

こんにちは、すきとほる疫学徒です。
製薬企業で疫学研究をしておりますと、色々なところでデータベース事業者さんからお声をかけて頂くことがあるのですが、ここ数年でデータベース事業者さんや、事業者さんが扱う医療大規模データベースの数が加速度的に増えている気がします。
要因としては、2018年前後のGPSP省令にて、新薬の製造販売後調査(薬剤が市場に出た後に、その安全性を調査するための試験)にてデータベースを使用した調査が正式に認められたことが大きいでしょう。
これにより製薬企業・医療機器会社におけるデータベース研究へのニーズが急増し、それに応じて色々な会社さんが「データベースを作るぞ!」とことで、新規参入してきているのだと思います。
現時点で製造販売後調査で使用可能な医療大規模データベースというのは非常に限られているため、データベース選定にかかる労力はそこまで高くはなかったのですが、こうして加速度的に潜在的に使用可能なデータベースが増えていることを考えれば、製造販売後調査を行う側には”正しく医療大規模データベースを選択する力”がより重要になってくると思われます。
また、仮に使用できる医療大規模データベースが1つだけだったとしても、「そのデータベースを使って、必要なリサーチクエスチョンに十分に答えられるのか」という実現可能性調査は必須です。
しかし、”薬剤疫学で使用する医療大規模データベースをどう選び、どんな観点で実現可能性調査を行えば良いのか”というガイドラインは、日本語では充実した資料がまだ公開されておりません。
というわけで、今回は以下の国際薬剤疫学会が作成したガイドラインをベースに、医療大規模データベースの選び方について解説していきたいと思います。
ちなみに、この記事は第一部から第五部くらいまで続く予定のちょっとした大作となっておりますので、我慢してお付き合い頂けますと幸いです。


「RWD研究の支援をしてほしい」というご相談を多くの企業様から頂戴するので、企業様向けに正式に窓口を設置しました。
以下のアドレスに連絡頂ければ私に直通しますので、「1時間の無料相談」も含めてお気軽にご連絡ください(3営業日以内にお返事させて頂きます)。無料相談は大変ご盛況となっており、先着順にて対応させて頂いております。
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
私が経営するmMEDICI株式会社ではRWD利活用支援を事業の柱の一つとしており、以下の強みを有しています。「企業の」RWD研究においては日本トップクラスの解像度と経験値を有する自信がありますので、ぜひ無料相談でご体験くださいませ。
- 元大手外資の日本・グローバル出身の疫学専門家が全案件を担当するので、「企業の」RWD研究に高い解像度を有しています
- ただ成果物を納品するだけでなく、グローバルやKOLとの合意形成、社内プレゼン、規制当局対応などRWD研究の「プロセス」も全てまきとれます
- 企業のRWD研究を幾度となく経験しており、企画立案から論文化までの全フェーズを一気通貫で対応できます
- アカデミアのRWD研究者と広い繋がりを有しており、必要に応じた専門人材のアサインが可能です
- RWD研究だけでなく、事業立案、マーケ、広報、営業などのRWDビジネスも全て対応可能です
以下に私の実績を記載させて頂きます。
- 大手外資製薬2社にて、部門唯一の疫学専門家として活動をリード
- 「RWDビジネスの教科書」の書籍を出版(サイドバーをご覧ください)
- 企業でのRWD研究の経験は50本以上
- 製造販売後データベース調査のリード経験多数
- これまで製薬、CRO、コンサル、総合商社、ヘルステックなど10社以上の企業のRWD研究・RWDビジネスを支援
- 50組織以上にRWD研修を提供
- 全体統括・講師を勤めたJapan RWD Summitでは初回から約1,700名の集客を実現
無料相談では、以下のような内容を含め企業様の「RWD」と名のつく相談でしたら全て対応させて頂きます。
- このテーマでRWD研究はできるの?
- RWD研究っていくらくらいかかるの?
- RWD研究ってどんなプロセスでやれば良いの?
- 製造販売後データベース調査のやり方を教えてほしい
- RWD研究をするにはどんな専門家を雇えば良いの?
- 自社のRWDサービスを売りたいんだけど、強みはどこ?集客はどうすれば良い?
無料相談は先着順での対応となりますので、ご希望の企業様はぜひお早めのコンタクトをお願い致します!
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
データベースを選ぶタイミングについて
ガイドラインの説明に入る前に、「どのタイミングでデータベースを選び、実現可能性調査をすれば良いのか」ということをお伝えしたいと思います。
結論からいうと、リサーチクエスチョンがFixされた直後です。
疫学や生物統計学をご専門としている方であれば、一度はご経験があるとは思うのですが、たまに「リサーチクエスチョンは〜で、データベースは〜を使うのだが、研究デザインについてコメントを貰えないか」というコンサル依頼が来ることがあると思います。
この際によく起こる問題が、「既に使用するデータベースを決めてしまっているが、そのデータベースでは検討しているリサーチクエスチョンに答えることができない」というリサーチクエスチョンとデータベースのミスマッチです。
また、「このデータベースを使用することができるのだが、これで何か研究ができないか?」といった形でのコンサル依頼を受ける専門家も少なくはないと思います。
しかしながら、このような医療大規模データベースの選び方は誤りであり、研究の実現可能性の根本を揺るがす問題になりかねません(最悪の場合、「このデータベースではご希望のリサーチクエスチョンには全く答えられないので、そもそものリサーチクエスチョンを再考する必要があります」ということになります)。
それぞれの医療大規模データベースには、含まれるデータ種類、サンプルサイズ、集団の特性、患者の追跡可能性などの特性の違いがあり、得意なリサーチクエスチョン、苦手なリサーチクエスチョンがあるのです。
例えば、「急性心筋梗塞の患者に対して、オペBと比較してオペAがどれだけ術後7日以内死亡率の低下に有効か」というリサーチクエスチョンで研究をしたかったとしましょう。
この時、DPCデータベースを用いることができれば、入院時の急性心筋梗塞の重症度、入院時の併存疾患、術後合併症、麻酔時間、入院時意識状態などの患者重症度に関する情報を入手することができます。
また、DPCデータベースは患者が同病院に再入院しない限りは、退院後の状態を追跡できないという弱点がありますが、今回は術後7日以内死亡率をアウトカムとしており、患者はまだ入院中である可能性が高いため、この弱点も大きな問題にはなりません。
一方で、「とある部位の癌に対する抗がん剤Aは、抗がん剤Bと比較して有害事象である脳梗塞のリスクを増加させるか」というリサーチクエスチョンで研究をしたかったとすると、DPCデータベースを使用することは適切でしょうか?
残念ながら、このようなリサーチクエスチョンにDPCデータベースを用いることは難しいでしょう。
なぜなら、患者が再入院しない限りは単一入院の情報しか得られないDPCデータベースでは、癌のような慢性疾患に対して中長期で投与されるであろう抗がん剤の投与プロファイルや、十分な誘導期間・潜在期間を考慮した上での脳梗塞の発症を知ることができないからです。このような状況では、NDBデータベースのように、癌発症者の主たるコホートである高齢者の情報も十分に含み、かつ施設をまたいでデータ結合が行えるようなデータベースを使用することが適切でしょう。
というわけで、研究で使用する医療大規模データベースはリサーチクエスチョンに応じて決定されます。
データがあることと、そのデータを使って妥当な研究が行えるかどうかは全く別の話です。
まずは、明確に定義されたリサーチクエスチョンがあり、そして次に「このリサーチクエスチョンに十分に答えることができるデータベースはどれか」という形で、データベースの選択を行なっていくわけですね。
この時も、上で述べたように将来得られる可能性のあるサンプルサイズ(各群において)、予想される必要な追跡期間、2群間での患者の比較可能性、曝露やアウトカムの定義の妥当性など、様々な角度からデータベース研究の実現可能性を精査して、そうしてようやく「よし、このデータベースなら十分リサーチクエスチョンに対応できそうだから、これを使う方向で研究計画を書いていこう」という意思決定が下されることになります。
特にProspectiveにデータの蓄積を待つ製造販売後調査においては(製造販売後調査は発売されたばかりの新薬を対象にするため、発売時点でデータベースにデータが蓄積されていない)、データが取集され始めた後も、何度か上記のような実現可能性の精査を重ねる必要があります。
ですので、研究計画には「どの時点で、どんな内容の実現可能性調査を行い、そしてその結果がどうであったらどうするのか(実現可能性調査で用いる指標の閾値など)」を事前に定義しておかねばなりません。
これがないと、研究者に都合の悪い結果が出そうな時だけ、「実現可能性がなさそうだから、やっぱりデータベース調査やめて、Primary data collectionをやろう」などという恣意的なデータソースの選択が可能になってしまいます。
さて、データベースを選ぶタイミングについてお話した後は、いよいよデータベースの選び方、実現可能性調査のポイントについてお話ししていきましょう。
データベースの選び方 ①Population covered
研究を行う対象集団は、データベースの決定前に明確に定めていなければなりません。
例えば、”50歳以上の薬剤Aまたは薬剤Bの新規内服患者で、既往歴として〜を持たず、Index dateより12ヶ月前の助方を入手できる患者”などですね。
この情報をもとに、以下のような観点から医療大規模データベースを選択していくことになります。
Study sample size
データベース研究は、診療行為や保険請求など他の目的で集められたデータを2次的に研究活用することで可能になるため、Primary data collectionのように「データが足りないから、追加収集しよう」といったことは不可能です(期間が許すなら、”もう半年データの蓄積を待とう”ということは可能ですが)。
ですので、”そのデータベースで必要なサンプルサイズが本当に得られるのか”ということはデータベース選択時に入念にチェックしなければなりません。
サンプルサイズ計算により必要なサンプルサイズを算出し、それと共に手元にあるデータから「この先X年間で、薬剤Aと薬剤Bに曝露する患者はそれぞれY人、Z人集められるな」と将来の患者数予測を行います。
そして、必要サンプルサイズと予測された患者数を比較することで、サンプルサイズの観点から実現可能性調査を行うわけですね。
患者数推計のこの方法は人それぞれだと思いますが、私の場合は
- 現時点(ターゲット薬の販売前)のターゲット薬が所属するクラスの薬剤シェアを調査する(X薬5%、Y薬7%、Z薬2%など)
- それらの数字から、クラスにおけるターゲット薬のシェアを予測する(ここが非常に難しいです)
- 毎年の対象患者におけるクラス薬の新規使用者を算出する
- 3の年次新規使用者数から、将来の新規使用者数を予測するモデルを作り、研究期間別の新規使用者数を算出する
- 2で求めたシェアに、4で求めたシェアをかける形で研究期間におけるターゲット薬の新規使用者数を算出する
といった方法をとることが多いです。
ただ、この方法では幾つかの強い仮定を置いているため、注意が必要です。
まず、”クラス内のマーケットシェアが時間によらず一定である”という仮定があります。
また、医療大規模データベースではデータベース事業者さんの努力により年々参加施設数が増えることがありますが、その増加率も過去データと同一であると仮定しています。
同様に、それらの薬剤の適応症である疾患の有病者数の増加率も過去データと同一と仮定しています。
さて、このようにして調査した実現可能性を考慮する際に注意せねばならないのが、将来の患者数を手元のデータを使って推計する際には、可能な限り研究計画で定めている患者包含・除外基準に近い定義で患者数をカウントすることです。
研究計画ではNew user designを用いるつもりでいるのに、実現可能調査ではPrevalent userも含めて患者数を推計していたら、推計の意味をなしませんよね。
なお、New user designとPrevalent user designについては以下の記事で解説しております。
こんにちは、すきとほる疫学徒です。 本日は、薬剤疫学分野で観察研究を行う際に注意しなければならないバイアス、Prevalent user biasを取り上げ、その理論的背景、具体例、そして対処法について解説していきたいと思[…]

また実現可能性調査時点では、研究計画の患者包含・除外基準と完全に一致した方法で患者数の推計を行うことが難しい状況が多いため、研究開始前の推計はあくまでも推計であることを忘れないようにしましょう。
実際にデータ収集が終わった後も、「いざ解析を始めてみたら、サンプルサイズが大幅に不足していた」という事態も起こりかねます。その場合は、別のデータベースの使用を検討するか、+αの期間にデータ収集を行うか、それともデータベース研究を諦めてPrimary data collectionを行うかなどの判断が必要になるでしょう。
なお、+αの期間にデータ収集を行う際も、手元のデータで再度患者数推計を行い、どの程度待てば十分なデータが集まるかという見積もりを立てておかねばなりません。
Coverage
対象とする患者属性を有する患者がデータベースでカバーされているか、ということですね。
例えば、とある部位の癌に対する抗がん剤Aをターゲット薬とした研究を行いたかったとしましょう。
この時、データベースとしては手元に健保から集めた保険者データベースがあるとして、このままデータベース研究を行うのは適切でしょうか?
おそらく、難しいでしょう。
日本では高齢者は健保から外れることが多く(75歳以上に関しては100%外れる)、また健保の被保険者は企業勤務をする方々です。
前者によって癌患者の主たるコホートである高齢者が除外されてしまい、後者によって”癌によって退職せざるを得なかった患者”が除外されてしまいます。
このように、データベース研究を行う前には、「そのデータベースで集められる患者が、どのような患者が」ということは入念にチェックしておかねばなりません。
Representative sample
Coverageと類似したチェック項目として、”そのデータベースで集められた癌Aの患者コホートは、母集団(例えば日本の全ての癌Aの患者)をどの程度代表するものであるか”というRepresentativenessがあります。
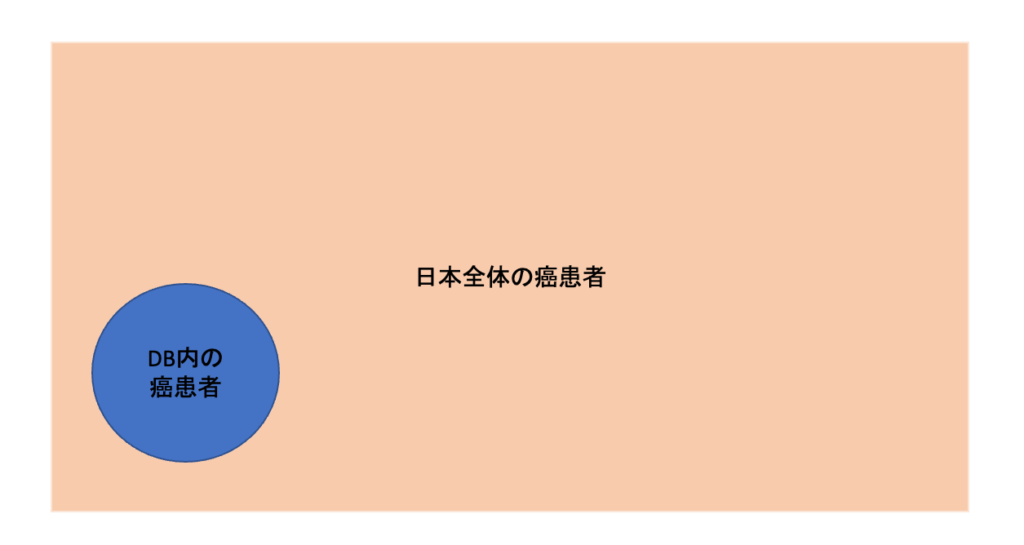
例えば、日本全体の癌患者の平均年齢が70歳であるにも関わらず、データベース内の癌患者の平均年齢が50歳だったとすると、そのデータベースを使って得られた研究結果を日本全体の癌患者に外挿することは難しいでしょう。
年齢がEffect modifierとなっているリスクがあります。
また、データベースにおける患者選択が曝露より時間的に後に位置する因子で行われている場合には、選択バイアスが生じてしまっている可能性があります。
データベースの選び方 ②Study variables
Capture of study variables
データベース研究では、曝露やアウトカム、患者の包含基準・除外基準、交絡因子など様々な変数が必要になります。
データベースの選択、実現可能性調査においては、
- 必要な変数が入手できるか
- 入手できないとしたら、代理の変数を設定できるか
- それらの変数の妥当性はどの程度か
ということを検討しなければなりません。
こういった変数定義が特に注目されるのは、アウトカム定義においてだと思いますが、他の変数でも同様に妥当性の低さにより誤測定バイアスが生じるリスクはあるので、しっかりと検討しておきましょう。
先行研究を参考に、妥当と考えられる変数定義を作成し、もし先行研究がない場合には対応が必要です。
例えば、アウトカムのように特に重要な変数に関して標準化された定義方法がないのなら、自らアウトカム定義を作成し、Validation studyを実施するというように。
また、先行研究で変数定義が見つからない場合も、その分野の実臨床に詳しい医療者にヒアリングを行い、臨床知に基づいて妥当だと考えられる変数定義を作成することもあります。
なお、Validation studyが必要になる可能性が高い場合には、事前にValidation studyに協力してくれる医療機関があるか、必要な患者数の確保ができるか、定められた期間内に終了できるか、予算的に大丈夫かなどのアセスメントも必要になります(医療機関側のValidation studyの受け入れ可能性は非常に低いため、ここは絶対にデータベース研究の計画時点で確認しておくべきです)。
ちなみに上で述べた変数定義の妥当性に関しては、以下の記事で解説しています。
こんにちは、すきとほる疫学徒です。 データベース研究においては、曝露やアウトカムを定義するために設定した条件(アルゴリズム)が「本当に見たいものを正しく定義できているか」というアルゴリズムの妥当性を考える必要があります。 […]

Accessibility
データベース内外のデータにどれだけアクセスできるのか、という点もしっかり確認しましょう。
データベース内にデータがある=研究で使える、というわけではありません。
例えば、電子カルテデータの場合は病名、医療行為、薬剤、検査値データに加えてフリーテキストデータや、X線やCTなどの画像データを保管している可能性がありますが、それらが研究に使用できる状態に整備されているとは限りません。
また、データベースによっては外部の他のデータベースとの結合や、Prospectiveに集めたデータとの結合を実現できるデータベースもあります。
例えば、こちらのPep UpというサービスはJMDCさんが運営している健保の被保険者向けの健康管理サービスですが、このPep Upを使ってJMDCデータベースにない情報を被保険者から直接収集し、JMDCデータベースと組み合わせて使用するということも可能かもしれません。
「データベース内にデータがない=データベース研究は不可能」という時代ではなくなってきたということで、私は大きな感動を抱いております。
Level of detail
”病名データが入手できる”と一口に言っても、そのレベル感はデータベースによって様々です。
ですので、データベース研究の実現可能性を調査する際には、必ず”どのような詳細レベルでデータが入手できるのか”ということを、詳細に確認しましょう。
例えば、病名データに関しても、ICD-10 codeの下何桁まで入手できるのか、病名付与日、終了日は入手できるのか、それらの日付は本当に正確なのかというアセスメントが必要です。
同じ病名であっても、DPC様式1と診療報酬請求データとでは、まるで意味合いが変わってきます。
DPC様式1の場合は、病名を入院時病名、合併症、最も医療資源を投入した病名など様々に分類して定義しており、より正確に病名を把握することができます。
一方、診療報酬請求データの場合は、日本のプラクティスでは”過去の診療で一度付与された病名は、その後のレセプトに上がり続ける”、”医師が転帰を入力しない限りは、治療が終わっていてもactiveな病名として扱われ続ける(そして医師側に転帰を入力するインセンティブは乏しい)”などの事情があり、病名の妥当性は慎重に検討せねばなりません。
薬剤に関しても、一口に薬剤情報があると言っても、それが処方イベントだけなのか、容量や処方日数も分かるのか、処方目的も分かるのか、処方だけでなく調剤・内服も分かるのかなどレベル感が様々です。
こちらも病名同様に、実際に自分の目でRaw dataを、それが無理なら最低限、定義書を確認し、どこまでの粒度で情報を得ることができるのかを確認しておかねばなりません。
残念ながらデータベースの定義書というのは非常に複雑に作られていることが多く、どの項目が自分の欲しいデータに該当するかを判断することが難しいことも多々あります。ですので、データの定義書を確認する際には、必ずそのデータに詳しい方にコンサルをかけた上で、確認すべきでしょう。
データベースの選び方 ③Continuous and consistent data capture
Breaks or changes in data collection
データベース調査において一定期間の患者情報を収集する場合、その期間内にデータのコーディング方法や、保険システムが変わってしまう可能性があります。
例えば、診療報酬改定ですね。
改訂により、以前はA-101とコードされていた医療行為がA-100とコードされたり、そもそもその医療行為が保険算定から外れ、データベース上で記録されなくなるということもあります。
また、保険制度の変更により、後期高齢者保険に移行する年齢が75歳以上から65歳以上に変更になったり、生活保護の患者が保険でカバーされるようになったとすると、そもそものデータベースを構成するコホートが大きく変わる可能性があります。
特に生じやすいのが診療報酬改定によりコードの修正で、これは実際にデータベース研究をやっていると結構登場します。
私は普段、こちらのしろぼんネットを使って変数定義を作成することが多いのですが、会員限定版では過去の診療報酬バージョンの定義も確認できるため、重要な変数に関しては「本当にコードが変わってないかな?」ということを確認した方が安全でしょう。
https://shirobon.net/medicalfee/latest/ika/r02_ika/
Shared care
患者が複数の医療提供者からケアを受けているときに、その全てを把握できるかどうかということも重要です。
日本で薬剤疫学研究に使われるデータベースには大きく分けて2種類あり、
- 特定の医療機関から集めた医療機関ベースのデータベース
- 保険者、行政から集めたデータベース
です。
前者の場合は医療機関共通の患者IDが振られていませんので、患者が病院を変えたり、また同時期に他の医療機関から医療提供を受けている場合は追跡することができません(腰の痛みはAクリニック、高血圧はB病院とか疾患によって受診先を変えることって当然ありますよね)。
一方、後者では被保険番号を使って患者を特定できますので、複数医療機関からの情報を同一患者に紐づけることができます(National Databaseの場合はちょっとややこしい方法で患者を特定しているのですが、その話はここではしません)。
ですので、複数医療機関の情報を入手しなければならないリサーチクエスチョンや、患者を長期間追跡する必要があるリサーチクエスチョンですと、前者のデータベースでは実現可能性が低いということになってしまいます。
例えば、有害事象としてとある薬剤の乱用を調査したかったとしましょう。このとき、薬剤乱用を行う患者は、おそらく同時期に複数の医療機関を受診し、ダブって処方を受けている可能性が高いので、医療機関ベースのデータベースでは十分にアウトカムを特定することができません。
「じゃあ、保険者・行政データベース一択じゃん」と思うかもしれませんが、医療機関ベースのデータベースには検査値やDPC様式1などより詳細に患者データを把握できるデータが含まれていることが多く、やはりどちらのタイプのデータベースを優先するかはリサーチクエスチョン次第となります。
Exclusion of specific information
Capture of study variablesの項で述べたことを類似していますが、特定の変数が、特別な理由で欠損になっていないかどうか、という観点からのアセスメントです。
例えば、診療報酬請求データベースを用いる場合、当然ながら保険算定されないデータを入手することはできません。ですので、日本では保険算定されていない産前・出産・産後ケアや(異常がある際を除く)やワクチン接種を主たる曝露・アウトカムに設定したリサーチクエスチョンに対応することは非常に難しいでしょう。
また、何らかの精神疾患を抱える患者さんが、受診記録を保険に残したくないがために、保険外で精神科を受診することもあるかもしれません。
薬剤に関しては、もちろん保険算定外の市販薬(OTC)の情報は不明ですね。
よって、例えばターゲット薬と同クラスに属する薬剤がOTCでポピュラーに使われているような状態ですと、比較群の設定が難しかったり、定義できない曝露のcontaminationが起きてしまったりと、データベース研究の実現可能性に大きな影響を与えます。
Inconsistencies in data capture & Local drug policies
こちらはデータベースの実現可能性調査というよりは、”同じデータベースに含まれる患者でも、異なる医療プラクティスを提供されている可能性があるから、コホート内のバリエーションに注意しようね”というお話です。
例えば、疾患Aの確定診断を行う際に、医療機関Xはガイドライン記載の検査に加えて、独自の検査Zを行なっているだとか、本来は重症度別にオペAとオペBを使い分けなければいけないのに、医療機関YではオペBの経験がないため、常にオペAを行う、などですね。
データベースの選び方 ④Record length and latency
Record duration
患者の治療・アウトカムを拾うのに、十分な期間データが蓄積されているか、というお話です。
データベース全体の蓄積期間に加えて、着目しているコホートのIndex data前の追跡期間(Look-back period)やIndex date後の追跡期間(Follow-up period)がどの程度であるかを意識する必要があります。
例えば、とある薬剤のNew userを特定する際、Index date以前に十分なLook-back periodがなければ、「本当にIndex dateでの処方が初回処方か」ということが特定できず、曝露の誤測定に繋がります。
また、アウトカムとして癌の発症のように中長期の誘導期間・潜在期間が見込まれる疾患を対象にする場合は、Follow-up periodが3ヶ月しかとれない場合、アウトカムの誤測定に繋がります(4ヶ月目以降に癌を発症していても、3ヶ月の観察では発症なしとされてしまう)。
そのため、データベース研究を行う際には、着目しているコホートの平均Follow-up期間がどのくらいかということは確認すべきでしょう(New-user designの場合は平均Look-back periodも)。
Data latency
実臨床において診療報酬請求や電子カルテにデータが入力されてから、それがデータベースに集積され、研究可能な状態に整備されるまでにどれくらいのTime gapがあるか、というお話です。
例えば、「3ヶ月前に発売された薬剤の使用実態を知りたい」というリサーチクエスチョンがあっても(正確にはクリニカルクエスチョン)、データベースにデータが整備されるまでに6ヶ月のTime gapがある場合は、3ヶ月時点ではこのデータベースを用いた研究を行うことができません。
この観点で言えば、Covid-19のデータベース研究をやりたいと思っている人もヤキモキしている時間を過ごしたのではないでしょうか?
公衆衛生の観点からCovid-19のデータベース研究には迅速性が求められる一方、データが上がってくるまでには日臨床でのデータ入力から6ヶ月かかる、なんて状況下にいらっしゃった方もいるかもしれません。
私の知る限りですと、データベース事業者さんの中には、このTime gapをたった3ヶ月にまで縮めてらっしゃる事業者もあり、その企業努力に感服いたします。
終わりに
いかがでしたでしょうか?
今回は、ISPEのガイドラインをベースに、データベース選択や実現可能性調査においてチェックすべきポイントをまとめました。
第二章はこちら!
こんにちは、すきとほる疫学徒です。 医療大規模データベースを行う際に、 「沢山データベースがあるけど、どうやって選んだらいいの?」 「そもそもデータベース研究の実現可能性って、どうやって調べるの?」 […]

すきとほる疫学徒からのお願い
本ブログは、読者の方が自由に記事の金額を決められるPay What You Want方式を採用しています。
「勉強になった!」、「次も読みたい!」と本ブログに価値を感じてくださった場合は、以下のボタンをクリックし、ご自身が感じた価値に見合うだけの寄付を頂戴できますと幸いです。
もちろん価値を感じなかった方、また学生さんなど金銭的に厳しい状況にある方からのご寄付は不要です。
引き続き情報発信していく活力になりますので、ぜひお気持ちに反しない範囲でご寄付をお願い致します!






