

こんにちは、すきとほる疫学徒です。
アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。
私が観測できている範囲でも、使用可能な医療DBが日にひに増えてきており、医療DB研究を行う研究者には、「使用可能な医療DBを把握し、それぞれの正しい使いどころをアセスメントする能力」が求められるようになってきました。
そのような医療DBの乱立の中で、日本薬剤疫学会をはじめとし、いくつかの機関、研究者が主だった医療DBの概要を説明してくださっております。
こちらの記事では「もう一歩進んだ医療DBの理解を」をテーマに、それぞれの医療DBがどのようなリサーチクエスチョンと相性が良いかということを、具体例を添えて実践的に説明していきたいと思います。
なお、医療DBの運営者、設立年、サンプルサイズ、母集団、収集されている項目などの基礎的な情報には触れませんので、それらの情報は以下の日本薬剤疫学会による日本で使用可能な医療DBのまとめをご参照ください。
https://sites.google.com/view/jspe-database-ja2020/%E3%83%9B%E3%83%BC%E3%83%A0
・DeSCデータベースを使った代表的な論文

「RWD研究の支援をしてほしい」というご相談を多くの企業様から頂戴するので、企業様向けに正式に窓口を設置しました。
以下のアドレスに連絡頂ければ私に直通しますので、「1時間の無料相談」も含めてお気軽にご連絡ください(3営業日以内にお返事させて頂きます)。無料相談は大変ご盛況となっており、先着順にて対応させて頂いております。
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
私が経営するmMEDICI株式会社ではRWD利活用支援を事業の柱の一つとしており、以下の強みを有しています。「企業の」RWD研究においては日本トップクラスの解像度と経験値を有する自信がありますので、ぜひ無料相談でご体験くださいませ。
- 元大手外資の日本・グローバル出身の疫学専門家が全案件を担当するので、「企業の」RWD研究に高い解像度を有しています
- ただ成果物を納品するだけでなく、グローバルやKOLとの合意形成、社内プレゼン、規制当局対応などRWD研究の「プロセス」も全てまきとれます
- 企業のRWD研究を幾度となく経験しており、企画立案から論文化までの全フェーズを一気通貫で対応できます
- アカデミアのRWD研究者と広い繋がりを有しており、必要に応じた専門人材のアサインが可能です
- RWD研究だけでなく、事業立案、マーケ、広報、営業などのRWDビジネスも全て対応可能です
以下に私の実績を記載させて頂きます。
- 大手外資製薬2社にて、部門唯一の疫学専門家として活動をリード
- 「RWDビジネスの教科書」の書籍を出版(サイドバーをご覧ください)
- 企業でのRWD研究の経験は50本以上
- 製造販売後データベース調査のリード経験多数
- これまで製薬、CRO、コンサル、総合商社、ヘルステックなど10社以上の企業のRWD研究・RWDビジネスを支援
- 50組織以上にRWD研修を提供
- 全体統括・講師を勤めたJapan RWD Summitでは初回から約1,700名の集客を実現
無料相談では、以下のような内容を含め企業様の「RWD」と名のつく相談でしたら全て対応させて頂きます。
- このテーマでRWD研究はできるの?
- RWD研究っていくらくらいかかるの?
- RWD研究ってどんなプロセスでやれば良いの?
- 製造販売後データベース調査のやり方を教えてほしい
- RWD研究をするにはどんな専門家を雇えば良いの?
- 自社のRWDサービスを売りたいんだけど、強みはどこ?集客はどうすれば良い?
無料相談は先着順での対応となりますので、ご希望の企業様はぜひお早めのコンタクトをお願い致します!
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
データベースの説明
本日は、DeSCデータベースを紹介します。
詳細は後ほど語りますが、DeSCデータベースの誕生はReal World Dataを扱う人間にとっては一つの革命でした。
つい先日、DeSC社さんが自社ページで発表していましたが、DeSCデータベースを使った研究が異なる3つの学会で同時期に受賞されたそうです。

この業績からも、DeSCデータベースのポテンシャルの高さが伝わってきますね。
さて、そんなDeSCデータベースは、株式会社DeSCによって収集、運用されている診療報酬請求データベースです。
診療報酬請求データベースは保険者から収集される保険者データベースと、医療機関から収集される医療機関データベースに2分されますが、DeSCデータベースは前者に該当します。
同じ保険者データベースにはJMDCデータベースが存在しますが、DeSCデータベースはJMDCデータベースと大きく異なる特徴を有しているんで、その差分を意識しながら記事をご覧いただくとより理解が進むと思います。
JMDCデータベースの説明はこちら。
こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]

さて、保険者データベースですが、その内容は「どの種類の保険者からデータを集めているか」ということで特性が極めて大きく変わります(だからデータベース研究をやるには保険医療制度の理解が必要なんですね)。
日本には大きく分けて以下の3種類の保険者が存在します。
- 社会保険:会社員およびその被扶養者
- 国民健康保険:自営業や未就業者など健保に加入していないすべての人
- 後期高齢者医療制度:75歳以上のすべての人(一部65歳以上で一定の障害を抱える人)
少しデータが古いですが、以下は平成29年に厚生労働省が発表した保険者間の加入者属性の比較です。
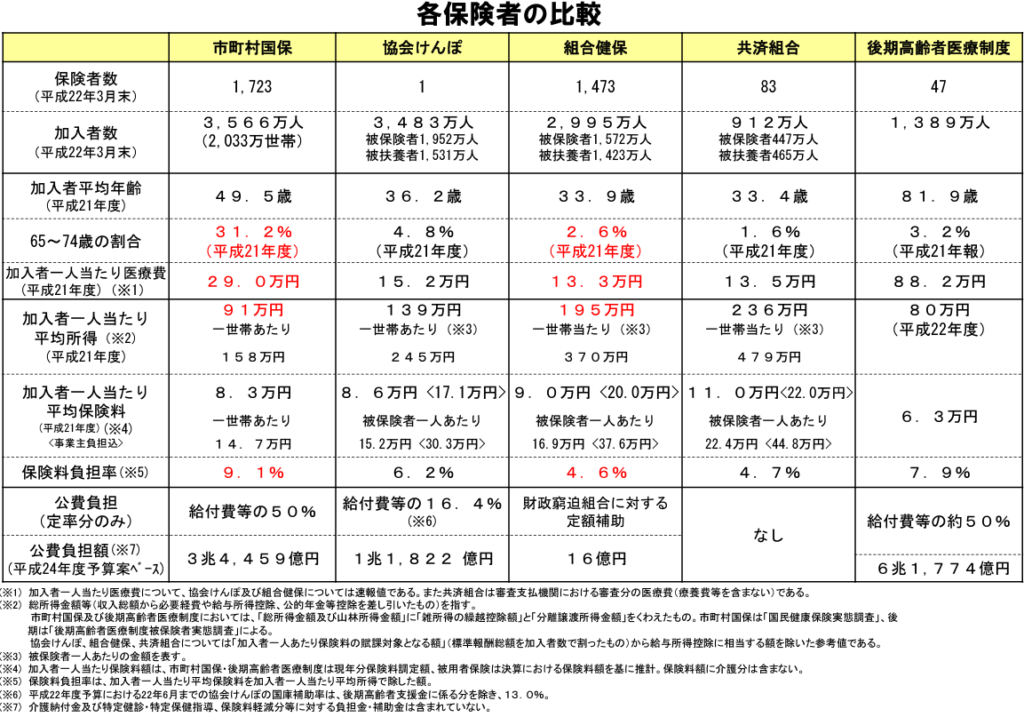
左から
市町村国保:国民健康保険
協会けんぽ、組合健保、共済組合:社会保険
後期高齢者医療制度
です。
ご覧の通り、当然ながら加入者の年齢は後期高齢者医療制度が圧倒的に高く81.9歳、次いで国保、そして健保となっています。
また、特筆すべきは加入者一人当たりの平均所得の差であり、社会保険の加入者が最も高く、次いで国保、そして最後が後期高齢者医療制度となっています。
これが何を意味するのか。
年齢や社会経済的状況に応じて疾患分布や罹患時の重症化率は変わりますので、どの保険者から集めたデータかに応じてターゲットにできる疾病や医療行為が変わり、またそれらの因子が効果修飾因子となる場合には曝露・アウトカムの間の因果関係も変わります。
この図はそれぞれの保険者ごとの年齢や疾病特性を表したものです。

というわけですから、医療大規模データベース研究をする際には「どのような集団からデータを集めているのか」、「そしてその集団における疾病や医療行為の特性はどのようであるか」ということを、一人一人の患者さんの息遣いが聞こえてくるようにリアルに想像せねばならないんですね。
さて、保険者データベースの一般的な解説が終わったところで、DeSCデータベースの特徴の解説に入っていきましょう。
データベースの特徴
概要
- サンプルサイズ:1,500万人*
- 収集データ:各種レセプトデータ、加入者台帳データ、特定健診データ(一部対象者)、ライフスタイル(QOL、WPAI、HLなど/一部対象者)、PRO(歩数など/一部対象者)
- 対象保険者:社会保険、国民健康保険、後期高齢者医療制度
- 収集期間:
*ミクスOnline記事より引用. 2022年5月12日. https://www.mixonline.jp/tabid55.html?artid=73021
そういえばの余談ですが、DeSCはDeNAの子会社です。
データの悉皆性が高い
他のデータベースにはないDeSCデータベースの最大の魅力、それはなんといっても悉皆性の高さです。
ここで言う悉皆性の高さというのは、「日本全体を母集団とした際、データベース内の対象集団がどの程度その母集団を代表することができるか」ということですね。
概要でも書きましたが、DeSCデータベースは主たる保険者種別である社会保険、国民健康保険、後期高齢者医療制度の全てからデータを集めています。
現時点でこれが行えているのはDeSCデータベースのみであり、私はDeSCデータベースの誕生は日本の医療データベース研究界における一つの革命であったと感じています。
悉皆性と言えば当然ながら厚生労働省が運営するNational Databaseが最大を誇るわけなので(ほぼ日本国民全体)、それ以外のすべてのデータベースは悉皆性と言う点ではNDBに及ばないと言えばそこまでですが、NDBには①データ提供まで1年、②管理プロセスが超複雑、③クリーニングされてないのでデータが超汚い、という圧倒的な不都合もありますので笑。
NDBの解説はこちらです。
こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]

では、DeSCデータベースの悉皆性の高さをデータで見てみましょう。
以下は、国民健康栄養調査とDeSCデータベースにおいて非感染性疾患の有病割合を比較した研究です(余談ですが、DeSCデータベースが有病割合を計算できているのは分母に当たる”疾病を有さない人も含めて全対象集団”のデータを得られているからであり、これは保険者から加入者台帳を入手できているからこそ実現できることです。詳細はJMDCデータベースにおいて記載済みなので、そちらをご覧ください)。

こちらの図は日本国民全体の年齢分布とDeSCデータベースの年齢分布を示しています。
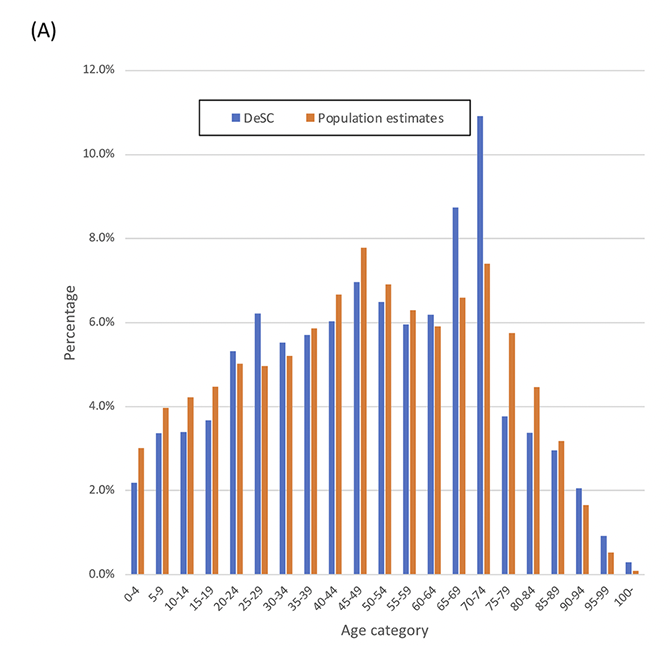
ご覧の通り、日本国民の年齢分布とDeSCデータベースの年齢分布が比較的重なっていることがわかります(DeSCデータベースで前期高齢者の年齢が高いのは、国保からのデータが多くなっているからと考察されています)。
こちらの図は、日本国民全体(NHNS:国民健康栄養調査)とDeSCデータベースで年齢別に糖尿病および高血圧の有病割合を比較しています。
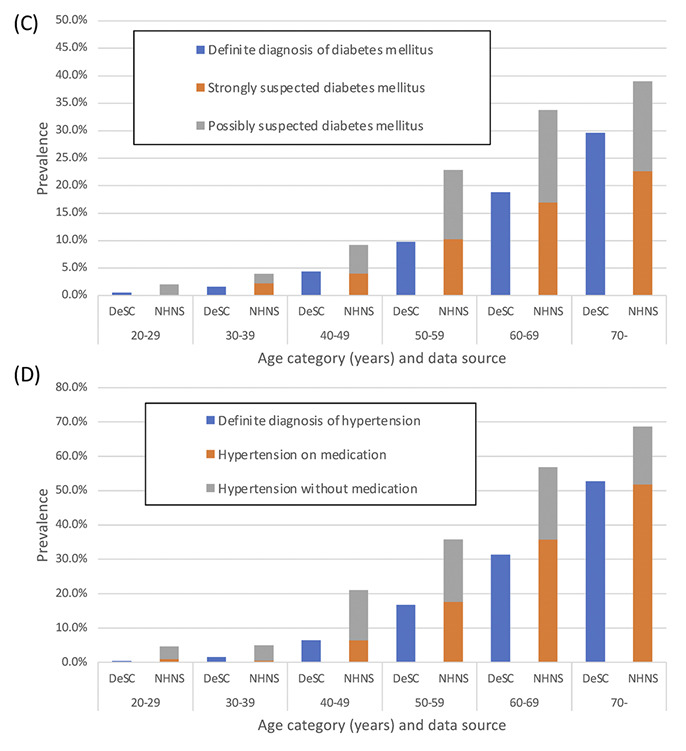
ご覧の通り、NHNSの有病割合をオレンジの”強く疑われる糖尿病”および”治療を受けている高血圧”に限れば、青バーで示されるDeSCのそれと極めて割合が類似することが見てとれます。
DeSCデータベースはレセプトデータですので、「治療を受けていない糖尿病、高血圧」は疾病として拾い上げられません。なので、NHNS側のデータを「治療を受けているであろう糖尿病または高血圧」に限定して割合を比較することは合理的です。
データベース研究に親しんでいる人であれば、この図を見た瞬間に衝撃が走るでしょう。
それほどまでに、データベース研究で悉皆性を確保するというのは困難だったのです。
せっかく苦労して研究しても「でもそれ、急性期病院だけでの話でしょ?」と言われてしまうとちょっぴりがっかりですから(もちろんそれでも意義のある研究は山ほどありますが)。
そうした困難に日々打ちひしがれるなかで出てきたのがDeSCデータベースだったのであり、だからこそ「革命」と表現したのです。
ちなみにこちらは冒頭で紹介したDeSCデータベースを使った研究で学会受賞をされた先生からのコメントですが、こちらのコメントでも母集団を想定した研究を行うことの重要性が説かれていますね。

前向きのデータ収集が可能である
DeSCデータベースは保険者から集めるレセプトデータに加えて、Kencomというアプリを通したライフログデータ収集や質問紙調査を行っています。保険者を通してKencomアプリを被雇用者に導入してもらい、アプリデータとレセプトを紐づけるわけです。
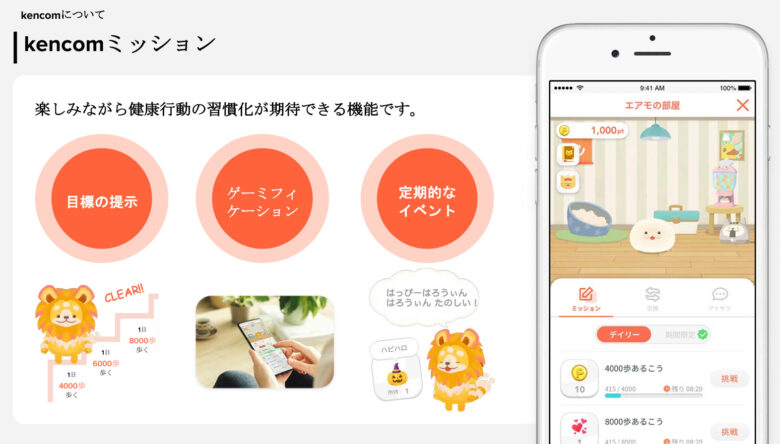

さらっと書いてますが、これもまた革命の一つです(JMDCもPepupというアプリを使って同じことを実現しています)。
過去のデータベース研究というのは「レセプトのデータ、つまり既に集められているデータで研究するしかない」世界でした。つまり、配られたカードで勝負するしかなかったわけです。
ところが、Kencomアプリを通して前向きにデータ収集が行えるようになったことで、「カードを創造して手札を強化する」みたいなウルトラCができるようになったわけですね。
データベース研究が持つ可能性の扉が、大きく開いたんですよ。
ただ、この前向きデータを使う上ではいくつか注意点があります。
まず、まだまだサンプルサイズが少ないということ(下図参照)。

また、Kencomアプリは健保の被保険者のみに配布されており、さらに”ちゃんとデータを入力してくれる人”に対象者が限られてしまうので、特異な集団の結果を見ている可能性があります。選択バイアスも考慮せねばなりません。
ちなみにこの機能を使った論文がこちら。

これまで、日本における偏頭痛の疫学データは十分なものがなく、また偏頭痛がある人の70%近くが医療機関を受診していないことから、その全体像は不明なままでした。
医療機関を受診しなければレセプトには登場しませんので、レセプトデータだけでは片頭痛の全体像を知る疫学データを記述することはできません。
そこで「医療機関を受診しない人も登録される保険者データベースであるDeSCと、Kencomeの前向き調査機能」を使って、片頭痛の疫学データの記述を試みたのが本論文です。
こちらは患者特性を記述したTable。
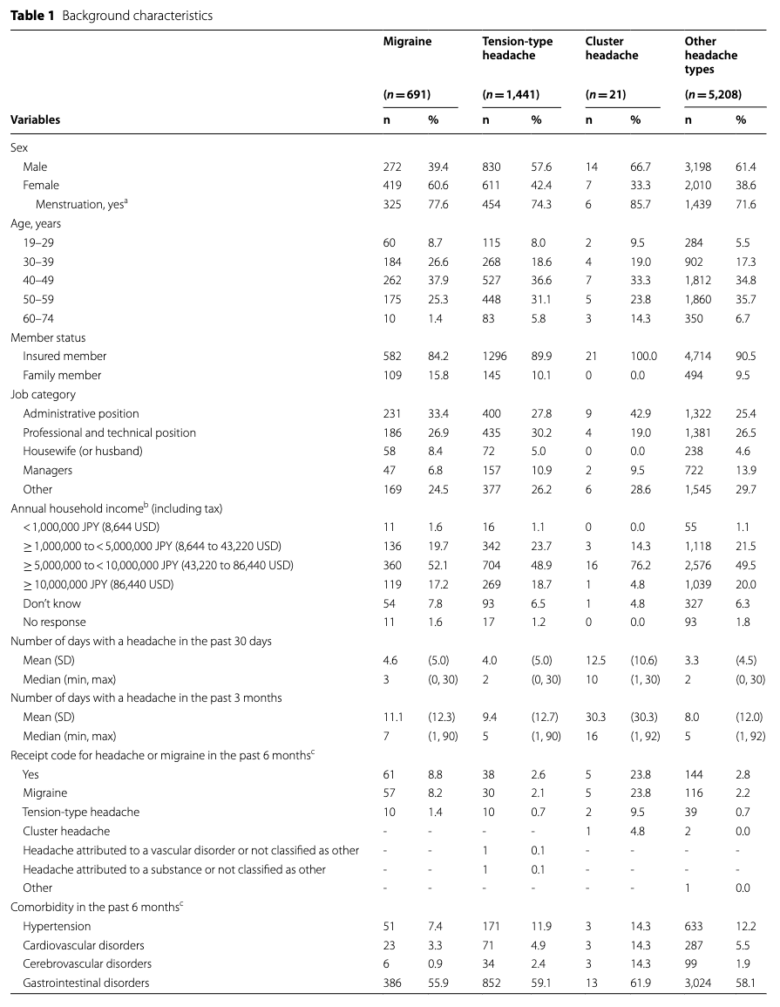
ご覧の通り、次のような通常の医療大規模データベース研究では登場しない変数も入手できているのがわかります。
- Job category
- Annual household income
いわゆる社会経済的ステイタス(SES)に関する変数ですが、SESは疾患特性や、治療とアウトカムの因果関係に影響する可能性が高く、疫学研究においては極めて重要な変数です。
しかし、日本の医療大規模データベースではSESを入手できるものがなく、研究者にとって大きな悩みの種でした。
ですから、上記のTableではサラッと書かれているだけですが、医療大規模データベース研究でありながらSESが入手できているというのは非常にインパクトの強いことなんです。
そしてこちらのTableは片頭痛に関する医療利用実態を記述しています。
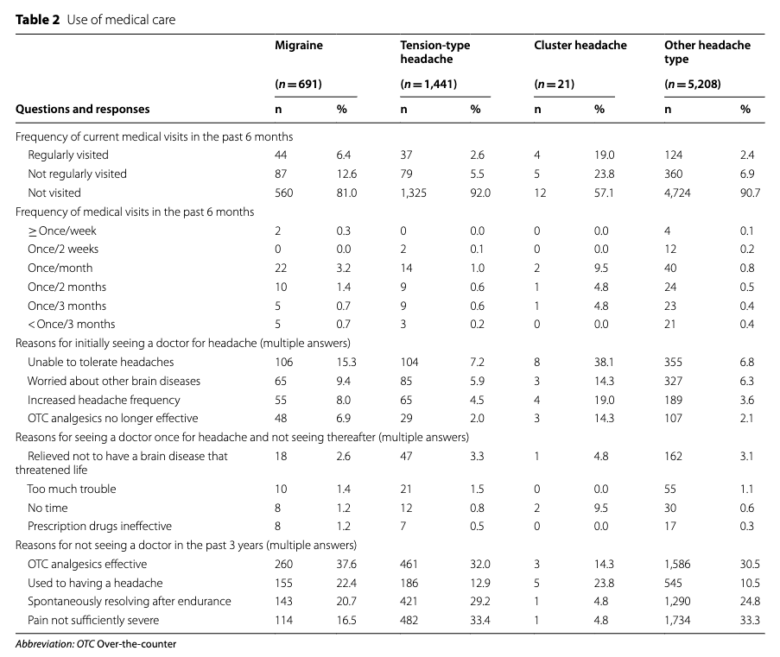
こちらでも「レセプトだけでは知り得ない情報」がてんこ盛りになっていますね。
見るべきは一つ目の変数の「Frequency of current medical visits in the past 6 months」です。
ご覧いただくと、80-90%の患者が「Not visited」を選択していますね。この患者、すでにお伝えした理由からレセプトだけでは全て見落とされます。逆に言えば、DeSCデータベースだからこそ拾い上げられた患者達です。
ふだんレセプトデータベースをつかった研究をしている人にとっては、この一変数だけでも衝撃をもたらすには十分な情報でしょう。
そして最後にこちらのTableは片頭痛の疾病実態ですね。
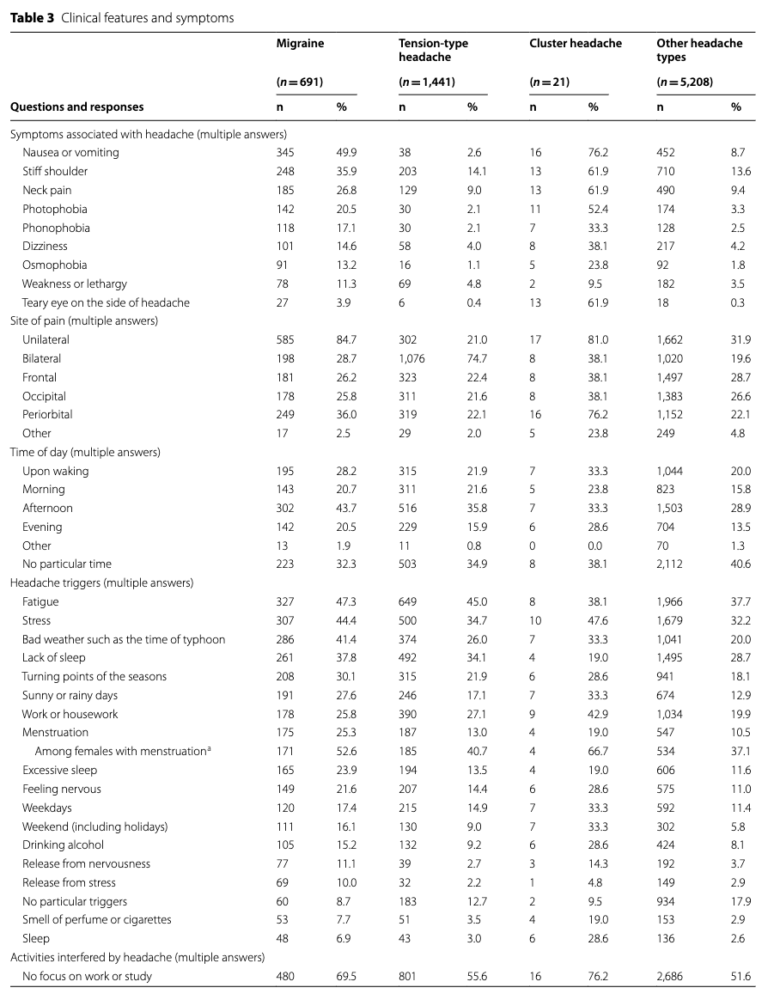
こちらもレセプトでは知り得ない情報がたっくさん。
片頭痛の随伴症状、場所、時間、頻度、きっかけなどですね。レセプトデータでは”疾病の有無”しかわかりませんでしたので(DPCデータの様式1では一部疾患の重症度が入手可能ですが)、こちらも驚愕です。
もちろん、Kencomeアプリから入手されるデータは”回答を入力した患者だけのデータ”なので、その集団特性や選択バイアスの影響には極めて慎重な解釈が必要なことはお伝えしておきます(それでも素晴らしい!!!)。
高齢者の施設間データがとれる
既にお伝えしたように、DeSCデータベースは後期高齢者制度からのデータ収集も行っているため、75歳以上の高齢者のデータが存在します。
保険者データベースで75歳以上の高齢者のデータが使えるのって、めっちゃくちゃ大きいんですよ。
これまで高齢者を扱えるデータは各病院から収集したレセプトで構成される病院ベースのデータベースだけでした(ナショナルデータベースは除く)。
そして、この種のデータベースは施設間での患者追跡ができません。
要は、A病院がデータベースに含まれている施設だとしたら、それ以外のB病院、Cクリニックで患者が治療を受けていたとしても、それは全部無視されるということです。
これ、疾病のある高齢者をターゲットに研究する際には大問題なんですよ。
だって、疾病のある高齢者なんて、2件、3件で通院治療を受けているとしても全然不思議じゃないですよね?
「治療薬X vs Yで骨折の発症リスクを比較する」という研究をする時、もしかしたらデータベースには含まれたないB病院で治療薬を投薬されてるかもしれないし、骨折の診断を受けているかもしれない。
「A病院でしか治療薬XもYも投薬されないし、骨折も診断されない」ってかなり無理な仮説じゃないですか?
でも、病院ベースのデータベースを使うというのはそういう非常に強い仮説を受け入れるということなんです(もちろん、状況設定によっては病院ベースのデータベースでも妥当性の高い研究をすることも可能です)。
そこで彗星の如く現れたのがDeSCデータベースです。
お伝えした通りDeSCデータベースは保険者データベースですから、施設を超えて患者を追跡することができます。クリニックも含め、です。
ただ一点注意が必要です。
それは、DeSCデータベースでは保険者間のデータの結合ができないということ(これは全ての商業データベースの課題ですが)。
つまり、健保→後期高齢者制度のように患者が保険者を移行した際には、そこでデータの追跡が途切れます。
逆に、後期高齢者制度の方の保険者がDeSCデータベースでカバーされている保険者だった際には、75歳になっていきなりデータベースに現れる対象者がいるということですね。
となると、75歳前後で発症するような疾患に対してはDeSCデータベースは使いにくいということになります。追跡がそこで途切れてしまうかもしれないし、また75歳以前の状況が全くわからないので看護師数が調整できないということも生じ得ますね。
公募形式でデータベースを無料提供している
こちらはサイエンスではなく、DeSCデータベースを運営するDeSC社の心意気への感動です。
DeSC社は、アカデミアからの公募形式でDeSCデータベースを無料提供しています。

もちろん、設立まもない中で、活用事例を増やして競争力を強めていくというビジネス上の戦略があることは理解しますが、それでも無料提供ですよ⁈
血を流すような苦難をしながら収集し、そしてクリーニングしたであろうデータベースを無料提供しているわけです(余談ですが、企業の方々はデータベースのクリーニングに対する意識が低すぎるきらいがあります、自分で解析しない方が多いからでしょう)。
これによって、「予算がなくって、普段データベースに触れる機会のない研究者」にとっても医療大規模データベースに触れる機会が生まれました(公募に通る必要があるにしても)。
そして、そんな研究者が行った研究によって救われる人々がいるかもしれません。
これは、単なるビジネス戦略という小さな視座を通り越して、私は「日本の公衆衛生そのものへの貢献である」と感じています。
このような取り組みは、正しく伝わり、評価されるべきです。
私の知る限りにおいて、ここまでの規模のデータベースを無料提供している会社はDeSC社以外には存じ上げません。
私はこれまでの経験から、医療大規模データベースの質は、それを運営する会社のサイエンスへの態度に影響されると考えていますが(良いものも悪いものも実例いっぱいありますが、あえて言語化しません)、だからこそ私はDeSCデータベースに強い信頼感をもっています。
感動した論文例
年間の平均歩数と循環器疾患のリスク因子との関連

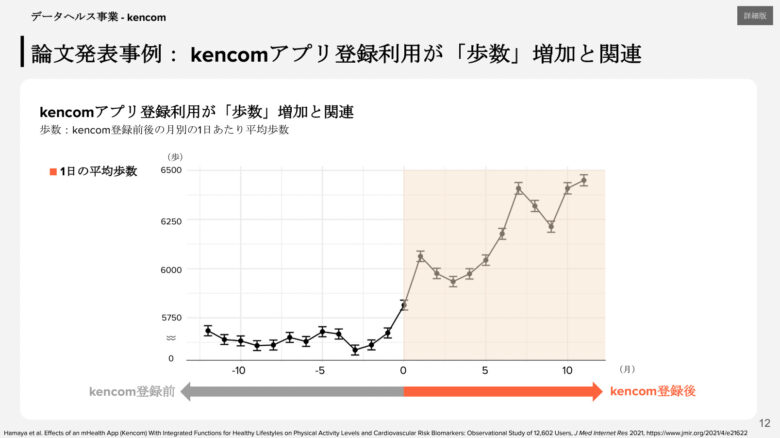
この論文が素晴らしいのは、DeSCデータベースという新たなデータベースの魅力を最大限引き出し切っている点です。わたしが去年読んだ論文の中で最も感動した論文でした。
まずイントロダクションが素晴らしい。
わずか2パラグラフでこの研究の新規性と強みを明確に伝えています。
歩数と循環器疾患の関連を調べた研究は過去にも存在しましたが、それらの多くが7日間のように短期間の歩数だけを調べており、真の歩数をきちんと測定できているか疑問がありました。それに対し、Kencomeアプリを入れたスマートフォンを使って歩数を測定することで、より日常に即した、かつ長期の歩数を測定できることを本研究の強みの一つとしています。
イントロダクションから「勝てるデータベース研究」の香りがムンムン漂ってきます。
何度も書いていますが、データベース研究というのは「データがあるからやってみよう」ではなく、「このデータでしかできないからやろう」というオンリーワンの位置付けができなければやってはならないのです(1年間の歩数をランダム化で振り分けて介入なんて絶対無理、観察研究しかできない)。
「データがあるからやってみよう」はほぼ間違いなく爆死します。
次なる感動ポイントは、研究成果の実社会への還元についてです。
筆者ら自身も研究の強みとして書いていますが、「スマートフォンで記録した歩数」を曝露に使うことで、誰でもスマホさえあれば測定できる現実的なデータを用いた研究となっています。
それにより、「Public Health上の推奨への繋げやすい研究」となっているわけです。
Public Healthは「社会の役に立つことを至上命題とした実学」ですから、研究も「その研究が同社会の役に立つのか」という痛烈な眼差しによって評価されなければなりません。
これは、研究者の科学的知見というよりも、疾病や公衆衛生への向き合い方がより色濃く反映されるポイントだと思っています。
だからこそ、私はこの論文を読んだ時に感動し、そして私自身も「こんな研究をしなければならないな」と胸を打たれました。
最後の感動ポイントは、すでにお伝えしたとおりDeSCデータベースというデータベースの強みを隅々まで使い尽くしていること。
曝露を長期間に測定された歩数にしている点もそうですが、アウトカムとして循環器疾患のリスクとなる様々な測定値を設定しています。
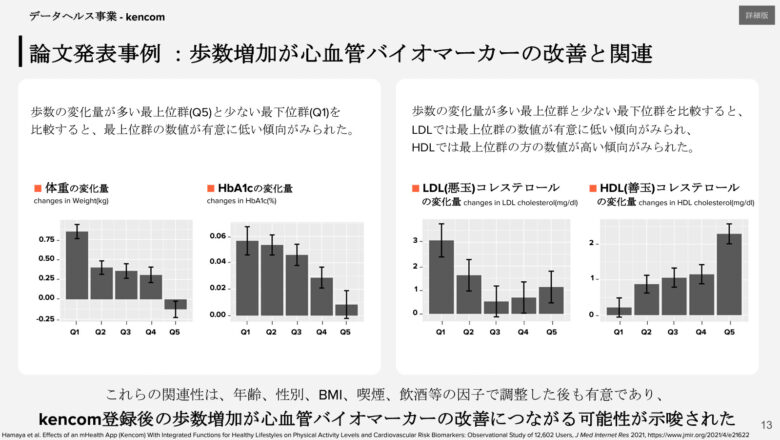
以下はその一部です(つーかめっちゃ綺麗に結果が出てますよね、これ気持ちいいだろうな)。
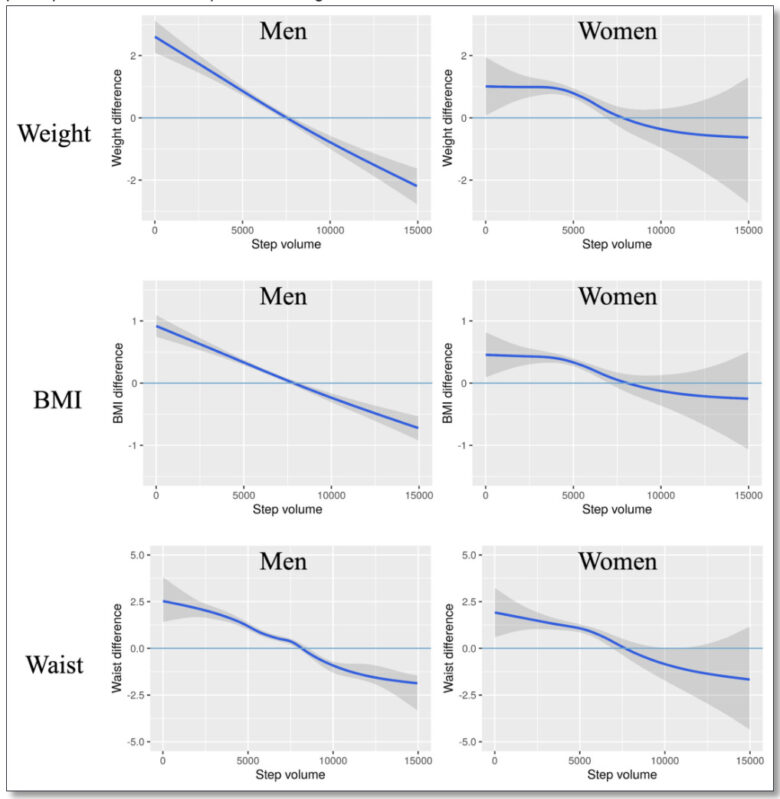
他にも、収縮期・拡張期血圧、HDL・LDL、トリグリセリド、空腹時血糖、HbA1cをアウトカムとし、それぞれと歩数との関連を調べています。
「レセプトデータなのに検査値が入ってるの?」と思う方もいるかもしれませんが、これは特定健診のデータを使っています。「特定健診って何?」って方はこちらの「特定健診のデータがある」のセクションをご覧ください。
こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]
Covid-19のパンデミックとICU入院患者の家族における精神疾患の発症の関連

論文でなくレターの紹介です。
かねてより、「患者がICUに入院したこととその家族の精神疾患の発症の因果関係」を調べた論文は日本から発表されていました。
今回は、「患者のICU入院の有無」という曝露に加えて、「コロナのパンデミック前後」という曝露も加えることで、上記の因果関係がコロナのパンデミックによって修飾を受けるかどうかを調査しています(Dirreference-in-Differenceです)。
この研究もイントロダクションが魅力的で「コロナで家族が病院を訪れられなくなったし、医者ともなかなか面会できなくなった、それが家族のメンタルヘルスに影響してるかもしれない(でも先行研究は比較群がなかった)」という仮説で研究テーマの妥当性・新規性を主張しています。
臨床の疑問に根差したリサーチクエスチョンであり、コロナのパンデミックという過酷な状況下でも真摯に臨床で患者さんに向き合ってきたからこそ生まれたリサーチクエスチョンだと感じます。
先ほどもお伝えしたとおりPublic Healthというのは社会に役立つことを前提とした実学ですから、本研究のように強烈に患者さん、社会の存在を感じさせる研究がわたしは大好きですし、感銘します。
なお研究結果は以下の図のように、コロナのパンデミックによってICU入院患者の家族の精神疾患の発病割合が有意に増加したとして、研究の仮説を支える結果となったそうです。
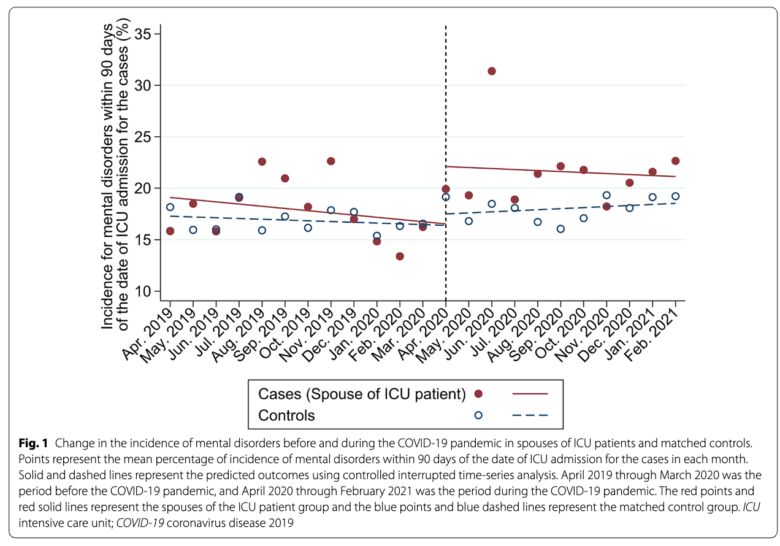
ちなみに本研究の前日譚となる研究がこちらで、これはJMDCを使って行われています。
本研究の著者も共著者に入っていまして、こっちは論文なのでより詳細な方法論が書かれていますから、気になる方はぜひどうぞ(JMDCデータベースの記事で触れてるのであえて言いませんでしたが、家族間結合ができるというのもDeSCの強みの一つです)。

終わりに
他のデータベースはこちらで紹介しておりますので、あわせてご覧ください。
こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]

こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]
こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]

こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]
終わりにその2
私は外資系企業と国立大学の疫学専門家として活動しておりますが、それ以前はブラック企業に勤める社畜として上司に怒鳴られる日々を送っていました。
「強く生きるには専門性だ」
そう一念発起し、大学院の修士課程に通い、そこから2年間で疫学専門家としてのキャリアにルートインし、2年で年収を1,400万アップさせることができました。
こちらのnoteでは、疫学の世界で活躍したいと考える方々に向けて、「専門性ゼロの段階からどうやって企業の疫学専門家のポジションをゲットするか」ということを解説します。
私自身が未経験から2年間で外資系企業の疫学専門家になるまでに積み重ねた経験、ノウハウの全てをお伝えするつもりで書き綴っています。
「これを読めば、企業の疫学専門家になるために必要な知識は全て揃う」
その気合いで、私のノウハウを全てお伝えします。
すきとほる疫学徒からのお願い
本ブログは、読者の方が自由に記事の金額を決められるPay What You Want方式を採用しています。
「勉強になった!」、「次も読みたい!」と本ブログに価値を感じてくださった場合は、以下のボタンをクリックし、ご自身が感じた価値に見合うだけの寄付を頂戴できますと幸いです。
もちろん価値を感じなかった方、また学生さんなど金銭的に厳しい状況にある方からのご寄付は不要です。
引き続き情報発信していく活力になりますので、ぜひお気持ちに反しない範囲でご寄付をお願い致します!



