

こんにちは、すきとほる疫学徒です。
アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。
私が観測できている範囲でも、使用可能な医療DBが日にひに増えてきており、医療DB研究を行う研究者には、「使用可能な医療DBを把握し、それぞれの正しい使いどころをアセスメントする能力」が求められるようになってきました。
そのような医療DBの乱立の中で、日本薬剤疫学会をはじめとし、いくつかの機関、研究者が主だった医療DBの概要を説明してくださっております。
こちらの記事では「もう一歩進んだ医療DBの理解を」をテーマに、それぞれの医療DBがどのようなリサーチクエスチョンと相性が良いかということを、具体例を添えて実践的に説明していきたいと思います。
なお、医療DBの運営者、設立年、サンプルサイズ、母集団、収集されている項目などの基礎的な情報には触れませんので、それらの情報は以下の日本薬剤疫学会による日本で使用可能な医療DBのまとめをご参照ください。
https://sites.google.com/view/jspe-database-ja2020/%E3%83%9B%E3%83%BC%E3%83%A0
・それぞれの医療DBを使った代表的な研究
・それぞれの医療DBが得意とするリサーチクエスチョン

「RWD研究の支援をしてほしい」というご相談を多くの企業様から頂戴するので、企業様向けに正式に窓口を設置しました。
以下のアドレスに連絡頂ければ私に直通しますので、「1時間の無料相談」も含めてお気軽にご連絡ください(3営業日以内にお返事させて頂きます)。無料相談は大変ご盛況となっており、先着順にて対応させて頂いております。
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
私が経営するmMEDICI株式会社ではRWD利活用支援を事業の柱の一つとしており、以下の強みを有しています。「企業の」RWD研究においては日本トップクラスの解像度と経験値を有する自信がありますので、ぜひ無料相談でご体験くださいませ。
- 元大手外資の日本・グローバル出身の疫学専門家が全案件を担当するので、「企業の」RWD研究に高い解像度を有しています
- ただ成果物を納品するだけでなく、グローバルやKOLとの合意形成、社内プレゼン、規制当局対応などRWD研究の「プロセス」も全てまきとれます
- 企業のRWD研究を幾度となく経験しており、企画立案から論文化までの全フェーズを一気通貫で対応できます
- アカデミアのRWD研究者と広い繋がりを有しており、必要に応じた専門人材のアサインが可能です
- RWD研究だけでなく、事業立案、マーケ、広報、営業などのRWDビジネスも全て対応可能です
以下に私の実績を記載させて頂きます。
- 大手外資製薬2社にて、部門唯一の疫学専門家として活動をリード
- 「RWDビジネスの教科書」の書籍を出版(サイドバーをご覧ください)
- 企業でのRWD研究の経験は50本以上
- 製造販売後データベース調査のリード経験多数
- これまで製薬、CRO、コンサル、総合商社、ヘルステックなど10社以上の企業のRWD研究・RWDビジネスを支援
- 50組織以上にRWD研修を提供
- 全体統括・講師を勤めたJapan RWD Summitでは初回から約1,700名の集客を実現
無料相談では、以下のような内容を含め企業様の「RWD」と名のつく相談でしたら全て対応させて頂きます。
- このテーマでRWD研究はできるの?
- RWD研究っていくらくらいかかるの?
- RWD研究ってどんなプロセスでやれば良いの?
- 製造販売後データベース調査のやり方を教えてほしい
- RWD研究をするにはどんな専門家を雇えば良いの?
- 自社のRWDサービスを売りたいんだけど、強みはどこ?集客はどうすれば良い?
無料相談は先着順での対応となりますので、ご希望の企業様はぜひお早めのコンタクトをお願い致します!
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
データベースの説明
本日は、JMDCデータベースを紹介します。
JMDCデータベースは、株式会社JMDCによって収集、運用されている診療報酬請求データベースです。
JMDCは健保から収集した保険者データベースと、病院から収集した病院データベースの双方を有しているのですが、今回の記事ではJMDCデータベースと聞いた際にまず思い浮かぶであろう保険者データベースに焦点を当てて解説していきます。
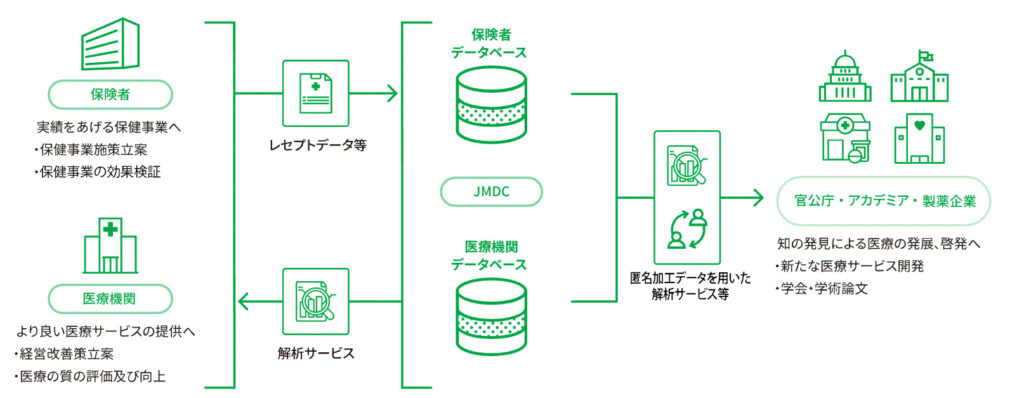
前回説明したDPCデータベースが入院患者のデータベースであったのに対して、JMDCデータベースは該当する健保の対象である被保険者および被扶養者に対して発生した診療報酬請求であれば、外来であろうが入院であろうが全てカバーすることができます。
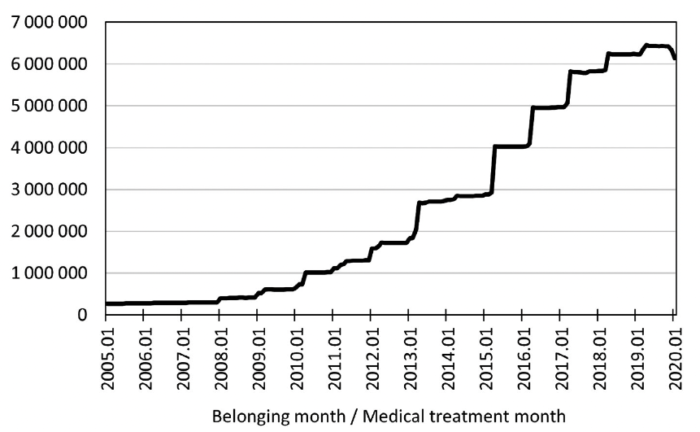
データ収集は2005年1月から始まり、2021年末時点で約1,200万人分のデータを収集しています。
下の図でもわかる通り、年々右肩上がりで登録者が増えていっていますね。
なお、JMDCデータベースの説明は以下の論文に詳しいので、さらに知りたい方は一読をお勧めいたします。
https://pubmed.ncbi.nlm.nih.gov/35304702/
データベースの特徴
Patient Journeyが追跡可能である
JMDCデータベースは、保険者データベースですので、その保険に登録される個人のレセプトデータは全て収集することができます。
つまり、患者が転院しようが、複数の医療機関を受診しようが、クリニックを受診しようが、患者の動向を追跡できるということですね。
薬剤疫学においては薬剤を使用した瞬間に有効性や安全性が評価できるというのは稀で、だいたい数年間にわたる長期的な患者追跡が必要になります。
この際、患者が他の医療機関に行ってしまうと追跡が一切できなくなるような病院ベースのデータベースですと、「患者を追いきれない」という問題が生じてしまうわけですね。
これにより、しっかりと追跡すれば将来発症していたはずの有効性・安全性アウトカムを見逃してしまう、脱落によりサンプルサイズが低下してしまうといった重大な問題が起こり得ます。
また、疾患によってはクリニックと病院の双方を定期受診したり、複数の病院を回ることでセカンド、サードオピニオンを収集するといったことも起こり得ますが、こういった受診プラクティスも病院データベースの場合は全く拾い上げることができなくなってしまいます。
保険者データベースであるJMDCデータベースの場合は、医療機関を跨いだPatient Journeyが追跡可能ですので、より精細に患者の受診プラクティスを把握することができるわけですね。
しかしながら、そんなJMDCデータベースの患者追跡性能にも弱点があります。
それは、「JMDCデータベースがカバーする健保の保険から外れると、追跡できなくなる」というものです。
例えば、転職、退職、扶養からの離脱といったエピソードが該当します。
例えば、55歳から59歳までその会社で働いた登録者が、60歳になって退職した瞬間、JMDCデータベースから離脱してしまうと言うことが起こりうるわけですね。
高齢者のデータが少ない
JMDCデータベースは健保、つまり企業の保険者からデータを収取しておりますので、企業で働いている人間+その被扶養者のデータのみが入手可能です。
日本は75歳以上の高齢者は全て後期高齢者制度でカバーされるため、すべからく健保から離脱します。
75歳未満かつ60歳以上もしくは65歳以上の高齢者に関しては、退職後もJMDCデータベースにカバーされる健保の保険者から扶養されている場合は、被扶養者としてデータが収集されます。
しかしながら、彼らは59歳以前もしくは64歳以前は他の健保に所属しており、そこから被扶養者となりJMDCデータベースに新たに登録された可能性が高いわけですから、JMDCデータベース登録以前のデータがぷっつりと切れているということになります。
そうなると、JMDCデータベースでは高齢者を対象にした研究は手が出しにくいということになりますね。
ちなみに、薬剤疫学会が公表しているデータでは、JMDCデータベースの年齢分布は
0-14歳:17%
15-64歳:79%
65-74歳:4%
75歳-:0%
となっています。
加入者台帳を有している
加入者台帳というのは、同一世帯の被保険者+被扶養者単位で与えられる登録帳みたいなものです。
これがあると、同一世帯内での家族間の結合ができたり、レセプトが発行されていない登録者の存在が把握できたりします。
「ふーん、それで?」
って思いませんでした?
実はこれ、超超超超超超超すごいことなんです。
私、JMDCデータベースが大好きなんですけれども、好きの理由の50%くらいがこの”加入者台帳”を有しているからです。
まずですね、家族間結合ができると何ができるかと言うと、例えば世帯内の人間が何らかの疾患に罹ったときに、他の家族にどのような影響が生じるかとったテーマの研究ができるようになるんですね。
また、母子結合ができるので、母が妊娠中に何らかの薬剤を摂取したことで、児に何らかの異常がでるかどうかといったことも検証可能になります。
次に、加入者台帳があることで分母、つまりコホート全体が把握できるようになります。
病院ベースのデータベースであれば、その病院を受診した人しか把握できませんので、受診がない人たちは何人いるのか、どこで何をやっているかもわからないわけです。
一方、加入者台帳があることによって分母がわかり、コホート全体における疾病の発症頻度が計算できますし、薬剤の使用実態といった記述疫学が活躍する場面も増えます。
母子結合ができる
先ほどお伝えした加入者台帳のおかげで、JMDCデータベースでは母子結合が可能になります。
市販されている薬剤は、その殆どが「妊婦での使用が禁忌、もしくはベネフィットがリスクを上回ると判断された場合のみ使用」と条件づけられています。
つまり、妊婦における使用はImportant Missing Informationなわけです。
なぜMissingなのかというと、薬剤の多くが治験中は妊婦に投与することができず、実際のところ「妊婦に投与するとどうなのか」という薬剤の有効性・安全性が十分に明らかになっていないからです。
でも、明らかになっていない、つまりどれだけのリスクがあるか不明という理由で妊婦への投与を一律禁忌もしくは慎重投与としてしまっていたら、本当は低リスク・高ベネフィットであるはずの薬剤も妊婦に投与されないままになってしまうかもしれません。
日本において母子結合ができるデータベースは非常に希少なのですが、その代表がJMDCデータベースであり、私はそういった意味で薬剤疫学、特に妊婦を対象にした研究においてJMDCデータベースが担う役割は非常に大きいと思っています。
ただ、残念ながら母子であれば何でもかんでも結合できるというわけではありません。
先ほども申したように、JMDCデータベースの加入者台帳は同一の保険でカバーされている世帯メンバーの間のみでの結合を可能にします。
つまり、児が父の扶養に入っており、共働きの母は別の保険に入っているというような状況だと、母子結合ができないんですね。
父が働き、母と児が父の扶養に入るというような家族形態が当たり前だった一昔前と違い、近年は父母共働きという家族形態も増えているわけですから、となるとJMDCデータベースで結合できる母子にも限りが出てくるわけです。
ですので、JMDCデータベースで母子結合をする際には、「その母子がいったい社会的にどのような状況にあるのか」ということをしっかりと理解し、結果の一般化可能性を考慮する必要が出てきます。
また、母子結合のアルゴリズムも100%間違いなく母子を結合できるというものではありません。
よく用いられる方法では、「児の出生月と保険加入月が同一であれば、同一保険者内の成人女性の児とみなす」というものがあります。
日本の母子関係を考えれば、この方法はおそらくかなりの確度で母子結合を成し遂げてくれていると思いますが、たとえば出生したばかりの児を養子として引き取り、同一月に成人女性の被扶養者としたような状況ですと、養子を実子と取り違えてしまう、つまり偽陽性が生じます。
また、JMDCデータベースでは妊娠週数を特定することもできません。
薬剤疫学においては、妊娠のどの週数で薬剤に曝露したかによって有効性・安全性が変わってきますので、単に「妊娠中の曝露の有無」とするだけではなく、より細かく妊娠週数を分けて「妊娠第一四半期に曝露の有無」といったように曝露を設定しなければなりません。
ですので、妊娠週数を特定する必要があるんですね。
診療報酬請求データで妊娠週数が特定できないと言う課題は、世界中のデータベースが抱える課題で、さまざまな方法を用いて手に入るデータから妊娠週数を精度高く定義しようと言う試みがなされています。
例えば、正常産であれば児の出生月から遡って38週を妊娠開始とする、
早産であれば児の出生月から遡ってX週を妊娠開始とする、などですね。
日本でJMDCデータベースを使って行われた研究ですと、こちらの論文が詳しくアルゴリズムを記載していますので、参考にすると良いと思います。

私の知る限りでは、日本の医療大規模データベース研究で妊娠週数レベルで曝露を定義しようと試みた論文は、この1本だけです。
ちなみに、同じような研究をJMDC社さん自らもやってらっしゃっており、こちらはレセプト病名から「流産」、「死産」と妊娠期間を特定しようとしたという学会発表です。

少し話がそれるのですが、JMDC社さんがすごいのは、上の学会発表のように、ただデータを集めて売るというだけではなくって、自らデータベースの価値を切り開いていくために、こうして丁寧にエビデンスを積み重ねているところです。
多くの医療データベースベンダーさんって、普通はこんなことしないんですよ。
そこをJMDCさんは自ら切り込んで、エビデンス創出を進められていくので、まさに日本の医療データベース研究をリードしていこうという強い気概を私は感じています。
こちらはJMDCさんが連載している自社コラムですが、このコラムを読めば、JMDCさんのデータベース研究にかける熱意をよく感じ取って頂けると思います。
https://www.phm-jmdc.com/column
最新の記事は、なんと「データベースの人数に騙されるな!」という過激タイトル。
JMDCデータの患者の追跡可能性に関して語っているんですけど、何とその中で以下のように述べています。
最近、私自身もこうした集計をしてみて、5年以上追跡できる人は多いけれど、累積1000万人以上という数字から考えると、とても減ってしまう、、、そんな印象をもってしまいました。
データベースの人数に騙されるな
これ、要は自分で自分の会社の主力商品の弱点を宣伝してるわけですよね?
実際は、JMDCデータベースのサンプルサイズを考えれば、長期追跡できる患者も多く存在しますし、保険者データベースであるJMDCが、他社の病院データベースに比べてより長く患者を追跡できることは間違いないので、真の意味では弱点ではないのですが。
しかし、残念ながら医療大規模データベースに関するベンダーさんの中には、買い手に医療大規模データベース研究の十分な知識がないことを良いことに、とってつけたような説明をして、自社のデータベースを過剰に宣伝しようとする方もいらっしゃいます。
そんな中で、自社データベースの追跡可能性の限界に対してもしっかりと言及してらっしゃるJMDCさんは、とても誠実にサイエンスをやろうという姿勢が感じられ、私は勝手に感動しておりました。
一部アウトカムのバリデーションがとれている
使用する医療大規模データベースを選択する際に最も大切とも言えるポイントは、「入力されているデータがどれだけ信用に足るものなのか」ということです。
「データは集めたけど、信用ならない」、そんなデータを使ってどれだけ豪華絢爛な研究をしたところで、そもそものデータが信用ならないのであれば、意味がありませんよね。
そのデータの信用性を確保するために行う研究が、バリデーション研究です。
驚くことにJMDCさん、新潟大学とタッグを組んで、自らバリデーション研究を行っています。

「え、自分達のデータベースの信頼性を証明するための研究なんだから、そりゃやるっしょ?」と思うかもしれませんね。
ところがどっこい、このバリデーション研究という類の研究、めっちゃくちゃ研究者への負荷が大きいんですよ。
多くは電子カルテの診断と、レセプト定義の診断を照らし合わせて、「一致率Xパーセントー!」みたいなことを示すわけなんですが、そのためには対象とするすべての患者の電子カルテをしっかりと読み込み、「その患者の正しい診断が何か」ということをいちいち確認していかないといけないんです。
また、1名の医師による診断だと結果にブレが出ますので、それを防ぐために最低でも2人の医師が独立して同一の患者群に対して電子カルテレビューを行う必要があるんです。
非常にお金と時間がかかる研究ですので、医療大規模データベース研究に関わる人たちも、正直バリデーション研究を自ら進んでやることには抵抗があるのではないでしょうか?
少なくとも私は、バリデーション研究をやってくれた研究者は聖人君子として後世まで讃えられるべきだと思っています。
データベースベンダーさんも例に漏れず、自らのデータベースとはいえ、バリデーション研究には強い抵抗感があるはずです。
少なくとも私は、JMDCさん以外には自らバリデーション研究を行ったデータベースベンダーを知りません。
そんな中で、JMDCさんは颯爽とバリデーション研究を実施してくれたわけですね。
先ほどの妊婦結合の事例もそうですが、このバリデーション研究の事例からもまた、私はJMDCという会社が医療大規模データベース研究にかける熱意を感じ取っていたのでした。
特定健診のデータがある
特定健診とは、40歳から74歳までの日本国民に対して行われる健康診断、および保健指導です。
メタボリックシンドロームの早期発見と予防を対象に行われているため、健診では身長、体重、血液検査に加えて、生活習慣に関する質問が収集されます。
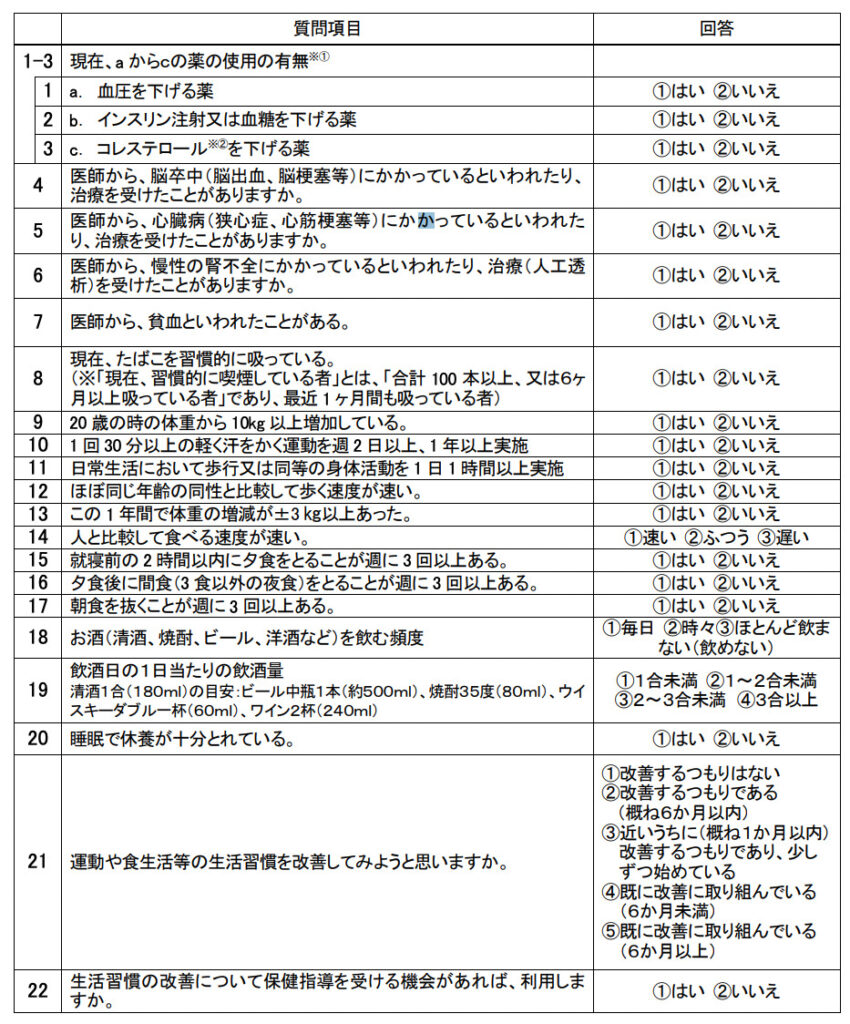
このデータを使うことで、生活習慣と何らかの疾病の因果関係を探るような疫学研究を行うことができます。
また、このデータを背景因子として比較研究に投入すれば、通常のレセデータでは調整しきれない未測定の交絡因子にもチャレンジすることができます(ただ、特定健診は対象年齢が限られていますし、また受診率も50%ちょっとと極めて低いため、欠損が大きい点に要注意です)。
対象者の社会経済的因子に偏りがある
JMDCは健保、つまり企業の保健組合からデータを集めています。
日本においては健保は比較的大規模な企業において提供されていますので、JMDCデータベースのコホートも必然的に”大規模企業に勤める社員”と”その被扶養者”となります。
JMDCデータベースのコホートの社会経済的因子を調査した研究は私の知る限りでは存在しませんが、おそらくそのコホートは、経済的に豊かであり、学歴が高い、つまりより良い社会経済的状況にあるコホートで構成されていると言えるでしょう。
マイケルマーモットのホワイトホール研究を筆頭に、多くの研究が社会経済的因子と健康アウトカムの因果関係を示唆し、それらは”健康格差”と呼ばれる言葉で表現されてきました。
仮に、社会経済的に豊かな状況にあるコホートと、そうではないコホートにおいて、何らかの薬剤と健康アウトカムの関連が異なるとしたら(例えば、収入が高いコホートほど、薬剤内服から得られるベネフィットが大きいなど)、JMDCデータベースで行われた研究を、それとは異なる社会経済的因子を有するコホートには適応することができません(社会経済的因子による効果修飾)。
感動した論文例
若年性認知症の発症は失職と関連しているか?

この論文を見つけた時、震えるほど感動したことを覚えています。
今でも定期的に読み返して、「ほんとに良い論文だなぁ」と感慨に浸ります。
素敵な点は主に3つ。
リサーチクエスチョンの社会性の高さ
みなさん、”医療データベース研究”と聞くと、どのような研究を思い浮かべますか?
おそらく、多くの方が”薬剤とアウトカムの関連”、”オペとアウトカムの関連”といった病院内の出来事、つまり臨床疫学をテーマにした研究を想像するのではないでしょうか?
事実、医療データベース研究ではそういったテーマの研究が非常に多くなされています。
この研究の素晴らしさは、医療データベースを使いながら、病院の外のこと、つまり公衆衛生に焦点をあてたことだと思っています。
若年性認知症という疾患がもたらす社会生活への負担を、一見冷たそうに見える診療報酬請求データの集合体を使い、リアルに描き出していった。
「社会的な課題を世間に訴える」と聞くと、私はついついドキュメンタリーや小説、映画といった芸術媒体を想起してしまうのですが、この論文は「論文というメディアにおいても、こうして社会的課題に一石を投ずることは可能なのだ」と教えてくれました。
むしろ、英語で論文にすることで、世界中の研究者がどこからでもこの論文にアクセスすることができ、日本の若年性認知症患者をとりまく社会的課題を知ります。
個々人の意見ではなく、”精緻に立証された科学的事実”として。
医療データベースだからこそできる研究である
筆者ら曰く、この研究以前には若年性認知症が失職にもたらす影響を量的に測定した研究はなかったとのことです。
すべての研究が、質的手法によるものであったと。
これは、若年性認知症が希少な疾患であり、サンプルサイズを集めることが難しかったことに起因すると筆者らは考察しています。
しかし、その研究の困難性を、医療大規模データベースというツールを用いることで打ち破りました。
医療データベース研究をやっていると、
「そんなデータから何がわかるんだ」
「重箱の隅をつつくような方法論にしか見えない」
「人のデータで研究なんて、楽できて良いね」
という批判に出会うことがあるのですが、この研究はまさに「医療大規模データベースだからこそできた」研究であり、その意義を十分に訴えていると思います。
医療データベース研究の天敵である欠損を活かしている
欠損は、医療データベース研究の天敵です。
欠損があることで、
サンプルサイズが減少する、
状況によっては選択バイアスがかかる、
発症していたはずのアウトカムを拾いきれない
といった問題が生じます。
しかしながら、この研究はそんな医療データベース研究の天敵であるはずの欠損をアウトカムにすることで、見事そうした問題への解答としていました。
欠損をどのようにアウトカムにしたのでしょうか。
JMDCは保険者データベースですから、対象となる保険者から離脱すると、患者は追跡不能となります。
では、JMDCにおける「保険者から離脱」とは、何を示すのか?
そう、会社を辞めることですね。
JMDCでは離職の原因まではわからないため、本当に若年性認知症が原因になっているのか、離職なのか転職なのかといった細かな状況を特定することはできませんが、「若年性認知症によって就労が困難になった」ということは、十分に臨床的妥当性がある考察です。
天敵であった欠損。
この研究を読んだ時に、「欠損はこんな使い方もできるのか!!!」と衝撃が走ったのでした。
ウェアラブルデバイスとJMDCを利用した精神疾患の発症予測モデルの作成

日本ではまだ十分に研究されていない、
ad hoc data + claims dataの組み合わせによる精神疾患の発症予測です。
感動した点を述べていきます。
診療報酬請求データ+前向きのデータ収集
医療大規模データ、特にClaims dataと呼ばれる診療報酬請求データベースの弱点は「集められるデータが固定されている」というものでした。
そもそも、診療報酬請求データベースは「診療報酬の請求に使ってるこのデータ、たくさん集めたらなんか研究にも使えんじゃね?」というモチベーションで研究活用されているため、集められるデータが診療報酬請求のデータだけであることは当然です。
ですので、私たちのような診療報酬請求データベースの研究者は、
「あるデータで何とかする!」
というマインドで研究に臨んでいます。
そのため、診療報酬請求データベースで対応できるリサーチクエスチョンには限りがありました。
その壁をぶち破ったのが、JMDCさんのPep upというサービスであり、そのサービスがエビデンスに結びついたのが、この論文です。

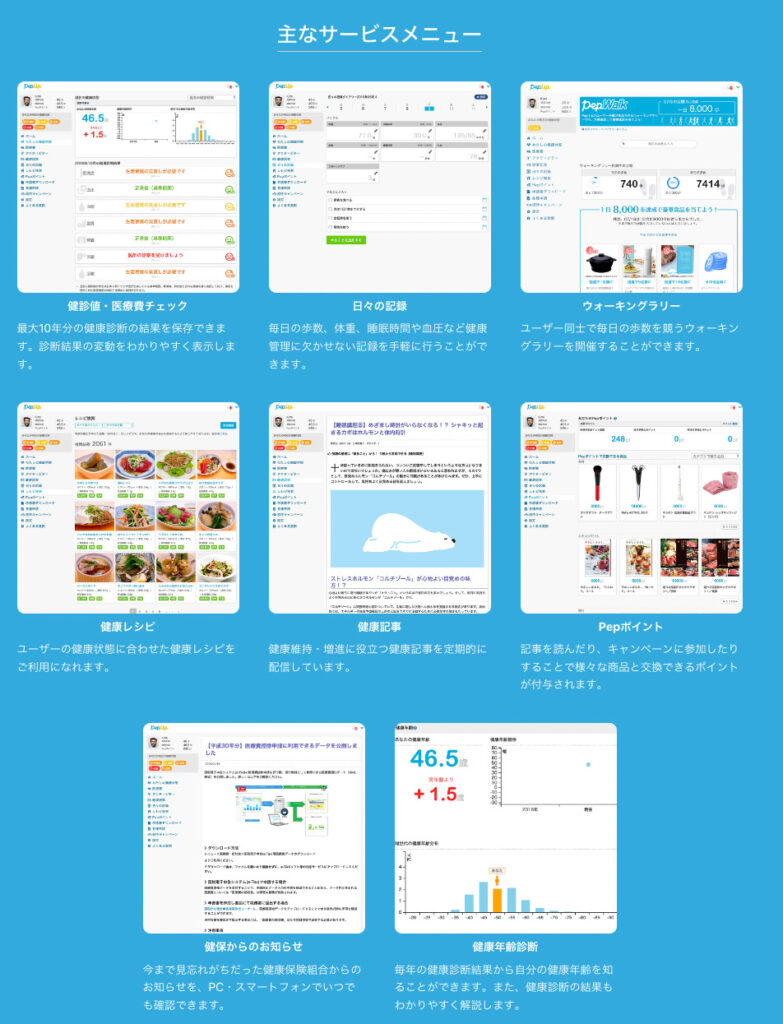
JMDCさんのPep Upにより前向きでのデータ収集が可能になったことで、診療報酬請求データベースの可能性は青天井に上昇しました。
「あのデータがないから診療報酬請求データじゃだめだ」
から、
「あのデータがないから、追加で集めよう!」
に。
まさに、医療データベース研究におけるイノベーションの一つと言っても良いと思います。
本研究では、精神疾患の発症を
・精神疾患への処方薬
・精神疾患での医療受診(通院・在宅精神療法の加算で特定してると思います)
の組み合わせて特定しています。
私が知る限りでは、認知症以外の精神疾患の病名妥当性を検証したバリデーション研究は日本には存在していないので、エビデンスをもってICD-10病名の妥当性を語ることはできないのですが、個人的な印象としては感度はかなり低くなるだろうと感じています。
そうしたこともあり、本研究はICD-10病名を避けて、上の2つの組み合わせで精神疾患発症を定義したのでしょう。
特異度はかなり高いと思いますが、感度に関しては「受診に繋がった精神疾患」しかとれないので、下がることを避けられないでしょう。
しかしながら、精神疾患という疾患特性を考えると、診療報酬請求データではなく質問紙調査などの前向き調査をしても、十分に拾い上げることは困難だと思います。
であれば、医療受診を用いた定義は私個人としては現状できる最善のものと考えており、十分に許容される余地はあるのではないでしょうか?
もしかしてJMDCさん、自分たちでこの論文書いてる?
上にあげた理由だけで、私はこの論文に感動していました。
さっそくこの記事で取り上げようと思い、元論文を読んでいたんですね。
そして気づきました、

「筆頭著者のアフィリが、JMDC!?」
「自分たちで論文書いてんの?!」
普通、医療データベース事業者さんが自社のデータで何かしらのエビデンスを出したいとすると、アカデミアの著名な先生と組んで、そっちに研究をやってもらうんですよ。
自社内にそんなリソースありませんから。
でもどうみてもこの論文、筆頭著者がJMDCさん所属なんだよなぁ。。。
すごい、ほんとにすごい。
この記事の前半でも取り上げたように、JMDCさんからは「日本の医療データベース研究そのものを革新していく」という強い信念を感じます。
何より、こういう研究を自社でやるだけのリソースがあるということは、私のように製薬側の社員からすると、「しっかりとサイエンスを理解して仕事をしてくださる方々」という極めて高い安心感につながります。
配偶者のICU入院は本人の精神疾患発症に関連しているか?

配偶者のICU入院後に、残された側の家族が抱く精神的負担は、”Post-intensive care syndrome-family(PICS-F)”と呼ばれ、かねてより問題視されていたようです。
今回の論文は、その問題を量的手法により検証しています。
感動した点は以下です。
医療データベースだからこそできる研究である
先に述べた論文でも同じ理由を書きましたが、この論文もまた「医療データベースならではの」研究となっています。
医療データベース研究が流行るにつれて、多くの方々がそれを用いた研究に取り組むようになってきました。
それ自体は大変喜ばしいことだと思いますが、なかには「データがあるから、とりあえずやってみよう」というようなモチベーションが透けて見て、十分に実現可能性や研究の新規性を考慮せずに行われている研究があることも事実です。
一方、この論文は違います。
まず、PICS-Fを調べた先行研究は、すべて比較群がなく、そのため「ICU入院と配偶者の精神的負荷との間に因果関係があるか」ということが特定できていませんでした。
また、配偶者が研究対象の施設以外を受診して精神疾患と診断された場合には、追跡しきることができていませんでした。
これらの限界に対処するために、この論文は
・大規模データによりサンプルサイズを確保して、比較群を置く
・保険下で提供された医療であれば、すべて拾うことができるJMDCデータベースを用いる
という工夫をしています。
まさに「医療データベースでなくては実現できなかった研究」であり、「これこそ医療データベース研究!」と言えるような論文だと思っております。
考察が控えめである
本研究の結果、「配偶者がICU入院した者では、そうでない者よりも”わずかに”精神疾患の発症リスクが上がる」という結果になっています。
この”わずかに”というのがポイントですね。
残念な研究ですと、わずかでも解析結果に有意差があると、「差がある!だから〜しなければならない!」というように、P-value上の有意差を臨床上の重要性とイコールであるかのように(知ってか知らずか)誤解して、考察を展開するものもあります。
しかしながら、この研究は単にP-Valueのみで結果を評価するのではなく、誠実に点推定値と信頼区間を持って判断し、淡々と結果から言えることのみを考察で展開しています。
ですので、考察は「なぜICU入院すると、配偶者の精神疾患発症リスクがアガあるか」という視点からではなく、「なぜICU入院しても、配偶者の精神疾患発症リスクが思ったより高くはないのか」という控えめな視点から展開されておりました。
医療データベース研究においては、そのサンプルサイズの大きさから、臨床的に重要ではない差まで解析上は有意になってしまうことが多々あります。
だからこそ、今回の論文で筆者がおこなっているように、P-valueに踊らされず、冷静に結果を解釈するという研究態度が大切になるのですが、まさにそのお手本のような研究だと思ったため、ご紹介いたしました。
妊娠第一四半期のPropulsivesへの曝露は児の大奇形発症のリスクを増加するか?

妊娠期間中の薬剤曝露と妊婦もしくは児への影響を調査したJMDCデータベース研究はいくつか存在しますが、この研究のポイントは”妊娠第一四半期”ということで、妊娠期間をさらに細かく分けて曝露を定義していることですね。
この記事の前半でも述べましたが、JMDCデータベースのような診療報酬請求データベースを使い、「妊娠期間をどう定義するか」という課題は、世界中で議論されてきました。
アルゴリズムの妥当性を検証した論文も複数の国から出版されています。
ちなみにこの研究では、妊娠に関する病名、処置に対して記入されることのある妊娠週数データを使い、妊娠期間を特定しようと試みているようです。
個人的には、日本の診療報酬請求の週数データは完全に医師の自発性によって記録されており、本当に研究に用いて良いかどうか私は確証が持てません。
その方法よりは、海外の妥当性研究が検証しているように、アウトカム別に特定の妊娠週数を割り当てる方法の方が良いのではないかと感じています。
例えば、
早産:出産日から遡ってX週
正常産*:出産日から遡ってY週のように
*正常産をどう特定するかということも要検討です
ただ、私が知る限りは日本の診療報酬請求データベースを用いた研究で、週数を特定しようとチャレンジした研究は本研究が初めてであり、その意味で本研究の意義は大きいと思っています。
本研究のメソッドには、日本の診療報酬請求データベースで妊娠週数を特定しようとした際に生じる問題が、しっかりと記述されていますので、JMDCデータベースを用いて妊婦ん関する研究をしようとする方は、ぜひご一読されると良いと思います。
ただ、繰り返しになりますが、妊娠週数の特定方法自体は、私は海外で紹介されているアルゴリズムを用いた方が良さそうな気がしているので、興味がある方はぜひそちらの論文もご覧になって見てください。
あと余談ですが、この研究は、用いた研究手法の妥当性を証明するために、Positive Controlという方法を使っています。
これも、日本の医療データベース研究だとまだあまり見ない方法かもしれませんが、カッチリと条件にハマれば非常に使い勝手の良い手法なので、ぜひ調べてみると良いでしょう。
詳細は、以下のブログで書いています。
終わりに
他のデータベースはこちらで紹介しておりますので、あわせてご覧ください。
こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]

こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]

こんにちは、すきとほる疫学徒です。 アカデミアや企業で盛んに医療大規模データベース(以下、医療DB)が行われるようになった背景には、使用できる医療DBの増加という要因があります。 私が観測できている範囲でも、使用可能[…]

すきとほる疫学徒からのお願い
本ブログは、読者の方が自由に記事の金額を決められるPay What You Want方式を採用しています。
「勉強になった!」、「次も読みたい!」と本ブログに価値を感じてくださった場合は、以下のボタンをクリックし、ご自身が感じた価値に見合うだけの寄付を頂戴できますと幸いです。
もちろん価値を感じなかった方、また学生さんなど金銭的に厳しい状況にある方からのご寄付は不要です。
引き続き情報発信していく活力になりますので、ぜひお気持ちに反しない範囲でご寄付をお願い致します!






