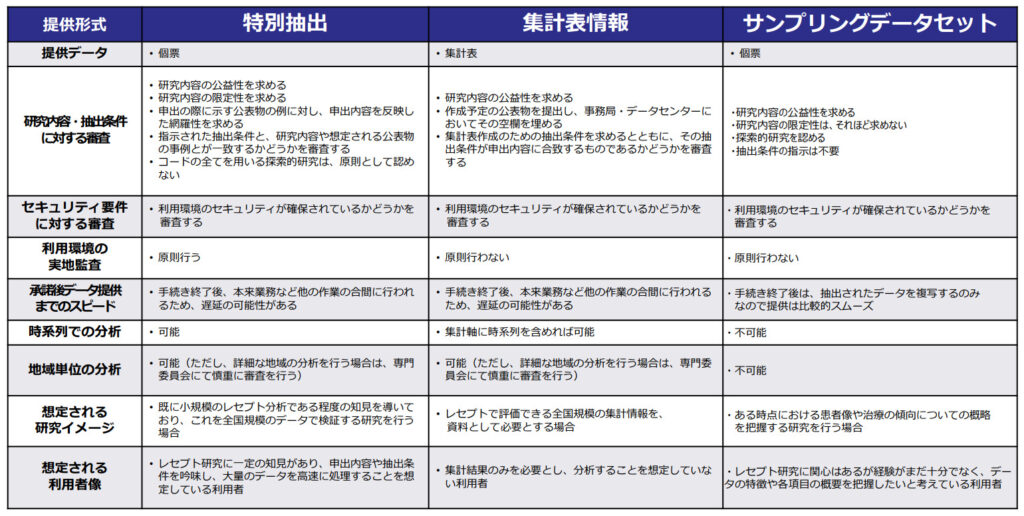
とりあえず一番詳しいデータをもらっとけばいいんじゃないの?
詳しいデータほど提供までの審査が複雑・長期間になるから、良し悪しがあるんだ
この3種に加えて、厚生労働省への申請なしで誰でもホームページからダウンロードできるデータとしてNDBオープンデータが存在ます。
各年度の疾患別、提供薬剤・処置別などに発生件数をまとめたデータです。
https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000177182.html
Excel形式での提供ですが、なんと素晴らしいことに分析サイトも公開されています。
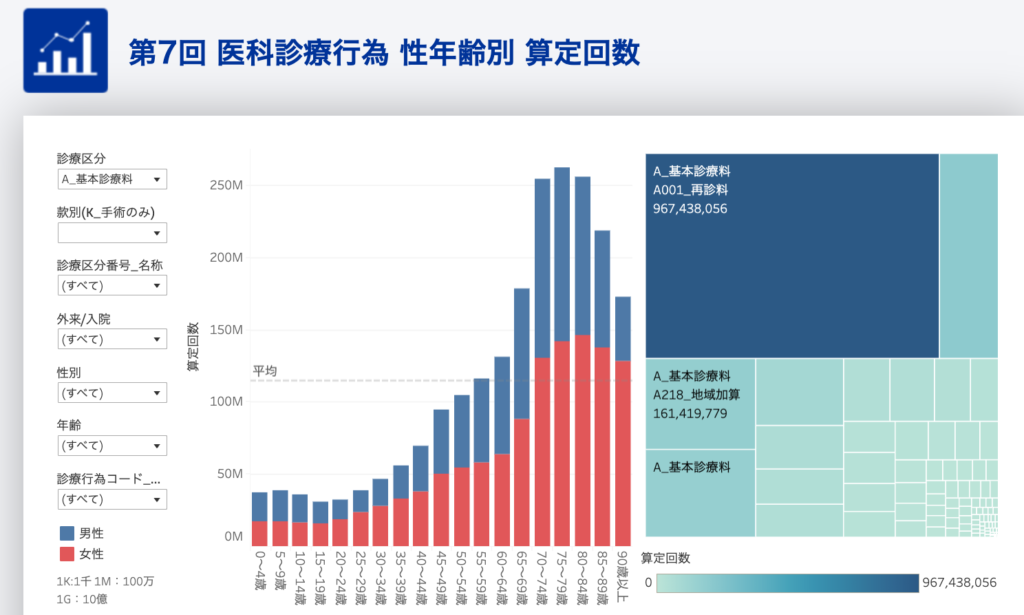
誰でも感覚的に「この疾患の患者ってどれくらいいるの?」とか、「この医療ってどれくらい提供されているの?」ということを調べることができるので、いじってみると良いでしょう。
https://www.mhlw.go.jp/ndb/opendatasite/
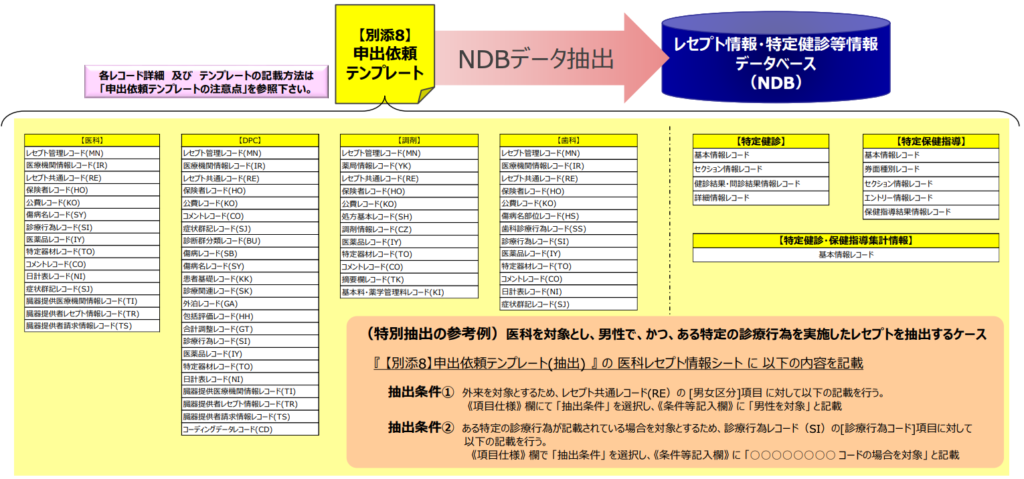
データが超複雑
NDBは「保険請求のために集められたレセプトを研究のために二次利用する」というモチベーションで集められているため、研究利用しやすい親切な形式ではデータが入力されていません。
JMDCやMDVなどの商用データベースも同じくレセプトで構成されるデータベースですが、あちらは商品として既にJMDCやMDVさんが綺麗に整えてくださったデータベースです。
ですので、商用データベースの感覚でNDBに触ると地獄をみること間違いなしです。
NDBの構造を図にするとこんな感じ。
いや、分からないわ…
だよね。とりあえずここでは「NDBのデータ構造はやばい」ってことだけ覚えておいて
ちなみに練習用のサンプルも公開されているけれど、スペシャリスト以外には暗号にしか見えません。
また、産業医科大学が練習用のデータセットを公開してくれています。
https://sites.google.com/site/pmchuoeh/activities/report/millet
社会保険診療報酬支払基金のホームページにもサンプル用のレセプトがあります。
https://www.ssk.or.jp/seikyushiharai/rezept/hokenja/download/index.html
ただ、経験者のサポートなしにこれらのデータをいじっても「マッタクワカラン」状態になること間違いなしですので、NDBの解析の練習をする際には必ず経験者のサポートの元やりましょう。
NDBを扱うには日本の保険医療制度や実臨床、そしてNDBという制度への深い理解が必要ですので、それらの理解なしにデータを扱ってしまうと、致命的な間違いを犯し、誤った結果を世間に公開してしまう恐れがあります。
助けてくれる人が身近にいないんだけど、どうしたらいい?
「NDBユーザーの会」っていうNDBの匠たちによるプチ学会があるから、とりあえずそこに出るところから初めて見るといいかも(https://square.umin.ac.jp/ndb/index.html)。
NDB(ナショナルデータベース)の感動した論文例
奥村先生の論文群
奥村先生はおそらく日本で最も筆頭著者としてNDB論文をPublishされている研究者だと思います。
申請、解析ともにあの複雑怪奇&ストレス120%のNDBをここまで扱いこなす奥村先生に超感動しております。


また、奥村先生のホームページにはNDBに関して先生が作成してくださった非常にためになる資料がたくさん置かれていますので、NDBを扱おうとする研究者の方はぜひご覧になると良いと思います。
http://blue.zero.jp/yokumura/index.html
主たる癌手術における術前口腔ケアと術後合併症の関連

貴重なNDBの歯科レセを用いた論文で、British Journal of Surgeryという外科系の主要論文に掲載されています。
これまで、歯科医による術前口腔ケアの術後合併症予防の効果は十分に明らかにされていませんでした。
そのため筆者らは術前口腔ケアを受けた患者と受けていない患者の間で、術後の肺炎、そして30日以内死亡率を比較しました。
その結果、術減口腔ケアを受けた患者で肺炎および30日以内死亡率の双方が有意に低下することがわかり、術前口腔ケアの意義が示されました。
日本全国の湿布の処方状況とコスト

「湿布、無駄に出しすぎだろ」というツッコミは医療費に関心のある方であれば耳にしたことがあると思います。
その疑問を素朴に検証した論文です。
ですが、使用するデータベースがNDBなので、そんな素朴な疑問へのチャレンジにも強いバリューが生まれます。
ひとえに、NDBの悉皆性の高さゆえですね。
その特徴がよく現れているのがこちらの図。
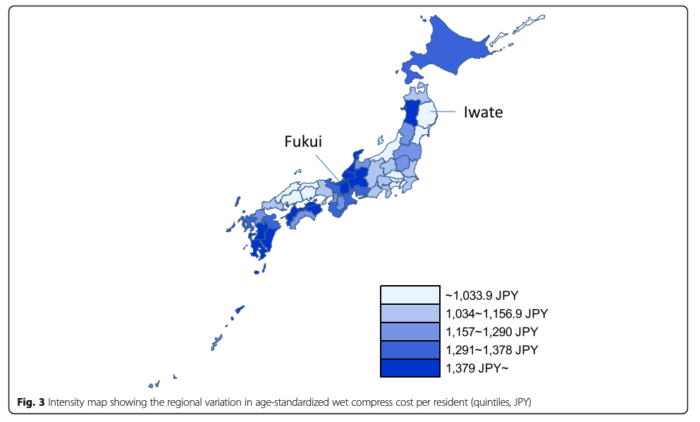
そう、日本地図です。
これはNDBが日本全国から(ほぼ)余すことなくデータを集めているからこそ描ける図であって、まさに医療大規模データベースの数の暴力が実現させた研究です。
数こそが正義だ!みたいな論文、実はちょっと好きです
この論文以外にもNDBを使った論文には日本地図が多く登場しますが、間違いなくNDBデータベースの正しい使い方の一つだと思います。
日本全国を対象とした記述疫学。
NDB(ナショナルデータベース)へのアクセス
NDBの最大の欠点、それはデータベースへのアクセスが超大変ということ。。。
「親の仇だ!」と言わんばかりに申請者へのアクセスを厳しくしています。
NDB(ナショナルデータベース)の申請
NDBは厚労省管理のデータベースですので、申請を行い許可が得られた場合のみ使用することができます。
購入すれば誰でも使用できるJMDCやMDVなどの商用データベースとは大きく違いますね。
申請の審査もいつでも受けられるわけではなく、このように年間の審査スケジュールは固定されています。
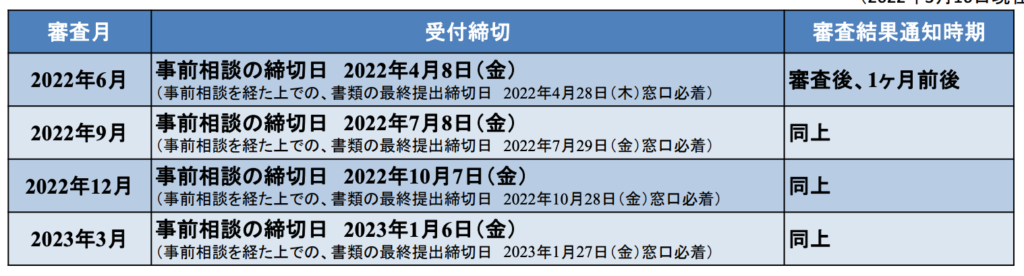
さらに、申請には多種多様な書類を提出する必要があります。

特徴は、
- この時点でデータのハンドリング、閲覧を行う取扱者を事前に規定
- 研究計画はかなりラフで良い
- 抽出する変数は希望性で、詳細なコードを書かなければならない
あたりでしょうか。
特に抽出する変数を記載する別添8は初心者には非常に難易度の高い書類となっており、日本のレセプト制度と実臨床に精通していないと書くことはできません。
かならず専門家と共に執筆しましょう。
NDB(ナショナルデータベース)のハンドリング
さて、上記の複雑怪奇な書類を提出しアクセスを許諾されたとしても、許諾から提供までに非常に長い待ち時間が生じます。
許諾から平均一年、申請からを含めるとさらに時間がかかりますね。
つい先日、こんなニュースも出ていました。

研究を行う場合は年度別の予算をたてますが、このようにデータ提供までに非常に長い時間がかかる、しかもいつ手元に来るのかは全く分からないという状況だと、予算の管理に大きな負担が生まれます。
さて、データが届いたあとはいよいよハンドリングですが、残念ながらNDBはハンドリングにも非常に高い壁が存在します。
データを解析するためには、厚労省が定める基準に則った解析部屋を構築しないとならないのです。
そして、提供されたNDBは必ずこの解析部屋の中のみで扱い、原則として外に持ち出すことはできません。
小規模な研究室や小さな企業にとってはNDBハンドリングのためだけに部屋を確保し、厚労省の基準に則り管理するというのは大きな負担になるでしょう。
そうした方向けにオンサイトリサーチセンターといい、厚労省指定の情報セキュリティが講じられた施設が準備されています。
しかし全国に3か所のみであり、地方に住む研究者にとっては利用は容易ではありません。
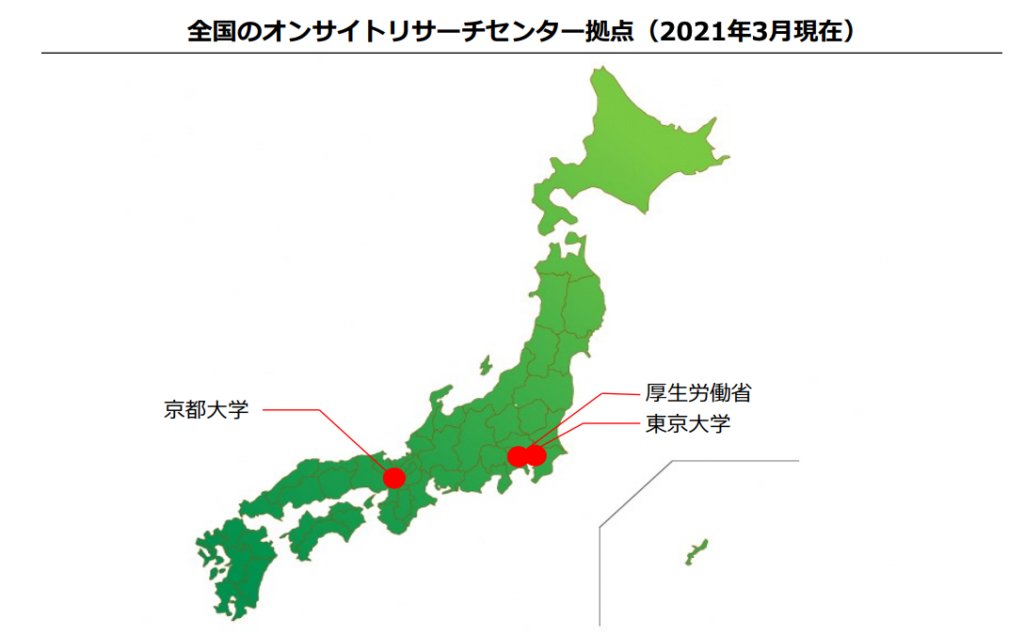
また、オンサイトリサーチセンターを利用するためにも条件があり、NDBの取扱者のうち1人以上は
- 第三者提供の個票抽出の利用経験を有する者
- SQLの知識を持ち、csvファイルをEXCELファイル等で加工できる者
という初心者にとってはキツイ縛りがあります。
終わりに
さて、今回は厚生労働省が運営するNDBをご紹介しました。
NDBは魔境です。
厚生労働省が絡んでいる分、気づいてか気づかずか不適切利用をしてしまった場合には、あなた自身やあなたの所属する研究機関に対して致命的なダメージが生じる恐れがあります。
NDBを扱う時には、厚労省側の書類を穴が開くほど何度もなんども読み返し、そして必ずNDBの申請・ハンドリングの経験が豊富な方と共同で研究をするようにしましょう。
他のデータベースはこちらで紹介しておりますので、あわせてご覧ください。
こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]

こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]
こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]

すきとほる疫学徒からのお願い
本ブログは、読者の方が自由に記事の金額を決められるPay What You Want方式を採用しています。
「勉強になった!」、「次も読みたい!」と本ブログに価値を感じてくださった場合は、以下のボタンをクリックし、ご自身が感じた価値に見合うだけの寄付を頂戴できますと幸いです。
もちろん価値を感じなかった方、また学生さんなど金銭的に厳しい状況にある方からのご寄付は不要です。
引き続き情報発信していく活力になりますので、ぜひお気持ちに反しない範囲でご寄付をお願い致します!






