

こんにちは、すきとほる疫学徒です。
長かった薬剤曝露シリーズが終わり、次なるテーマとして薬剤アウトカムシリーズに入っていきたいと思います。
このシリーズでは、アウトカムの誤測定がもたらす影響、誤測定を減らすための妥当性研究、PMDAによる妥当性研究のガイドラインなどに触れていくことで、「薬剤疫学研究において、なぜより正確なアウトカム定義を用いねばならないのか、そしてどうすれば正しいアウトカム定義を用いることができるのか」ということをお伝えしていきたいと思っています。
シリーズの第一回である今回は、アウトカムの誤測定が薬剤の因果効果の推定においてどのような影響を与えるのかということを解説します。
・アウトカムの誤測定が因果効果推定に与える影響

「RWD研究の支援をしてほしい」というご相談を多くの企業様から頂戴するので、企業様向けに正式に窓口を設置しました。
以下のアドレスに連絡頂ければ私に直通しますので、「1時間の無料相談」も含めてお気軽にご連絡ください(3営業日以内にお返事させて頂きます)。無料相談は大変ご盛況となっており、先着順にて対応させて頂いております。
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
私が経営するmMEDICI株式会社ではRWD利活用支援を事業の柱の一つとしており、以下の強みを有しています。「企業の」RWD研究においては日本トップクラスの解像度と経験値を有する自信がありますので、ぜひ無料相談でご体験くださいませ。
- 元大手外資の日本・グローバル出身の疫学専門家が全案件を担当するので、「企業の」RWD研究に高い解像度を有しています
- ただ成果物を納品するだけでなく、グローバルやKOLとの合意形成、社内プレゼン、規制当局対応などRWD研究の「プロセス」も全てまきとれます
- 企業のRWD研究を幾度となく経験しており、企画立案から論文化までの全フェーズを一気通貫で対応できます
- アカデミアのRWD研究者と広い繋がりを有しており、必要に応じた専門人材のアサインが可能です
- RWD研究だけでなく、事業立案、マーケ、広報、営業などのRWDビジネスも全て対応可能です
以下に私の実績を記載させて頂きます。
- 大手外資製薬2社にて、部門唯一の疫学専門家として活動をリード
- 「RWDビジネスの教科書」の書籍を出版(サイドバーをご覧ください)
- 企業でのRWD研究の経験は50本以上
- 製造販売後データベース調査のリード経験多数
- これまで製薬、CRO、コンサル、総合商社、ヘルステックなど10社以上の企業のRWD研究・RWDビジネスを支援
- 50組織以上にRWD研修を提供
- 全体統括・講師を勤めたJapan RWD Summitでは初回から約1,700名の集客を実現
無料相談では、以下のような内容を含め企業様の「RWD」と名のつく相談でしたら全て対応させて頂きます。
- このテーマでRWD研究はできるの?
- RWD研究っていくらくらいかかるの?
- RWD研究ってどんなプロセスでやれば良いの?
- 製造販売後データベース調査のやり方を教えてほしい
- RWD研究をするにはどんな専門家を雇えば良いの?
- 自社のRWDサービスを売りたいんだけど、強みはどこ?集客はどうすれば良い?
無料相談は先着順での対応となりますので、ご希望の企業様はぜひお早めのコンタクトをお願い致します!
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
アウトカムの誤測定とは何か
アウトカムの誤測定とは、真のアウトカムと、測定したアウトカムの間にズレが発生してしまうことを指します。
状況によって”真のアウトカム”が何か、”測定したアウトカム”が何かというのは変わりえますが、今回は医療大規模データベース研究を焦点にして、
真のアウトカム:電子カルテレビューによって判定されるアウトカム
測定したアウトカム:レセプトデータ上のアウトカム
とします。
臨床経験がある方からしたら言わずもがなかもしれませんが、この2つのアウトカムは必ずしも一致しません。
具体的に説明しましょう。
例えば、手術Aを実施する際にルーティーンで輸液投与を行う際、日本の保険制度上は輸液を投与する何らかの理由(疾患)が必要になります。そのため、レセプト上は”脱水”病名を付与することがありますが、患者は実際に脱水になっているわけではありません。
これは、「測定したアウトカム(レセプト)上は病名が存在するが、真のアウトカムではない」、つまり偽陽性による誤測定です。
偽陽性の他の例としては、癌の疑いがある患者に対して検査をするため、”癌疑い”病名をつけたが、結果的に癌ではなかった。しかし癌疑い病名を削除せず、そのままレセプトに残り続けたという状況もあり得ます。
偽陽性と来たので、次は偽陰性ですね。
例えば、心筋梗塞で入院した患者が既往歴としてうつ病を有していたとしましょう。
持参の抗うつ薬が充分量あったので、入院期間中には医師はうつ病に対していずれの薬剤の処方も行いませんでした。抗うつ薬を処方する際には、それに紐づく病名としてうつ病をレセプトに入力する必要がありますが、今回は処方を行わなかったため、医師はあえてうつ病をレセプトに入力することはしませんでした。
この時、「測定したアウトカム(レセプト)上は病名が存在しないが、真のアウトカムは存在する」、つまり偽陰性による誤測定が起こっています。
なぜレセプトデータを用いた医療大規模データベース研究でこのような測定したアウトカムと真のアウトカムの間にズレが生じるかと言うと、最大の理由はレセプトデータ上のアウトカムと、医師が臨床で用いる真のアウトカムとでは、病名を付与する目的が異なっているからです。
後者は当然ながら、日常診療のための情報に使われます。
「あー、この患者さんはうつ病があるんだな、となると療養生活に支障があるかもしれないから、念の為こういうところに気を配ってフォローしていこう」という感じですね。
一方、前者のレセプトデータ上のアウトカムは、前述のように患者に提供した医療に対して保険償還を受けるために入力します。
「輸液を使うためには、それに紐づいた病名がないといけないから、とりあえず脱水でも入力しとくか」という感じですね。
ここで提供した手術や薬剤、その他医療行為に対して、保険者が”適切である”と判断できるだけの病名がレセプトに入力されていない場合は、その分の医療行為の保険償還を受けられず、病院にとっては収益減に繋がる可能性もあります。
極論を言ってしまうと、「提供した医療行為に対して保険償還が得られるならば、どんな病名であっても良い」ということになりますし、さらに保険償還の可否を気にするのは、多くの医療施設では医師ではなく医療事務さんになりますので、入力者である医師が正確に病名を入力するインセンティブはさらに低くなります(レセプトは毎月1回提出ですので、その度に未入力や誤入力があると、医療事務さんから医師に連絡が来て、”ここ入れ直してください”、”はいはい”のようなやり取りが発生します)。
この病名入力における目的のズレが、「レセプトデータの病名は、正しい患者像を把握する上で、そんなにイケてない」と言われる最大の所以です。
また別の記事でValidation研究*については詳細に説明しますが、こちらはDPCデータベースの疾患を対象にして行われたValidation研究の結果です。
*ここでは、「真のアウトカムと測定したアウトカムを比べて、正解率はどれくらいか確かめるための研究」くらいに捉えておいてください。
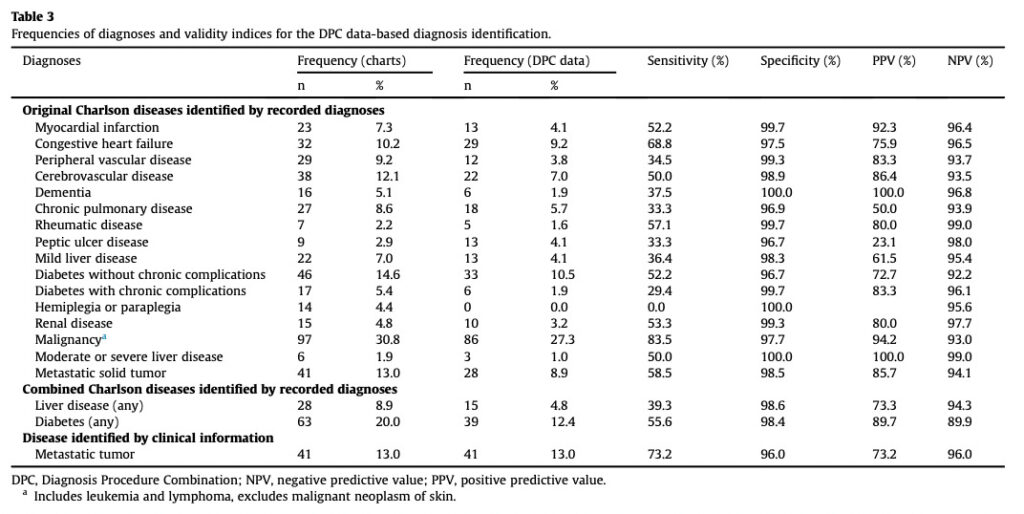
各疾患ごとに、Sensitivity(感度)、Specificity(特異度)、PPV(陽性的中度)、NPV(陰性的中度)の4指標を計算しています。
感度を見ていくと、例えばMyocardial infarction(心筋梗塞)が52.2%、Dementia(認知症)が37.5%となっています。これは、真にアウトカムを有する患者のうち、レセプト上はそれぞれ52.2%、37.5%のみの患者しか”アウトカムあり”と測定できていなかったということを表しています。
どうでしょうか?
実際に疾患名と妥当性の指標を見てみると、アウトカムの誤測定の恐ろしさにゾッとしてきませんか?
なお、アウトカムの妥当性指標に関する説明は以下の記事でしておりますので、併せてお読みいただければ、今回の記事の理解度が上がると思います。
アウトカムの誤測定の種類
さて、ここまでは実臨床で起こりうるケースを紹介しながらアウトカムの誤測定の説明をしてきました。
ここからは、DAGを用いて理論的にアウトカムの誤測定の説明をしていきたいと思います。
アウトカムの誤測定には、非差異的誤分類と差異的誤分類の2種類があります。
非差異的誤分類
非差異的誤分類は、英語ではNon-differential misclassificationと表現されます。
DAGに表すと、例えばこんな感じです。
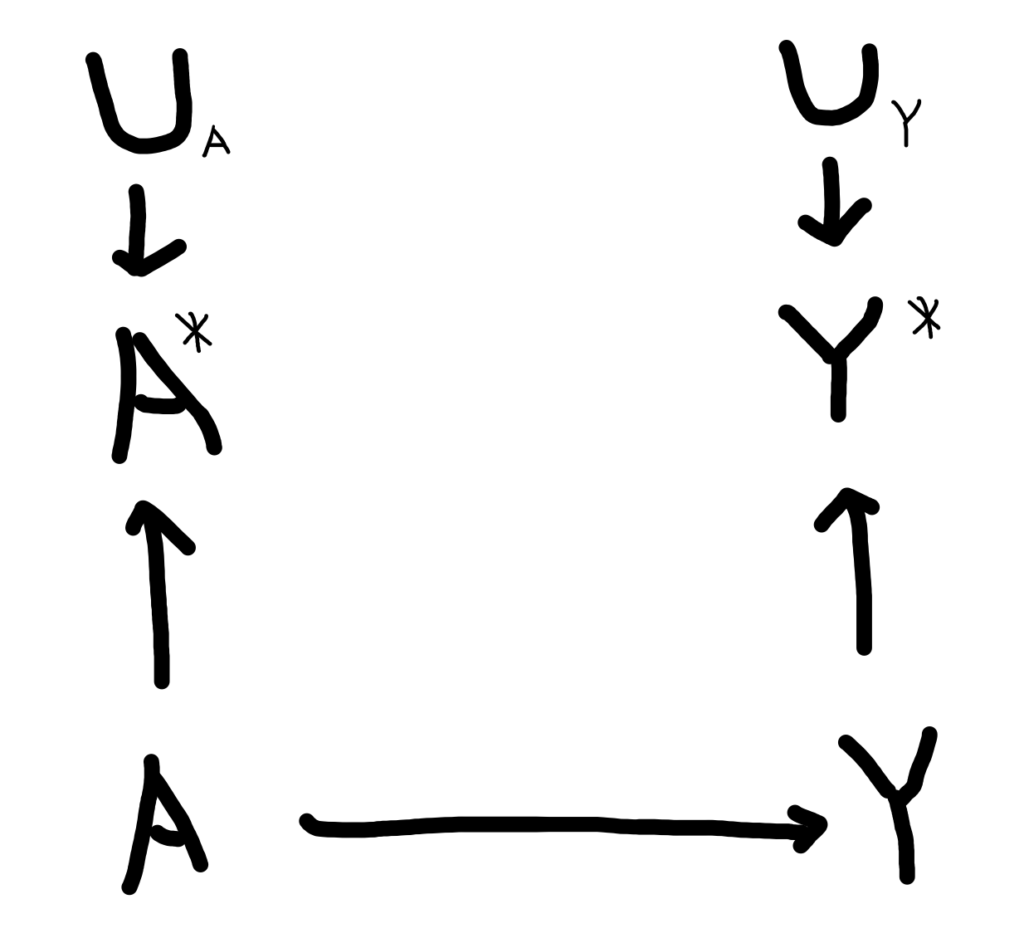
A: 真の薬剤Aの投与
Y:真の疾患Y
A*: レセプト上の薬剤Aの投与
Y*:レセプト上の疾患Y
UA: A*の値を決定する要因(A以外)
UY: Y*の値を決定する要因(Y以外)
です。
レセプトデータを用いる際、我々に見えてるのは真の薬剤投与や真の疾患ではなく、”測定された”それであるA*・Y*と言うのがミソですね。
UA・UYは誤測定を起こす理由で、例えば医師のレセプトへの入力精度などです。
アウトカムに着目してみると、非差異的誤分類においては薬剤Aの投与群と非投与群の間で、誤分類の大きさ、方向に偏りがありません。
妥当性指標で言えば、コホートを薬剤Aの投与・非投与群に層別化すると、両群での疾患Yの感度、特異度、PPV、NPVに差がない状況です。
差異的誤分類
お次は差異的誤分類です。
DAGに表すと、例えばこんな感じ。
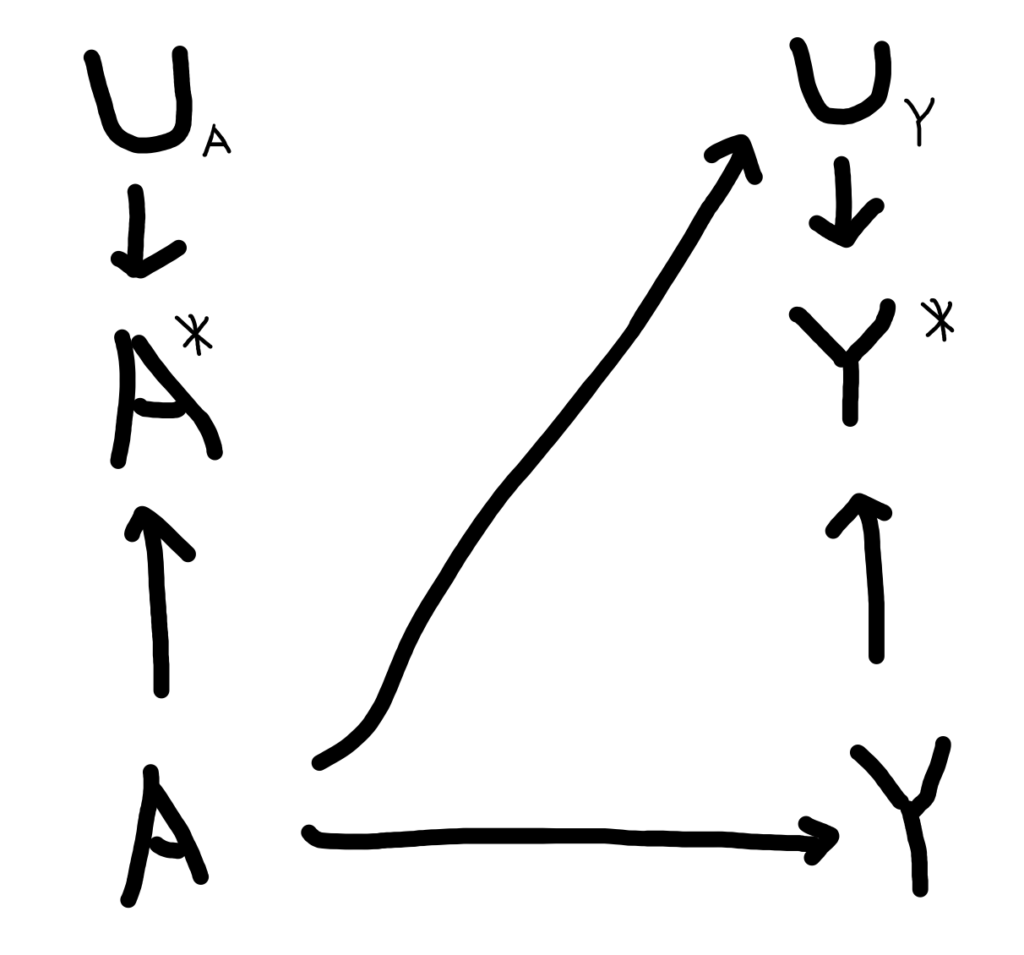
ご覧の通り、今回は真の薬剤の投与Aから、疾患Yの誤測定であるUYに向かって矢印が伸びています。
これはつまり、薬剤Aの投与の有無が、疾患Yの誤測定に影響を与えているということです。
これはどのような状況でしょうか?
例えば、治験において曝露の割り付けのブラインドがされていない時です。
アウトカムの判定を行う医師が「新しく開発している薬剤Aに効果があるといいな」と考えており、さらに患者が薬剤Aの投与を受けたかどうかを知ってしまっているとします。
この時、「薬剤Aに有利になるように、薬剤Aの投与患者はアウトカムがあるかないかグレーゾーンの時には、緩めに判定して、アウトカムなしにしておこう。非投与患者は厳しめにつけよう」なんていうふうにアウトカムの差異的誤分類が生じるリスクがあります(これを防ぐために行われるのが割り付け薬のブラインドであり、そうするとA→UY間の矢印が切断されます)。
このような差異的誤分類では、曝露のありなし群間で誤測定の大きさ、方向が異なります。
つまり、曝露のありなしでコホートを層別化すると、アウトカムの妥当性指標である感度、特異度、PPV、NPVが両群で異なってきます。
では、このような非差異的、差異的誤分類は薬剤Aの因果効果の推定にどのようなインパクトを与えるのでしょうか?
アウトカムの誤測定が因果効果推定に与える影響
アウトカムにおいて、基本的には非差異的誤分類はBias toward the nullを引き起こします。
つまり、リスク差であれば0.0、オッズ比であれば1.0に近づくバイアスを起こすと言うことです。
一方の差異的誤分類は、理論的にはBias toward the null/Bias away from the nullのどちらも起こしえます。
余談ですが、非差異的誤分類では特異度が100%であれば、感度がどのような値を取ろうとも、リスク比はバイアスを受けません。
詳細は以下の記事の”特異度が特に重要になる状況”を参照してください。
さて、非差異的誤分類において、Bias towad the nullが発生する、つまりリスク差が0.0に、そしてオッズ比が1.0に近づくということは、簡単な計算で確認できます。
以下のようなテーブルがあったとしましょう。
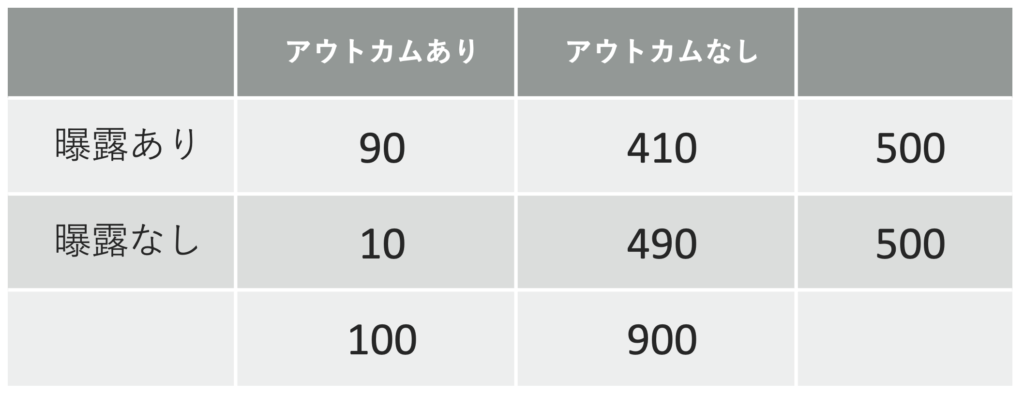
この時、
オッズ比:90/10 ÷ 410/490 ≒ 10.76
リスク差:90/500 – 10/500 ≒ 0.16
です。
上記は真のアウトカムを測定できたとした際のテーブルでしたが、我々が知り得るのは測定したアウトカムのみで、真のアウトカムを知ることはできません(DAGで言うならば、YではなくY*のみを知ることができます)。
そして、これまで説明してきたように、真のアウトカムと測定したアウトカムの間にズレ、つまり誤分類が発生したとしましょう。
その時、オッズ比とリスク差はどうなるでしょうか?
計算を簡単にするために、特異度は100%、感度50%という非差異的誤分類が発生していたとします。
つまり”真のアウトカムあり”患者のうち、50%は誤って”アウトカムなし”と判定されてしまう状況です。
すると測定したアウトカム上は、以下のようなテーブルだけが我々に見えていることになります。
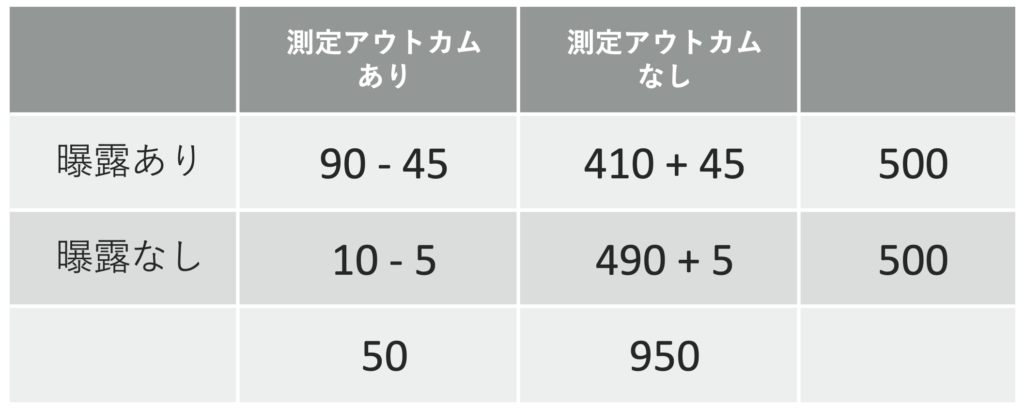
曝露ありなし群のそれぞれにおいて、真のアウトカムありの患者の50%がアウトカムなしと測定されてしまうため、アウトカムあり群から90×50% = 45人/10×50% = 5人の患者がそれぞれアウトカムなし群へと移動しています。
すると、
オッズ比:45/5 ÷ 445/495 ≒ 9.70
リスク差:45/500 – 5/500 ≒ 0.08
となり、真のオッズ比、リスク比よりもそれぞれ”差なし”とされる値(オッズ比1.0、リスク差0.0)へと近づいていることがわかります。
さて、より複雑な状況で曝露の誤測定のインパクトを掴んで頂くために、実際に電子カルテデータを用いて曝露の誤測定が因果効果の推定に与えるインパクトを調査した論文がありますので、紹介しましょう。
この論文1では、ワクチンを推奨スケジュールで接種した小児に対し、非接種群/推奨とは異なるスケジュールで接種した群のそれぞれを比較群にし、アウトカムである疾患のリスク比を調査しました。
シュミレーションでは、真のリスク比、アウトカムの発生率、差異的/非差異的誤分類、感度・特異度を操作し、それぞれのリスク比を算出しています。
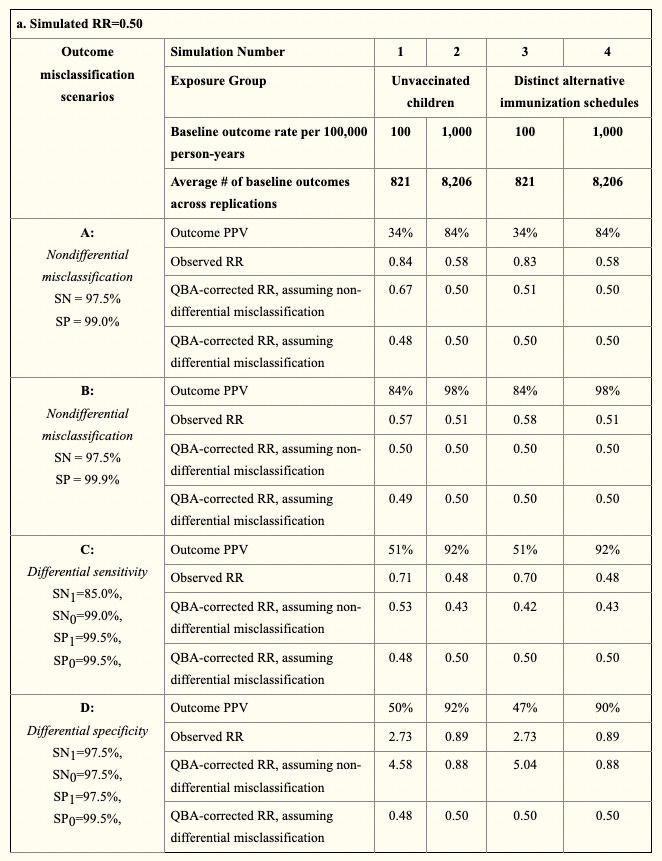
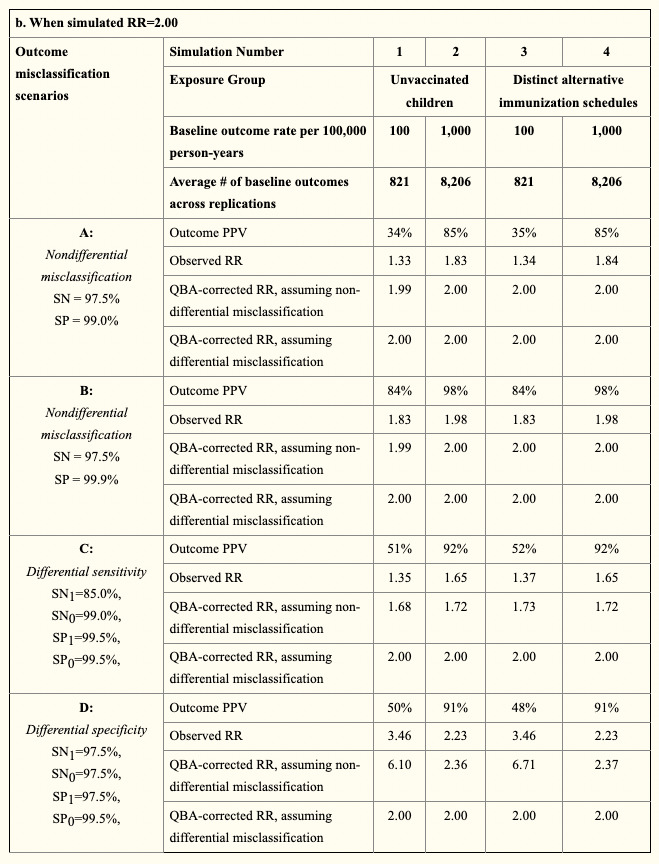
こちらが真のリスク比0.5, 2.0とした際のそれぞれの結果です。
それぞれObserved RRの列を眺めて頂ければと思いますが、Nondifferential misclassificationであるA, BにおいてはBias toward the nullが起こっています。
一方、Differential misclassificationであるC, Dにおいては、Bias towad the null/Bias away from the nullの双方が発生していることがお分かり頂けるかと思います。
アウトカムの誤測定バイアスの影響は、感度、特異度、PPV、NPVだけではなくアウトカムの発生頻度にも影響を受けますが、このシュミレーションではアウトカムの誤測定が起こることで、真には0.5であったリスク比が最大で2.73と観測されたり、真には2.0であったリスク比が最大で3.46、最小で1.33と観測されています。
例えば、新たに開発した薬剤Aの安全性を確認するための研究をしたとしましょう。
その際、真実においては他剤と比較した新薬Aの有害事象の発生リスクは、リスク比で0.5だとします。
ですので、”薬剤Aは他剤と比較し、有害事象発生リスクが極めて小さい”と判断されるべきところを、アウトカムの誤測定が起きたことで、リスク比2.73と出てしまったら、極めて問題ですよね?
”薬剤Aは他剤と比較し、有害事象リスクが極めて大きい”という間違った結論から、最悪の場合は薬剤Aの市場撤退などという誤った意思決定につながってしまいます。これにより、本当は薬剤Aによって助けられるはずだった患者さんが治療を受けられない、開発に要した数十年、数百億というコストが無駄になる、という恐ろしい事態が起きかねません。
またこの逆もしかりで、真にはリスク比2.0のところを、アウトカムの誤測定によりリスク比1.33と観察してしまい、”薬剤Aは他剤と比較し、極端に有害事象リスクが大きいわけではない”という判断から、本当は薬剤Aを投与すべきでない状況においても投与が行われてしまい、結果として取り返しのつかない薬害を発生させてしまったということもありえます。
終わりに
さて、いかがでしたでしょうか?
説明してきたように、アウトカムの誤測定は薬剤の因果効果の推定において時として大きなインパクトを与えます。
薬剤は人の生き死にに直接的に影響する曝露ですから、その因果効果の推定における誤りは、取り返しのつかない事態に繋がりうるリスクがあります。
ですので、我々が医療大規模データベースを用いた研究を行う際には、目に見えているアウトカムと、真実のアウトカムの間にはズレがありうるということを十分に理解し、そのズレの大きさを測定し、そして少しでもズレを小さくするような工夫をしなければならないのです。
というわけで次回は、そのズレの大きさを測定する方法である、Validation研究について解説していきたいと思います。
・アウトカムの誤分類には非差異的誤分類と差異的誤分類がある
・非差異的誤分類はBias toward the nullを、差異的誤分類はBias toward the null/Bias away from the nullを起こす
・薬剤疫学におけるアウトカムの誤分類は、患者の生き死にに直結する
すきとほる疫学徒からのお願い
本ブログは、読者の方が自由に記事の金額を決められるPay What You Want方式を採用しています。
「勉強になった!」、「次も読みたい!」と本ブログに価値を感じてくださった場合は、以下のボタンをクリックし、ご自身が感じた価値に見合うだけの寄付を頂戴できますと幸いです。
もちろん価値を感じなかった方、また学生さんなど金銭的に厳しい状況にある方からのご寄付は不要です。
引き続き情報発信していく活力になりますので、ぜひお気持ちに反しない範囲でご寄付をお願い致します!






