

こんにちは、すきとほる疫学徒です。
本日は、薬剤疫学分野で観察研究を行う際に注意しなければならないバイアス、Prevalent user biasを取り上げ、その理論的背景、具体例、そして対処法について解説していきたいと思います。
Prevalent user biasは、薬剤の曝露を取り扱う際に生じるバイアスなのですが、このバイアスに限らず、薬剤疫学って曝露の取り扱いが本当に難しいですよね。
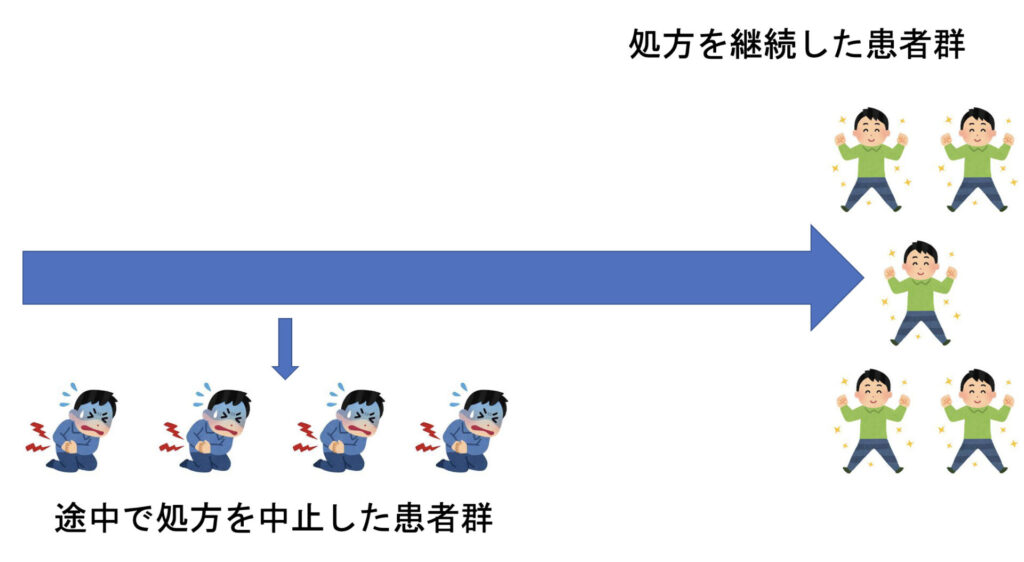
「よーいドン」でグループAとグループBが異なる二つの薬を飲み始め、追跡終了まで決められた期間、決められた分を毎回しっかり内服してくれるみたいな状況であれば、単純に初回の割り付けに従って2群比較を行えば良いのですが、もちろん現実はそんなに甘くありません。
薬剤Xを飲み始めても、数日で辞めてしまう人もいれば、比較薬であるYに切り替わる人、さらにそこからまたXに戻る人、何ならXとYを同時に処方される人、そして処方されても実際には内服しない人など、「現実は小説より奇なり」といった様相を呈しています。
因果推論を行うべく、こうした複雑怪奇な現実を、シンプルなモデルに落とし込まねばならないわけですが、起こりうるエピソードに沿ってバージョンA、B、Cなどと考えていくと、私のように脳みその容量が少ない人間にとっては、すぐオーバーヒートを起こします。
さて、そんな薬剤疫学の問題児である曝露の取り扱いにおいて、ひときわ有名であるPrevalent user biasについての解説を始めましょう。

「RWD研究の支援をしてほしい」というご相談を多くの企業様から頂戴するので、企業様向けに正式に窓口を設置しました。
以下のアドレスに連絡頂ければ私に直通しますので、「1時間の無料相談」も含めてお気軽にご連絡ください(3営業日以内にお返事させて頂きます)。無料相談は大変ご盛況となっており、先着順にて対応させて頂いております。
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
私が経営するmMEDICI株式会社ではRWD利活用支援を事業の柱の一つとしており、以下の強みを有しています。「企業の」RWD研究においては日本トップクラスの解像度と経験値を有する自信がありますので、ぜひ無料相談でご体験くださいませ。
- 元大手外資の日本・グローバル出身の疫学専門家が全案件を担当するので、「企業の」RWD研究に高い解像度を有しています
- ただ成果物を納品するだけでなく、グローバルやKOLとの合意形成、社内プレゼン、規制当局対応などRWD研究の「プロセス」も全てまきとれます
- 企業のRWD研究を幾度となく経験しており、企画立案から論文化までの全フェーズを一気通貫で対応できます
- アカデミアのRWD研究者と広い繋がりを有しており、必要に応じた専門人材のアサインが可能です
- RWD研究だけでなく、事業立案、マーケ、広報、営業などのRWDビジネスも全て対応可能です
以下に私の実績を記載させて頂きます。
- 大手外資製薬2社にて、部門唯一の疫学専門家として活動をリード
- 「RWDビジネスの教科書」の書籍を出版(サイドバーをご覧ください)
- 企業でのRWD研究の経験は50本以上
- 製造販売後データベース調査のリード経験多数
- これまで製薬、CRO、コンサル、総合商社、ヘルステックなど10社以上の企業のRWD研究・RWDビジネスを支援
- 50組織以上にRWD研修を提供
- 全体統括・講師を勤めたJapan RWD Summitでは初回から約1,700名の集客を実現
無料相談では、以下のような内容を含め企業様の「RWD」と名のつく相談でしたら全て対応させて頂きます。
- このテーマでRWD研究はできるの?
- RWD研究っていくらくらいかかるの?
- RWD研究ってどんなプロセスでやれば良いの?
- 製造販売後データベース調査のやり方を教えてほしい
- RWD研究をするにはどんな専門家を雇えば良いの?
- 自社のRWDサービスを売りたいんだけど、強みはどこ?集客はどうすれば良い?
無料相談は先着順での対応となりますので、ご希望の企業様はぜひお早めのコンタクトをお願い致します!
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
Prevalent user biasの具体例
皆さんの中には、「Prevalent user bias」って何?という方ももちろんいらっしゃると思います。
以下に、Prevalent user biasが生じている具体例を示しますので、「どんなバイアスなのか?」と推理しながらご覧になってみてください。
ちなみに、Prevalent userというのは、追跡開始前からその薬剤を使用し続けてきた人であり、日本語では既存処方者と呼ばれます。
スタチンと冠動脈疾患・死亡の関連について
スタチンが冠動脈疾患・死亡リスクを低下させることは、数多くのランダム化比較試験で証明されてきました。
しかしながら、観察研究においてはスタチンの効果に関して系統的レビュー、メタ解析が行われておりませんでした。
そのため以下の論文の筆者らは、スタチンの冠動脈疾患・死亡のリスク低減効果に関して観察研究のレビュー研究を行うとともに、Prevanet user biasの影響を可視化するため、観察研究側のコホートをPrevalent user, Incident user(新規処方者), その両方と層別化し、結果がどう変わるかを比較することにしました。
その結果、メタ解析における結果はスタチンの非薬剤使用者に対する死亡のハザード比は、以下のようになりました。。
- RCT: 0.84 (95%CI 0.77-0.91)
- Prevalent user and Incident user vs non user: 0.70 (0.64-0.78)
- Incident user vs non user: 0.77 (0.65-0.91)
- Prevalent user vs non user: 0.54 (0.45-0.66)
どの解析結果も、「Statinの使用により、死亡リスクが低下する」という結果を示していますが、曝露群の定義によりハザード比の点推定値及び95%信頼区間に差があることが分かります。
特に、RCTの結果をゴールドスタンダードとすると、Prevalent userを曝露群とした時の解析において、最もゴールドスタンダードと乖離した結果が示され、またIncident userを曝露群とした時の解析において、最もゴールドスタンダードに近い結果が示されました。
なぜこのようなことが起きたのでしょうか?
ぜひ、一度ここでスクロールを止め、理由を考えてみてください。
ホルモン補充療法と冠動脈疾患の関連において
Women’s Health Initiativeというランダム化比較試験では、ホルモン補充療法群とプラセボ群の間で、冠動脈疾患の発症リスクを比較しました。
その結果、プラセボ群と比較してホルモン補充療法群では投与開始2年間で68%、5、6年間で24%も冠動脈疾患のリスクが上昇するということが報告されました。
日本産婦人科医会が出した急告によれば1、この結果を受けて上記のランダム化比較試験は即刻中止になるとともに、当時米国では膨大な量のホルモン補充療法が行われていた背景を受け、全米の新聞やメディアで試験の結果が報告されたということです。
1: 社団法人日本産婦人科医会. 急告 ホルモン補充療法の適応変更に関する警告(米国)についての日本産婦人科医会の指針. 平成14年7月24日
一方、米国及びイギリスで別途行われていた大規模データベースを使った観察研究では、ホルモン補充療法群において冠動脈疾患のリスクが低減するという、上記のランダム化比較試験の結果とは真逆の結果が報告されていました。
下記の研究の筆者らは、このランダム化比較試験と観察研究の間にある矛盾が、観察研究が適切にデザインされていなかったことによるものだと考え、同じデータベースを用いて、異なるデザインで再度解析を行いました。
その結果、ホルモン補充療法の新規処方者 vs 非処方者という比較において、追跡2年後までの冠動脈疾患のハザード比は1.42 (0.92-2.20)となり、ランダム化比較試験の結果と同様のトレンドを示しました。
さて、ここで再び質問ですが、なぜこのようなことが起きたのでしょうか?
曝露群をPrevalent userにするか、Incident userにするかということで、研究結果にここまで大きな差が出るのはなぜなのでしょうか?
余談ではありますが、もしホルモン補充療法と冠動脈疾患の関連に対してRCTがいつまでも行われておらず、最初に行われた2つの観察研究の結果(ホルモン補充療法は冠動脈疾患のリスクを低下させる)に従って、処方行動が決定されてしまっていたと思えば、ゾッとしますね。
薬剤疫学に関わる者として、「不適切なデザインの薬剤疫学研究は、公衆衛生において甚大なる被害をもたらすリスクがある」と思い知り、身が引き締まる思いでした。
Prevalent user biasの解説
さて、2つの具体例を示したところで、いよいよPrevalent user biasの解説に入っていきましょう。
Prevalent user biasとは、「追跡開始前からすでに研究対象とする薬剤を使用していた人(Prevalent user)を曝露群に含めてしまうことで引き起こされるバイアス2」のことです。
2 佐藤俊哉、山口拓洋、石黒智恵子. これからの薬剤疫学 リアルワールドデータからエビデンスを創る
バイアスのカテゴリーで言えば、Selection bias(選択バイアス)に該当します。
Selection biasによる影響
さて、なぜPrevalent userを曝露群に含めてしまうと、上で紹介した2つの研究のように、曝露とアウトカムの因果関係が歪められてしまうことになるのでしょうか?
これは曝露群において、”薬剤を使い続けられた人”だけが選択的に選ばれてしまっているからです。
曖昧で意味わかりませんよね。
というわけで、具体的に説明してみます。
ちなみに、私がSelection biasについて理解を深められたのは、以下のkrskさんのブログのおかげですので、ぜひみなさんご覧ください。
https://www.krsk-phs.com/entry/selectionbias_epiecon
さて、具体的な説明でしたね。
例えば、
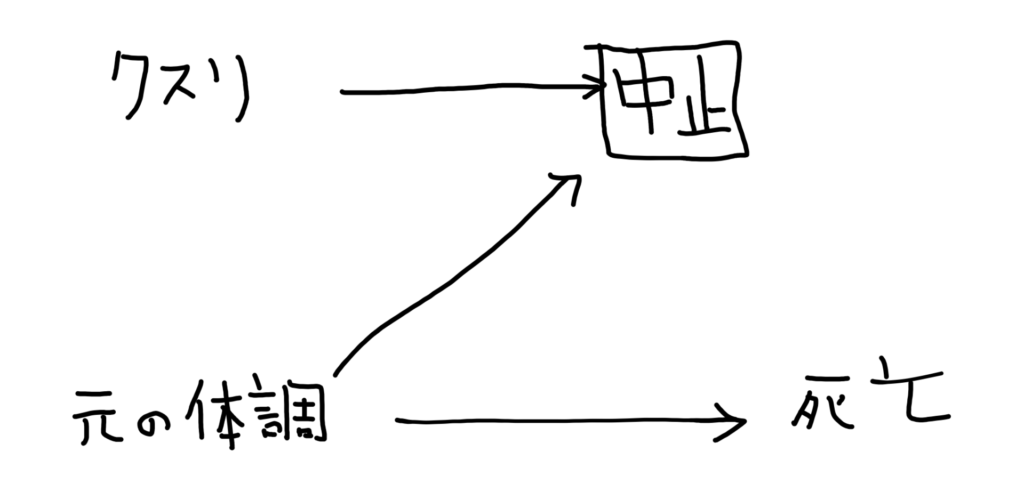
- 薬剤Xの内服は副作用をもたらす
- その人の元々の体調によっては薬剤Xの内服を中止せねばならず、さらに元々の体調は患者の死亡リスクに影響する
というような条件があったとしましょう。
この時、薬剤Xを内服し続けられた人(Prevalent user)とは、どんな人たちでしょうか?
そうです、「副作用があっても薬剤Xを飲み続けられるほど、元々の体調が良かった人たち」ですね。
こういった患者を、薬剤Xの副作用に対してless susceptible(感受性が低い)な患者である、と呼びます。
こちらは薬剤安全性の例でしたが、有効性に対しても同じことが言えます。
- 薬剤Xの内服は特に良い効果をもたらさない
- その人の元々の体調によっては薬剤Xの内服を注視せねばならず、さらに元々の体調は患者の死亡リスクに影響する
という条件があったとすると、薬剤Xを内服し続けられた人とは、「効果がないにも関わらず薬剤Xを飲み続けられるほど、元々の体調が良かった人たち」と言うことができます。
ちなみに、上記のようにベースラインの体調が良い患者を、薬剤疫学ではHealthy userと呼びます。
上記の関係をDAGにすると、こんな感じですね。
これを踏まえれば、最初に紹介したスタチン、ホルモン補充療法の2研究で、なぜPrevalent userを曝露群にした解析で、ゴールドスタンダードであるRCTの結果と乖離した(しかもfavorable to スタチン/ホルモン補充療法な)結果が示されたのか納得頂けるでしょう。
そうですね。
スタチンやホルモン補充療法を処方された患者のうち、有害事象を起こした/そのリスクが高い患者というのは早々に研究から離脱しており、Prevalent userとして曝露群に含まれたのは「スタチンやホルモン補充療法を継続して受け続けられるほど健康な患者(Healthly user)」だったからです。
Prevalent userというのは、スタチンやホルモン補充療法を処方された全患者を代表する患者ではないわけですから、その結果を持ってして「全てのスタチン、ホルモン補充療法を処方された患者では、冠動脈疾患のリスクが下がる」と言ってしまうと、間違いであるということがお分かり頂けるかと思います。
中間因子を解析に含めることの影響
さて、上記ではPrevalent userを使用することのデメリットをSelection biasの観点から説明してきましたが、他にもデメリットがあります。
それは、曝露とアウトカムの中間因子を解析に含めてしまう可能性があるということです。
中間因子とは、mediation factorと呼ばれる変数であり、これを解析に含めてしまうことで、曝露とアウトカムの因果関係が正しく測定できないという性質を持ちます。
なぜ、Prevalent userを用いることで、中間因子が解析に含められてしましょうのでしょうか?
それは、交絡因子調整のために解析に投入されたPrevalent userの背景因子が、実は既に曝露の影響を受けている中間因子である可能性があるからです。
具体的に説明しましょう。
例えば、「薬剤Xは非使用者と比べて冠動脈疾患のリスクを抑制するかどうか」というリサーチクエスチョンで研究を行い、曝露群には薬剤XのPrevalent userを使用したとしましょう。
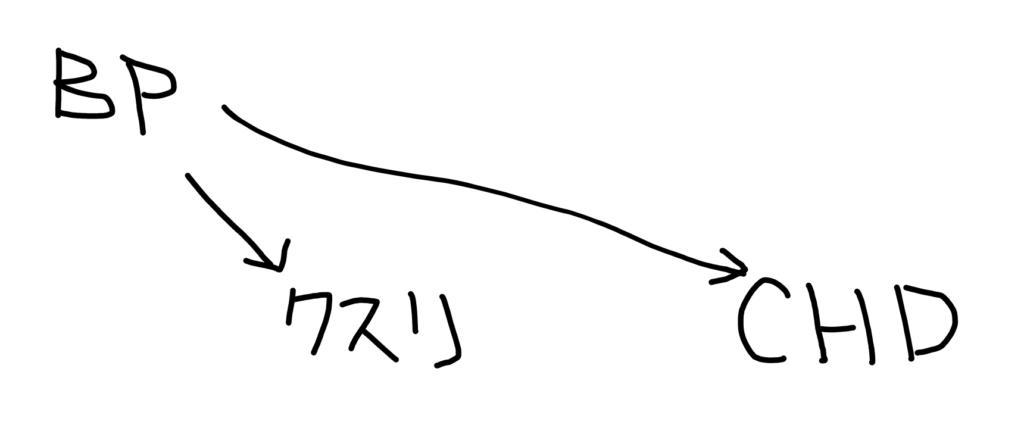
この時、血圧は冠動脈疾患のリスクに影響するPredicorであるため、交絡因子を調整するべく解析に投入したとします。
なお、血圧は患者の追跡開始時点であるIndex date以前の半年間に測定された数値を用いるとしましょう。
この時、薬剤Xは患者の血圧にも影響を与える可能性があったとします(薬剤Xは冠動脈疾患のリスクを影響する可能性があるのならば、血圧に影響する可能性も十分ありそうです)。
すると、交絡因子だと思い解析に投入した血圧が、実は薬剤Xの影響を受けている中間因子であるということになり、曝露とアウトカムの因果関係を歪めてしまうことになります。
こう(BPが交絡因子)ではなく
こう(中間因子)だったということですね。
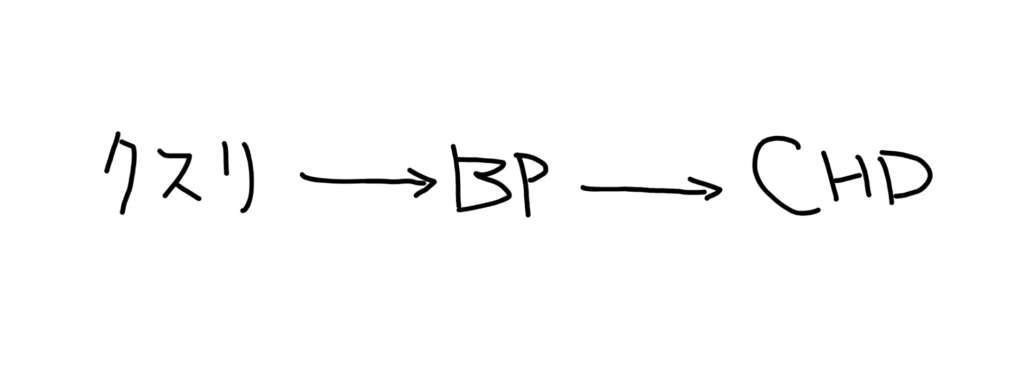
これが、Prevalent userを使用することのデメリットの2つ目です。
曝露の定義が曖昧になってしまう影響
最後は、Prevalent userにおいて曝露の定義を明確にできないことによる影響です。
これは、薬剤の曝露期間や累積曝露量によりアウトカムの発生リスクが変化する際に生じます。
薬剤Xと有害事象Yの関連を調べる際に、薬剤Xを10年使用した患者と半年使用した患者、1000回した患者と1回使用した患者では、おそらく有害事象Yのリスクは変わってくるかもしれない、と想像することに違和感はないでしょう(もちろん、曝露期間・曝露量と有害事象のリスクが比例しない薬剤も存在すると思いますが)。
このような状況下では、薬剤Xの曝露を定義する際、過去の曝露期間・累積曝露量を正確に把握せねばなりません。
しかしながら、Prevalent userの中には、医療データが存在する最初の時点で既に薬剤Xの処方がされている患者もおり、この場合は一体いつから、どれだけ薬剤Xを処方されてきたのかを特定することが難しくなります(医療データの存在以前にも処方が行われていた可能性としては、例えば医療データに含まれない他院で処方されていた、その患者の保険者がデータに参入する前から処方されていた、などですね)。
このように曝露定義が曖昧になることのデメリットは、新薬と既存薬を比較する際に特に顕著になるでしょう。
日本の制度では、薬剤が市場で販売された後も、引き続きその安全性を監視し続けることが製薬企業に義務付けられています。
そのため、新薬の安全性の評価として、新薬と既に販売されている既存薬の間で有害事象のリスクを比較することがあります。
仮定として、同量の新薬・既存薬の同期間投与は、同じだけ有害事象のリスクを上昇させるとしましょう。
つまり、薬剤の曝露期間・累積曝露量以外には、新薬・既存薬間で有害事象のリスクに差はないという状況です。
この時、新薬 vs 既存薬のPrevalent userという比較を行なってしまうと、新薬に対してfavorableな解析となってしまいます。
なぜなら、新薬は市場に出た直後であるから曝露期間・累積曝露量がほぼ0であるのに対し、Prevalent userは長年曝露を受け続けている可能性があるからです。
例えば、発売されたばかりの新薬と、10年前から使われている既存薬の比較において、既存薬のPrevalent userをもちいたとしましょう。
この時、新薬・比較薬ともにInduction period(薬剤の初回使用からアウトカムが発生するまでの期間)が5年だとします。
すると、新薬群では少なくとも追跡5年目まではアウトカムが発生しない一方で、既存薬群では以前より薬を使い続け、Induction periodが既に経過している患者もいるでしょうから、追跡開始当初からアウトカムが発生してもおかしくありません。
そのため、既存薬群において見かけ上のハザード比が高くなってしまうというバイアスがかかります*。
*この時同時に、既存薬群では「アウトカムとして有害事象を発生した患者は早々に薬剤を使用中止し、less susceptibleな患者のみ残ってしまっている」というfavorable to 既存薬なバイアスもかかっています。
このように、Prevalent userはデータが存在する以前から曝露を受け続けている可能性があり、その情報を適切に曝露定義に組み込むことが困難なため、曝露定義が曖昧になってしまうというデメリットがあるのです。
Prevalent user biasへの対処法
さて、ここまで
- Prevalent user biasの具体例
- Prevalent user biasとは何か
- Prevalent user biasはどんなデメリットをもたらすのか
ということを解説してきました。
ここからは、
どうすればPrevalent user biasに対処できるのかということを解説していきたいと思います。
対処法となるデザインは、大きく2つ存在します。
Incident new user design
一つ目は、Incident new user designです。
これは、2つの薬剤を比較する際に、双方の患者を「新規に薬剤を使用し始めた患者(naïve to treatment Xのように表現することがあります)」に限定するというデザインです。
Prevalent user biasは、「既存薬を使用し続けることができた患者のみがコホートに残ることによりバイアス」ですので、新規使用者に限定してしまえば、このバイアスは起こりませんよね。
また、よーいドンで2群間の新規の薬剤使用時点から追跡を開始するので、Prevalent user designの時のように、「Prevalent userのみ曝露期間・累積曝露量が多い」といった不均衡も生じません(Target trialというコンセプトにおける、Time-zeroとFollow-upが一致している状態です*)。
*詳しくは、同じくkrskさんのこちらのブログをご参照ください。
https://www.krsk-phs.com/entry/target.trial
医療大規模データベースを用いて「新規使用者」を定義する方法はいくつかありますが、よく使われているのは、薬剤処方時点から6-12ヶ月前を振り返り、そこで同薬が処方されていなければ、「新規使用者」とみなすという定義です。
Washout periodについて
ちなみに、ここで振り返っている期間を、Washout periodと表現します。
余談ですが、「薬剤疫学で6-12ヶ月のWashout periodが使われてるけど、それ妥当なん?確かめるわ」というモチベーションで行われた以下の研究があり、その結果、Incident userと定義された患者のうち、6ヶ月定義では半分が、12ヶ月定義では30%が実はIncident userではなくPrevalent userであり、曝露の誤測定に繋がっていたということが報告されました。筆者らは6-12ヶ月のWashout periodでは正しくIncident userを特定するには不十分なのではないかと結論しています。
例えば、SSRIs使用者のうちの自殺発生率を計算した以下の研究では、SSRIsのIncident new userを対象にしていますが、Washout periodを1年間にしたPrimary analysisでは自殺発生率が6.03 per 1,000 person years (95% CI: 5.54-6.55)、そしてWashout periodを3年間にしたSecondary analysisでは5.18 per 1,000 person years (95% CI: 4.65-5.75)と、わずかに1年間の方で自殺発生率が高い結果となりました。
この結果を見ると、Incident user designを用いる場合は、複数のWashout periodを設けて、幾つか追加解析をすることで、解析の妥当性を示した方が良いかもしれません。
なお製薬企業が行う薬剤疫学では、薬剤上市後の安全性調査がありますが、この場合は新薬の販売以前には絶対に新薬が処方されている患者はいないわけですから(治験、自由診療を除き)、Incident new userを短いWashout periodで特定できるという強みがあります。
同クラスの既存薬使用の扱いについて
Washout periodの他に、Incidnet new userを選択する際に考えねばならないこととして、同クラスの薬剤の使用をPrevalent useとみなすかどうかということがあります。
・同クラスをPrevalent useと見做す場合
こちらはシンプルな考え方で、ターゲットとする薬剤Aと同じクラスに属する薬剤が過去に使用されていたら、その患者はPrevalent userとみなし、Incident userからは除外するという方法です。
これによりIncident userとなるのは、「ターゲットとする薬剤A及びそのクラスの薬剤を過去に使用していない患者」となります。
・同クラスをPrevalent useと見做さない場合
こちらはちょっと複雑で、同クラスの薬剤使用はPrevalent useと見做さない、つまり、過去に同クラスの薬剤が使用されていたとしても、ターゲットとする薬剤自体が使用されていなければ、Incident userとするという方法です。
例えば、リウマチに対するTNF阻害剤の効果を測定するための研究を、Incidnet user designを用いて行いたかったとしましょう。この時、殆どのリウマチ患者は過去にDMARDsを使用していたとします。
この時、同クラスの薬剤師用はPrevalent useと見做されないため、TNF阻害剤のIncident userには、過去にDMARDsを使用していた患者を含めることができます。
すると、殆どのTNF阻害剤のIncident userが、DMARDsからのswitchingを受けた患者と言うことができるでしょう。
おそらく彼らは、「1次治療であるDMARDsで十分な効果を得られなかったから(もしくは強い副作用を経験したから)、2次治療としてTNF阻害剤へ移行せざるを得なかった患者」です。
この時、対照薬であるリウマチ治療薬が1次治療、2次治療の双方で用いることができる薬剤だとすると、TNF群は2次治療以降のより重症なリウマチ患者である一方で、対照薬では1次治療・2次治療が混在した軽〜重症のリウマチ患者となり、背景の患者重症度のバランスが崩れてしまいます。
よって、同クラスの薬剤使用をPrevalent useと見做さない場合には、治療ラインをそろえた上で比較するという工夫が必要になります。
Incident new user designの欠点について
さて、ここまではIncident new user designのメリットを紹介してきました。
これだけ良いことづくりですと、もしかすると「え、ならIncident new user design一択じゃん、Prevalent user designなんて使うわけないよ」と感じる方もいらっしゃるかもしれません。
しかしながら、Incident new user designにもデメリットが存在しています。
サンプルサイズの減少
まず、Incident new user designでは過去に同クラス・同薬剤を使用した患者を除外するわけですから、サンプルサイズが大きく減少します。
例えば、Washout periodの解説で紹介した研究では、Washout periodを6ヶ月、12ヶ月にすることで、それぞれ75%、85%もの患者が除外されてしまいました。
これは特に、”既に多くの患者で一般的に使用されている薬剤(例えばワルファリンなど)”をターゲットとした研究を行うときに発生する問題です。
その薬剤を使うことが標準治療となっているのだとしたら、Incident new userは「新規のその薬剤を使用する疾患に罹患した患者」しか対象にできなくなります。
長期の薬剤有効性・安全性を追跡できなくなる
薬剤の初回投与から、実際にアウトカムが観察できるようになるまでは一定の時間がかかります。
これを、Induction period(初回投与から発現まで)とLatent period(発現から観察可能まで)と呼び、薬剤の有効性・安全性を調査する場合には、薬理動態や治験の結果に応じて、アウトカムが観察可能になるまでの十分な追跡期間を設定しなければなりません。
例えば、アウトカムが薬剤性アレルギーであれば、数日の観察期間で十分かもしれませんが、癌であれば数年間の観察期間が必要でしょう。
仮に、Induction period + Latent period = 10年という状況でIncident new user designを使用すると、理論的には全ての患者に対して最低10年間の追跡を行わなければなりませんので、現実的に研究をすることが不可能になってしまいます。
研究結果の一般化可能性が下がる
Incident new user designでは、「Index date以前に同クラス、もしくは同薬剤の使用がない患者のみを対象とする」のでしたよね。
よって、過去に同クラス、同薬剤を使用した経験のある患者は全て解析から除外されてしまいます。
しかしながら、現実には「これまで使っていた薬剤Aの効果がいまいちだから、新しく薬剤Bに切り替えよう」という選択をする患者は山ほどいるわけです。
特に、既存薬が長く、標準治療として使われている状況ならなおさらですね。
この時、患者をIncident new userのみに限定してしまうと、それらの”一般的な患者”が全て解析から除外されてしまうことになり、非常に限定的なコホートで研究を行うことになってしまいます。
例えば、新薬である抗凝固剤Aをターゲットとした比較研究を行うときに、新薬群として過去に全ての抗凝固剤を使用した患者を除外したとしましょう。しかしながら、実臨床では新薬を処方された患者の80%が過去に他の抗凝固剤を使用していたとすると、この研究で見ることのできる新薬Aの有効性・安全性は実臨床の患者像に当てはめることができなくなってしまうかもしれません。
Incident new user designのまとめ
さて、Prevalent user designがもたらすバイアスへの対処として、Incident new user designを紹介してきました。
Incident new user designを使用することで、研究の内的妥当性は上昇するが(バイアスを低下させることができる)、一方で外的妥当性や正確性(precision)が低下するということがお分かり頂けたかと思います。
なお、Incident new userについては以下の論文でよくまとめられておりますので、お時間ある方はご一読されると良いかもしれません。
こうしたIncident new user desingの使いどころの難しさを受けて、新たに提案された研究デザインがあります。
それが、次にご紹介するPrevalent new user designです。
Prevalent new user designについて
なんだか、Prevalent user designとIncident new user designが混ざったような名前ですよね。
なお、本項は以下の論文に基づいて執筆されており、途中に出てくるFigureも同論文からの引用となります。
私が初めてこのコンセプトを知ったときには、「PrevalentでNewなuserって何だよ!」と一人で突っ込んでいました。
でもこの名前の通り、Prevalent new user designとは、Prevalent user designとIncident new user designの間の子のようなデザインになっています。
例えば、新薬Aと以前から使用されている薬剤Bとの間で薬剤有効性を比較する場合、Prevalent new user designでは、薬剤Bから新薬Aにスイッチした患者も”新薬AのNew user”としてコホートに含めることを許容します。
Prevalent new user designでは、まずBase cohortとして以前から使用される薬剤Bを使用していた患者を特定し、
新薬Aにスイッチした患者 vs 薬剤Bに残存し続けた患者
からなるExposure setを形成します。
「いやいや、ちょっと待て」と思われる方もいるでしょう。
Prevalent user designでは、「薬剤を使い続けられた患者のみを対象としてしまう」ことで選択バイアスが起きていたので、ここでも薬剤Bに残存し続けた患者を対象にすると、同じく選択バイアスが起こってしまうように感じますよね。
このバイアスを軽減するため(完全にゼロにはできない)、Prevalent new user designでは、以下の2種類の方法のいずれかで、新薬Aと薬剤BからなるExposure setを形成します。
・Time-based exposure sets
これは、過去に薬剤Bに曝露した期間で、新薬Aと薬剤Bの患者をマッチングするという方法です。
薬剤Bの曝露期間がアウトカム発生により強く影響するという状況で使用されます。
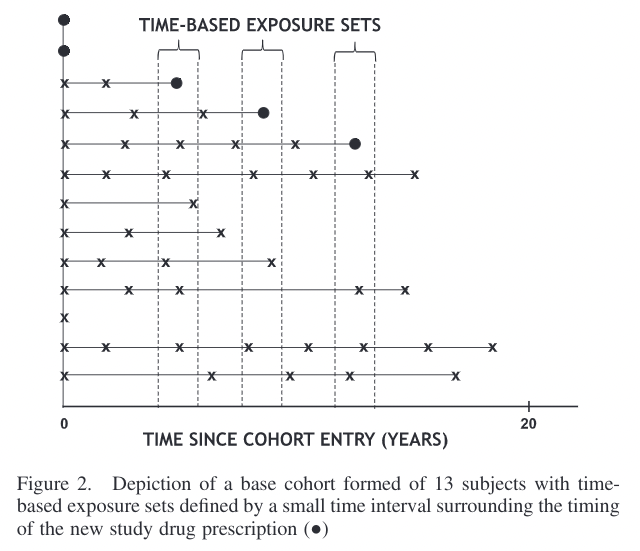
●が新薬Aの使用、×が薬剤Bの使用を表します。
X軸がBase cohortに追加されてからの期間です。
これを見ると、新薬Aの使用●に対して、Base cohortへの追加期間が同じになるように薬剤B×の使用が選択されている(薬剤Bではマッチング時点をIndex dateにする)ことがお分かり頂けると思います。
つまり、先に述べたように過去の薬剤Bへの曝露期間で、新薬Aへのスイッチ患者と、薬剤Bへの残存患者をマッチングしたExposure setsを作成しているわけですね。
これにより、マッチングされた新薬A・薬剤B患者群において
- 薬剤Bを使用し続けられた患者(Healthy user)
- 薬剤Bへの曝露累積期間効果が同レベルの患者
という観点でバランシングが行えていることになります。
・Prescription-based exposure sets
Exposure setsの作成方法の2つ目は、薬剤Bへの曝露期間ではなく、曝露量でマッチングを行う方法です。
薬剤Bの曝露期間よりも、曝露量がアウトカム発生により強く影響するという状況で使用されます。

●が新薬Aの処方、×が薬剤Bの処方、そして○×を組み合わせたマークがIndex dateとなる薬剤Bの処方です。
X軸は曝露期間ではなく、Base cohortに組み入れられて以降の処方回数となっています。
これにより、マッチングされた新薬A・薬剤B患者群において
- 薬剤Bを使用し続けられた患者(Healthy user)
- 薬剤Bへの曝露累積量効果が同レベルの患者
という観点でバランシングが行えていることになります。
さて、Time-based/Prescription-based exposure setsの説明において、新薬Aと薬剤B患者群でマッチングを行う、と述べてきました。
では、一人の新薬Aの患者に対して、薬剤Bへの曝露期間・量が同じ患者が複数人いる場合はどのようにマッチング相手を選択すれば良いでしょうか?
ここでのマッチングは、比較を行う両群間でのComparavility(比較可能性)を上昇させる目的で行われていますので、より背景が類似した患者をマッチングした方が目的に叶うことになります。
そのため、マッチングにおいては”新薬Aへの切り替え”をアウトカムにした、時間変容性プロペンシティスコアを作成し、そのスコアが近似した患者間でマッチングを行うことが多いとされています。
Prevalent new user designの注意点について
Prevalent new user designを用いる際にも、幾つか注意せねばならない点があります。
アウトカム発症者を除外することについて
多くのコホート研究では、ターゲットとするアウトカムを過去に発症した患者はコホートから除外することがあります。
例えば、薬剤Xと大腸癌の因果関係を調べたい際に、過去に大腸癌を発症した患者は除外する、などです。
この方法は、RCTやIncident new user designの際には妥当でしょう(過去に大腸癌を発症した患者は、新規の大腸癌発症者とは背景因子が大きく異なる可能性があるため、コホートのhomogeneityという観点からは除外するのが妥当です)。
しかしPrevalent new user designでこれをやってしまうと、選択バイアスが生じる可能性があります。
Prevalent new user designでは、薬剤Bの既存使用者をBase cohortとし、マッチング時点をIndex dateとするのでしたね。このとき、RCTやIncident new user desigと同じモチベーションでIndex date以前のターゲットアウトカムの発症を経験(既往歴)した患者を除外してしまうと、実はその疾患の発症は既往歴ではなく、カウントすべきアウトカム発症であったという状況が発生し得ます。
となると、薬剤Bの患者群から系統的にアウトカムの発症者を除外してしまうので、favorable to 薬剤Bなバイアスが発生してしまいますね。
なお、以下の論文がこの状況を具体的に説明しています(First authorはPrevalent new user designの論文を書いた方と同じで、Suissaさんです。McGill大学の先生で、薬剤疫学領域で面白い論文を大量に出しているので、ぜひPubmedで検索してみると良いかもしれません)。
筆者らは、メトフォルミンが癌発現にもたらす因果効果を特定するために、メトフォルミンの新規使用者と非使用者を糖尿病の診断年でマッチングすることでコホートを作成しました。
Index dateとして、メトフォルミン使用者は初回使用日を、そし非使用者はマッチされたメトフォルミン使用者とコホートへの登録期間が同期間になるよう日を設定しています。
このとき、両群において既往歴として癌を有する患者を除外しました。
しかしながら非使用者においては、「マッチングの候補として選択された非使用者が、そのマッチングのIndex date以前に癌の既往歴を有していた場合はマッチングから除外するが、その非使用者は他のメトフォルミン使用者とのマッチングには使用できる」というReplacementを条件にマッチングを行ってしまいました。
例えば、コホート登録から10ヶ月後に癌を発症した非使用者Aがいたとします。
このとき、コホート登録から12ヶ月目にメトフォルミンを使用した患者に対し、非使用者Aがマッチング候補となった場合は、Index dateである12ヶ月目以前(10ヶ月目)に癌を発症しているため、癌の既往歴ありとしてマッチング候補から外れます。
しかし、非使用者Aが再びコホート登録6ヶ月目にメトフォルミンを使用した患者のマッチング候補となった場合には、非使用者Aの癌発症はIndex dateである6ヶ月目以降となるため、マッチングに組み入れられることになります。
これにより、どんなバイアスが生じるでしょうか?
まずメトフォルミン使用群に関しては、Index date以前に癌を発症した患者は全て解析から除外されます。
一方で、非使用群においては癌を発症した患者であっても、Replacementを繰り返すことで、いずれマッチングに組み入れられ、メトフォルミン使用群では既往歴として除外されていた癌が、アウトカムとしてカウントされることになります。
これにより、非使用群における見かけ上の癌発症リスクが上昇してしまうことになったのです。
上記の選択バイアスを防ぐためには、いくつかの工夫が必要です。
まず、マッチングを実施する際には、Base cohortにおけるアウトカムの発症、発症時期をブラインド(盲見化)した状態で行うということです。
ブラインドなしでのマッチングを許容すると、恣意的な既存薬使用者の選択が可能になってしまうからですね(例えば、有効性を示したい新薬Aと既存薬Bの比較を行う場合、Index date以降にアウトカムを発症した既存薬B患者を積極的にマッチングすることで、既存薬Bで見かけ上のアウトカム発症が多く出ているようにするなど)。
次なる方法は、プロペンシティスコアを計算し、マッチングを行う段階では、既存薬使用者のReplacementを行わないということです。
上記のメトフォルミンの例では、癌の既往歴がある非使用者のReplacementを許容してしまったため選択バイアスが起こりましが、それを許さず、一度でもマッチングから外れた既存薬使用者は、永遠にマッチングから除外するということですね。
同様に新薬Aの使用者においても、ターゲットアウトカムを既往歴として持つ患者をマッチング以前に全て除外してしまってはいけません。なぜなら彼らの既往歴は、新薬にスイッチされる前の既存薬におけるアウトカム発症である可能性があるからです。これらの患者を除外してしまうと、既存薬におけるアウトカム発症を経験した患者が系統的に除外され、既存薬における見かけ上のアウトカム発症のリスクが低くなってしまいます。
Prevalent new user designでもSelection biasを完全には削除できないことについて
Prevalent new user designでは、比較薬となる既存薬への過去の曝露期間・量を新薬(既存薬から新薬へのスイッチ)群・既存薬群間で揃えることで、Selection biasを低減させることを目指していました。
たとえば、既存薬投与10ヶ月目に新薬にスイッチした患者に対し、同じく既存薬投与10ヶ月目をIndex dateとする既存薬患者をマッチングしたとしましょう。
このとき、両群での既存薬の累積投与期間もしくは量は一致します。
また、「既存薬を使用し続けられなかったことによる脱落」の程度もある程度は一致するでしょう。
しかしながら、結局は新薬群はIndex dateにおいて既存薬から新薬へのスイッチを経験しているわけで、これはもしかすると「既存薬を使用していて有害事象を経験した」かもしれませんし、「既存薬では十分対処できないほど疾患が悪化した」からかもしれません。
となると、やはり新薬・既存薬の群間で疾患重症度や、有害事象への感受性(susceptibility to adverse event)に差が出てしまい、バイアスをもたらすことになってしまいます。
よって薬剤選択に伴うSelection biasを完全に避けるためには、やはりIncident new user designを使用するしかない、ということになります。
Cohort組み入れ前の既存薬への曝露期間・量が不明なことについて
Exposure setsの説明で用いたこちらのFigureを改めて見てみましょう。
Cohort entry時点での既存薬への曝露を許容していますね。
これはつまり、Cohort entry以前の既存薬への曝露期間・量が不明であってもCohortに組み入れることができることを意味しています。
これによりどんな問題が生じるでしょうか?
もし、Cohort entry以前の既存薬への曝露期間・量が新薬へのスイッチ群・既存薬残存群でnon-differentialという仮定が成立するならば、この組み入れは問題ないでしょう。
しかしながら、もしdifferentialな差異があったとすると、やはりこれはPrevalent user biasの時と同様に、新薬もしくは既存薬群のどちらかで系統的に既存薬への曝露期間・量が多いということになり、Selection biasをもたらすことになります。
終わりに
さて、いかがでしたでしょうか?
薬剤疫学分野の観察研究で見られるバイアスとしてPrevalent user biasを紹介し、その対処法としてIncident new user design、そしてPrevalent new user designの2つを紹介しました。
内的妥当性という観点からは、両群を完全に新規使用者に限定したIncident new user designがゴールドスタンダードとして推奨されています。
しかしながら説明した通り、Incident new user designを用いることで、大きくサンプルサイズが減ってしまう、コホートが実臨床の患者像と大きく乖離してしまうなど、弊害が極端に大きい場合には、Prevalent new user designを使用することを検討した方が良いでしょう。
個人的には、いずれかの解析をPrimaryに置き、感度分析としてもう片方を実施し、結果を比較するというアプローチがより安全だと感じています。
以上、長くなりましたが、本日もお読みくださりありがとうございました。
すきとほる疫学徒からのお願い
本ブログは、読者の方が自由に記事の金額を決められるPay What You Want方式を採用しています。
「勉強になった!」、「次も読みたい!」と本ブログに価値を感じてくださった場合は、以下のボタンをクリックし、ご自身が感じた価値に見合うだけの寄付を頂戴できますと幸いです。
もちろん価値を感じなかった方、また学生さんなど金銭的に厳しい状況にある方からのご寄付は不要です。
引き続き情報発信していく活力になりますので、ぜひお気持ちに反しない範囲でご寄付をお願い致します!






