

こんにちは、すきとほる疫学徒です。
【初心者のためのRで医療ビックデータ解析】シリーズは、「これまでデータの解析を行ったことがない人」を対象にして、Rで医療ビックデータを解析する方法をわかりやすく解説していきます。
全てのシリーズを受講し終えた時点で、「診療報酬データやレジストリーといった医療大規模データを、自立して解析できる」状態になることを目指しております。
全研究者、Rユーザー化計画、ここに始動す。
Rとは? Rを使うメリットは何か?
R、正確にはR言語とはオープンソース、かつフリーソフトウェアの統計解析向けのプログラミング言語です。
研究者がデータ解析を行うツールとして、R以外にメジャーなものとして、SPSS、Stata、SAS、Pythonなんかがありますね。
ではなぜ私がRを使っているからというと、以下のような強みがあるからです。
①無料である
私が初めて医療大規模データの解析を行った際、指導者から幾つかの選択肢を提示されたのですが、一切迷うことなくRを選択しました。
なぜなら無料だから。
これが、私がRを愛する理由の一つ目です。
SPSS、Stata、SASは数万〜十数万ほどの初期費用がかかります。
もちろん、無料であれば良いというわけではなくって、「安かろう悪かろう」じゃないの?という心配の声もあるかもしれません。
でもご安心ください、次のチャプターで説明しますが、Rは世界で最も多く使われる解析ツールの一つであり、Rでデータ解析を行なった論文は、数多く一流誌に掲載されてきました。
だから、決して「Rは無料だから、信用ならないんだ、粗悪な解析ツールなんだ!」ということはございません。
私自身は、大学院在学中はSPSSやStataなど、研究室で契約している有料の解析ツールを使うこともできたのですが、卒後のことを考えると最も維持コストがかからない解析ツールがベストだと考え、Rを選択しています。
②世界的に使われている
こちらは、2016-2021年にPubMed Centralに掲載された学術誌のうち、ランダムにサンプリングされた76,147編において使用された解析ツールのランキングです。
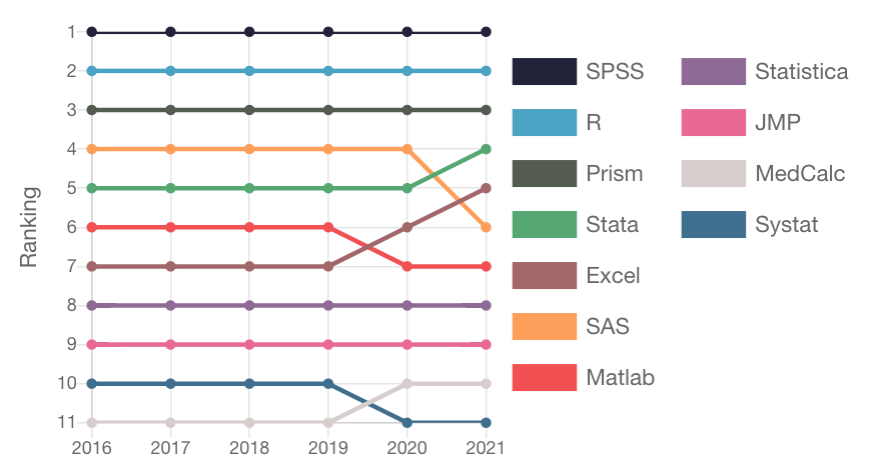
トップ3は6年間変わらず、
- SPSS
- R
- Prism
となっていますね。
SPSSが人気なのは、その操作性の簡便さ故でしょう。
RやStataといったプログラミング言語と違い、SPSSは選択肢をポチポチするだけで解析を実行してくれます。
なので、プログラミングの知識がない初心者の方には使いやすいんですよね。
その代わり、ロードが遅い、データセットの修正が面倒、可能な解析に限りがあるなどのデメリットがあります。
医療大規模データに慣れるために、初心者が最初の研究をSPSSで行うのはとても良いと思うのですが、2本目以降はSPSSではなく、RやStataといったプログラミング言語を使用した方が、より快適に解析を実施することができると思います。

こちらも同じ記事からの紹介ですが、先ほどのグラフを数値化したものです。
SPSSが約41%と大半を占めており、Rは約20%ですね。
しかしながら、6年間のトレンドを見ると、SPSSの人気がやや下がっており(-1.43%)、その代わりRの人気が微増していることが見て取れると思います(+1.29%)。
このように、Rが医学領域の研究において最も使われている解析ツールの一つであるということがお分かり頂けたかと思います。
そのため、巷にはRの使い方を解説した書籍が溢れていますし、また疑問があるときも、少し検索すればだいたいネットで誰かが解説してくれています。
エラーコードが出て解析が回らないときには、私はいつもそのコードをコピペしてググるのですが、するとR版知恵袋みたいなところで同じ質問に対していくつも掲示板が立っていることがほとんどです。
そのうちどれかが欲しい答えをくれるんですね。
こんな感じで質問を投げている掲示板があり、
こんな感じで世界中の親切なRユーザーが回答してくれます。
知恵袋みたいに回答欄が地獄絵図になることはなく、どなたも親切かつ丁寧なのでご安心ください。
また、複数の研究者で共同研究を行う際にも、チーム内の研究者が共通して使える解析ソフトがあれば、いちいちコードを修正したり、データのフォーマットを変換する必要もありませんよね。
Rの普及率の高さを考えれば、チームの研究者の何人かはRを使えるという状況も起こりやすく、コミュニケーションがとりやすくなります。
それに、世界のあちこちで誰でも参加できるRのコミュニティが発足しており、簡単に切磋琢磨する仲間を集めることができます。
例えば、日本で有名なのですと、こちらのTokyo.R。
毎週勉強会を開催しています。
また、Tokyo.Rはslack上でコミュニティを運営しており、初心者が質問を書き込むと、コミュニティ内の親切な先輩たちが一瞬で回答してくれます(私も質問したことがあるのですが、2分で3件くらい回答が集まり、コミュニティの凝集性の高さにビビりました。。。)。
Tokyo.R以外に私のおすすめは、こちらのTidytuesdayというR visualizationを学ぶための世界的なネットワークです。

Tidytuesdayでは、毎週火曜日にデータセットがオンラインで配布され、それを元に世界のRユーザーたちが”イケてる”グラフを描いて、Twitterでシェアします。
こんな感じに↓
グラフを作るために書いたコードもシェアしてくれるので、これを見れば誰でもイケてるグラフの描き方が、無料で学べちゃうっていう寸法ですね。
これらは世界に溢れているRコミュニティのほんの一角で、探せば本当に多種多様なコミュニティがあるはずです。
こうして世界の叡智を活用できること、それが私がRを推す理由の2つ目です。
③美しいグラフが描ける
StataやSASなどの他の解析ツールと比較し、Rが最も優れていると言われる点は、そのvisualizationスキルにあります。
先ほどのTidytuesdayでも紹介しましたが、Rのパッケージ(後ほど紹介します)を使うと、美しいグラフが本当に簡単に描けちゃうんですね。
もちろん、グラフが美しいからといって中身がしっかりしていなければ意味はありませんが、それでも読む側からしたら見目麗しいグラフの方が嬉しいに決まっています。
せっかくなので、Tidytuesdayで紹介されていた美しいグラフたちを紹介していきましょう。
驚くことに、これからご紹介するグラフたちは、全て同じデータセットからvisualizeされています。
先週のTidytuesdayのお題としてシェアされた「USのスポーツ分野ごとの支出」というデータセットですね。
どうです?
ワクワクしてきませんか?
こういった美しいグラフが、Rを使えば私たちでも描けちゃう可能性があるんです。
描けるようになるまでには、ある程度Rへの基本的な理解が必要かもしれませんが、極論を言えば「正しいコードさえ描ければ、誰でも等しくアウトプットできる」ので、とっても夢のある話だなと思います。
ちなみに、先ほども申したように、Tidytuesdayに関してはそれぞれのTwitterアカウントがコードをシェアしてくれていますので、それをコピペすれば私たちのRでもすぐに同じグラフが描けるはずです。
④便利なパッケージが沢山ある
Rには、パッケージという便利ツールがあります。
パッケージというのは、ポケモンの技マシンのようなものですね。
「こんな解析がしたい」、「こんなグラフが描きたい」と思ったときには、それ専用の技マシンであるパッケージをインストールして、ロードします。
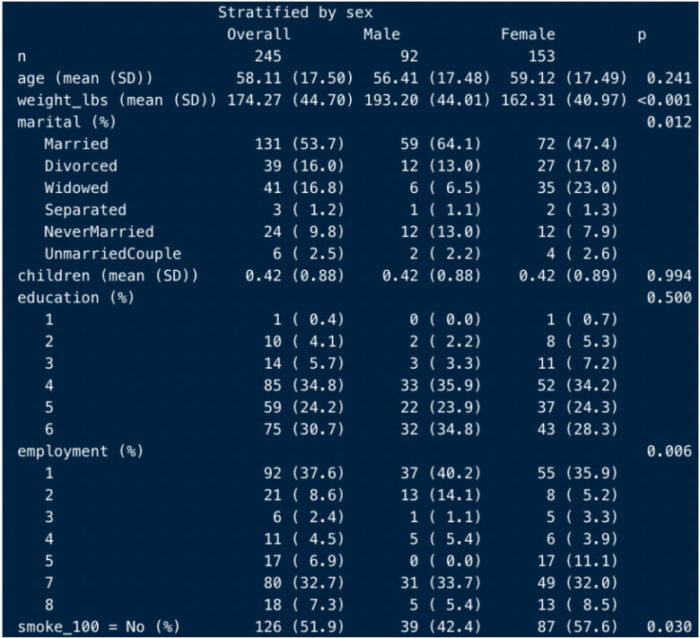
例えばこちらは、先日私がRtipsの記事で紹介した、tableoneというパッケージです。
install.packages("tableone")
library(tableone)
このパッケージを使うことで、「対象者の背景情報を要約したTable1を作成する」という新しい技が使えるようになるんですね。
こうやってコマンドを入力すると、
listvars <- c("age", "weight_lbs", "marital", "children", "education", "employment", "smoke_100")
listcat <- c("marital", "education", "smoke_100")
Table1 <- CreateTableOne(vars = listvars,
factorVars = listcat,
includeNA = T,
addOverall = T,
smd = T,
data = riskfactors,
testExact = fisher.test,
testNonNormal = kruskal.test,
strata = "sex")
こんな感じで、女性・男性別の対象者背景が要約されたTableがアウトプットされます。
さて、冒頭で私が「R言語はオープンソースである」と言ったことを覚えていますでしょうか?
そして、「Rは世界的に使われている」とも申しました。
そうなんです。
Rのスゴいところは、この技マシンであるところのパッケージが、世界中の研究者たちによって日々開発・共有されているところなんです。
誰かが「あ、こんな技をポケモンに覚えさせたいな!」と思ったら、その人がその技専用の技マシンを開発し、そしてそれを世界中のRユーザーが使えるようにしてくれるんですね。
なので、「あー、この解析したいけど、なんか便利なパッケージないかな?」と思ったら、ぜひググってみてください。
だいたいは世界中の親切なRユーザーのうち誰かが既に開発してくれているはずです。
私はこれまでRを使って、何度も国内外のヘルスケア大規模データを解析してきましたが、これまでに「欲しいパッケージがない!」と困った状況は一度もありませんでした。
たとえば、先日私は自分の研究で、”4 way decomposition analyses”という解析手法を使おうと考えていたんですね。
この手法、比較的新しい解析手法ですので、Rで対応しているかどうかがやや不安でした。
そして調べたところ、
ちゃんと開発されてるんですよ。。。
2021年1月23日に完成したようなんですけど、こうして開発者の方が「新しいやつ、できたでーーーー!」ってお知らせしてくれていて。
おまけに、かわいい星の王子様のイラスト付きです。
私はまさかパッケージが開発されているなんて期待していなかったので、このパッケージを発見したときには、あらためて「Rってほんとすごいな、世界のRユーザーに感謝だよ」と心から感動しました。
もちろん、Rはオープンソースですから、いちユーザーである私たちでもこうしたパッケージを開発することができます。
私が所属していた研究室では、Rユーザーの先輩が、日本の医療ビックデータに特化したデータクリーニング用のパッケージを作成してくれており、そのおかげでデータクリニーングがかなり楽になりました。
Rのデメリットは何か?
さて、ここまではRの素晴らしい点ばかりを述べてきましたが、ここからはデメリットについて解説してきます。
①データが大きすぎるとフリーズする
有料の解析ツールであるSASやStataと比べると、Rは扱えるデータのサイズに限界があるように感じます。
例えば、私がDPCデータを使って糖尿病の患者を対象にした研究を行なっていたときのことです。
切り出した直後は、だいたい300万人×200変数くらいのデータだったのですが、Rで読み込んでもほぼ回りませんでした。
ですので、Rに読み込む前にSPSSなどで不要な変数を削除し、そうしてようやくRに入れ込むということをしていました(その時はしらなかったのですが、Rにはデータの読み込み時点で、不要な変数を指定して削除するパッケージもあり、それを使えばもう少し楽にクリーニングできましたね)。
とはいえ、数万〜数十万人程度のデータであれば問題なく回りますので、よほど重いデータセットを扱わない限りは問題ないと思います。
②パッケージの妥当性が全て確認されているわけではない
先ほども申したように、Rでは世界中のRユーザーが開発してくれた技マシン、つまりパッケージを使うことができます。
「だれでも開発・共有できる」という強みの裏返しになるのですが、パッケージの中にはその妥当性が確認できていないものもあります。
パッケージを使うRユーザーが側の視点からすれば、解析に使う変数や、その他の条件を指定してあげると、あとはパッケージが自動で解析結果をアウトプットしてくれるわけですね。
でも、肝心の「どのように変数を処理して、アウトプットに繋がっているか」という経過を確認することができないのです(しっかりしたパッケージは、そのパッケージを構成するコードも公開し、きちんとユーザーが中身をチェックできるようにしてくれています)。
このような理由から、製薬企業で行う解析は、RではなくSASを使うことが多いですね。
SASにもR同様にパッケージがありますが、SASの場合はしっかりとパッケージの妥当性が確保されているというのが理由の一つです。
終わりに
いかがでしたでしょうか?
無料で誰でも使用することができる解析ツール、Rのメリット・デメリットを解説して参りました。
次回からはいよいよ、皆さんの手でRを触っていきましょう。
まずはRのダウンロート編ということで、次回はRをどのようにダウンロードし、皆さんのパソコンで使える状態にするかということを解説していきます。
第二回はこちらからどうぞ!
すきとほる疫学徒からのお願い
本ブログは、読者の方が自由に記事の金額を決められるPay What You Want方式を採用しています。
「勉強になった!」、「次も読みたい!」と本ブログに価値を感じてくださった場合は、以下のボタンをクリックし、ご自身が感じた価値に見合うだけの寄付を頂戴できますと幸いです。
もちろん価値を感じなかった方、また学生さんなど金銭的に厳しい状況にある方からのご寄付は不要です。
引き続き情報発信していく活力になりますので、ぜひお気持ちに反しない範囲でご寄付をお願い致します!






