

こんな人におすすめの記事です。
- 初めて記述疫学研究に取り組む
- 記述疫学の論文をどう書いたらいいかわからない
こんなお悩みを解決します。
この記事ではAmerican Journal of Epidemiologyに掲載された記述疫学研究のガイドラインをもとに、『こうすれば魅力的な記述疫学研究になる』という*つの秘訣を論文のパートごとにお伝えします。

記述疫学って、解析内容とか結果がシンプルな分、どれだけ魅力的な書きっぷりができるかにかかってるよね。
本ブログは、私個人の責任で執筆され、所属する組織の見解を代表する物ではありません

「RWD研究の支援をしてほしい」というご相談を多くの企業様から頂戴するので、企業様向けに正式に窓口を設置しました。
以下のアドレスに連絡頂ければ私に直通しますので、「1時間の無料相談」も含めてお気軽にご連絡ください(3営業日以内にお返事させて頂きます)。無料相談は大変ご盛況となっており、先着順にて対応させて頂いております。
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
私が経営するmMEDICI株式会社ではRWD利活用支援を事業の柱の一つとしており、以下の強みを有しています。「企業の」RWD研究においては日本トップクラスの解像度と経験値を有する自信がありますので、ぜひ無料相談でご体験くださいませ。
- 元大手外資の日本・グローバル出身の疫学専門家が全案件を担当するので、「企業の」RWD研究に高い解像度を有しています
- ただ成果物を納品するだけでなく、グローバルやKOLとの合意形成、社内プレゼン、規制当局対応などRWD研究の「プロセス」も全てまきとれます
- 企業のRWD研究を幾度となく経験しており、企画立案から論文化までの全フェーズを一気通貫で対応できます
- アカデミアのRWD研究者と広い繋がりを有しており、必要に応じた専門人材のアサインが可能です
- RWD研究だけでなく、事業立案、マーケ、広報、営業などのRWDビジネスも全て対応可能です
以下に私の実績を記載させて頂きます。
- 大手外資製薬2社にて、部門唯一の疫学専門家として活動をリード
- 「RWDビジネスの教科書」の書籍を出版(サイドバーをご覧ください)
- 企業でのRWD研究の経験は50本以上
- 製造販売後データベース調査のリード経験多数
- これまで製薬、CRO、コンサル、総合商社、ヘルステックなど10社以上の企業のRWD研究・RWDビジネスを支援
- 50組織以上にRWD研修を提供
- 全体統括・講師を勤めたJapan RWD Summitでは初回から約1,700名の集客を実現
無料相談では、以下のような内容を含め企業様の「RWD」と名のつく相談でしたら全て対応させて頂きます。
- このテーマでRWD研究はできるの?
- RWD研究っていくらくらいかかるの?
- RWD研究ってどんなプロセスでやれば良いの?
- 製造販売後データベース調査のやり方を教えてほしい
- RWD研究をするにはどんな専門家を雇えば良いの?
- 自社のRWDサービスを売りたいんだけど、強みはどこ?集客はどうすれば良い?
無料相談は先着順での対応となりますので、ご希望の企業様はぜひお早めのコンタクトをお願い致します!
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
記述疫学の定義
本ガイドラインでは記述疫学は次のように定義されています。
たとえば以下のような研究は全て記述疫学研究にカテゴライズされます。
- 疾患の有病割合や有病率を測定する
- とある疾患を有する患者の特徴を記述する
- とある疾患の予後を記述する
- 薬剤の使用割合や継続使用、切り替えなどの使用実態を記述する
などですね。
ちなみに疫学研究のタイプは大きく分けて記述、予測、因果推論の3つに分類されるよ
記述疫学が推定しようとするものとは
さてここで問題。
『記述疫学が推定しようとしているものってなんでしょうか?』
推定も何も、そのままデータの要約統計量を算出してるんだから、それがアウトカムでしょ?
いいえ違います、比較研究と同じように記述疫学にも推定の対象、いわゆるEstimandが存在します。
です。
ここで大切なのは、Estimandを推定したいTarget populationと実際に解析の対象とできるAnalysis population違うということですね。
この点は後ほど説明します。
ではいよいよ、記述疫学研究を行う際に抑えるべきポイントを解説していきましょう。
①Well-definedなリサーチクエスチョンを作る
あらゆる研究はリサーチクエスチョンから始まります。
リサーチクエスチョンを明らかにするために研究デザインを立案し、研究を実施し、そして結論に向かって真っ直ぐに論文を書き進めていく。
リサーチクエスチョンはそんな研究の屋台骨ですから、しっかりと定義されたリサーチクエスチョンを用意しなければ、どれだけあがいても骨抜きの研究になってしまいますね。
では、『Well-definedなリサーチクエスチョン』とは何なのか?
本記事が参考とする記述疫学研究のフレームワークでは、
と定義されています。
また、それに加えてImpactfulであることが求められますが、これは
と定義されています。
要はこんな感じ。
解釈に揺らぎがないくらいぴちっと定義されてて、明確で、そんで困ってる集団を助けるために”何をしたらいいか”示唆してくれる質問
たとえばこんなリサーチクエスチョンはill-definedですね。
薬剤を投与された肺がんの患者における有害事象を明らかにする
時間軸:いつの時点の?
薬剤:一体なんの薬剤なの?
肺がんの患者:新規の前立腺がん患者なのか既存患者なのかどっち? どこの患者?
有害事象:なんの有害事象?
明らかにする:有害事象の何を明らかにするの?
これをwell-definedなリサーチクエスチョンに昇華させるなら、こんな感じ。
2010年4月から2018年3月にかけて日本全国で薬剤Aをファーストラインで投与された新規の肺がんのステージⅢの患者における、投与1年以内の間質性肺炎のIncidence rateを明らかにする
先ほどのリサーチクエスチョンと比べると曖昧さがなくなり、何がしたいのかが明確になりましたね。
Well-definedなリサーチクエスチョンを分解すると、以下のような構成となります。
- Target Populationは何か(人、場所、基準となる時間)
- アウトカム、イベント、健康状態や対象者の特性
- 要約統計量(Incidence, prevalence, average time to event)
②Target populationを特定する
Target populationとは、あなたが着目するアウトカムの分布を明らかにしたい対象集団のことです。
ややこしいけど、要は解析の対象になってるPopulationでしょ?
違う! 疫学研究において、研究の対象にしたい集団と、実際に研究対象にできた集団と、そして解析の対象にできた集団は異なる可能性があるんだ。
この図を見ながら考えてみよう。
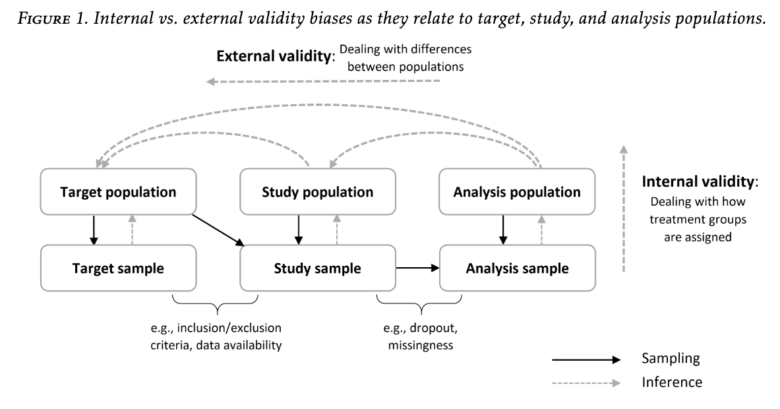
Irina et al. A Review of Generalizability and Transportability.
まず、
Target populationとはあなたが関心がある集団のことです。
先ほどあげた例で言うと、『2010年4月から2018年3月にかけて日本全国で薬剤Aをファーストラインで投与された新規の肺がんのステージⅢの患者』です。
実際の研究ではTarget populationをそのまま研究対象とすることは不可能であり、科学的および現実的な観点からStudy populationを構築します。
たとえば、ある医師が薬剤Aの効果を調べるためにランダム化比較試験をする際、Target populationとしては「その病院で癌の治療を受ける全ての患者」を思い描いたとしましょう。
しかしながら、実際には科学的な観点(人種による効果修飾因子の影響)や現実的な観点から(特定の人種の宗教的な理由)、によってアジア人を研究対象に含めることができなかったとします。
この時、研究の対象となるStudy populationは非アジア人であることなどの幾つかのInclusion criteriaとExclusion criteriaをTarget populationに適用させた後の集団となります。
さらに、上の図を見るとStudy populationの右にAnalysis populationがあります。
なぜなら、研究には脱落や欠損が生じるため、実際に最終的に解析の対象にできるAnalysis populationとStudy populationは異なるからです。
さらにさらに、実際に我々の解析対象にできるのはAnalysis populationですらありません。
Analysis populationというのはあくまでも仮想的な集団なんですね。
なぜなら、Analysis populationが「日本全国の肺がん患者」だとしても、実際に全ての肺がん患者を研究に組み込むと言うのはほぼ不可能だからです。
そのため、我々は「母集団を代表するようなサンプリング集団を形成する」という目的のもと、母集団の一部の患者をサンプリングし、実際の解析対象とするわけですね。
こんな感じで、「僕たちが本当に興味のある集団」と「解析の対象になって結果を得られた集団」は幾つかのステップで隔てられてるんだ
だから、研究結果を解釈する際には「Analytic sampleの結果がどれだけTareget populationに一般化できるか」ということを考える必要があるわけですね。
だって、Target populationにおける何かが知りたくて研究をしているのに、実際に得られた結果がTarget populationには一般化できなかったら、研究をやった意味が乏しくなってしまいますから。
論文のLimitationでよく「この研究の一般化可能性は〜」と書かれているのはこれが理由だよ。あれ、ただ「テンプレだから入れとこ」ではないんだ。
疫学研究が対象者の脱落とかデータの欠損に厳しい理由もこれです。
脱落や欠損が完全にランダムに起きていれば、Analytic sampleがStudy sampleを代表できる可能性は理論的には崩れません。
しかしもしランダムではなく、脱落や欠損が生じた集団とそうではない集団の間に系統的な差異があれば、上記の代表可能性が崩れ、Analytic sampleの結果をStudy sampleに一般化することはできなくなってしまいます。
例えば、生活習慣に関するアンケートをしたとしよう。おそらくこのアンケートに回答してくれる人は健康意識の高い人ばかりだから(healthy user)、その結果を健康意識の低い人に一般化することはできないよね
・”関心のある”Target populationと、実際に”結果を得られた”Analytic populationの差異に着目することが重要
③Outcomeを定義する
Target population同様にアウトカムもまた解釈の幅がない形で明確に定義されなければなりません。
悪い例えですと、医療大規模データベース研究を行う際の研究計画で「薬剤Aの有害事象の発症頻度を見る」とだけ書かれていたとしましょう。
このような曖昧な記述は許されません。
どんな有害事象が起こるか分からないから、色んなアウトカムの発症頻度を出して、その後で特に頻度が高いものを選びたいんだ
それはダメ!恣意的なアウトカムの選択に繋がるし、そもそも疾病によって誤測定バイアスのリスクが異なるから、見れるアウトカムと見れないアウトカムがある。
アウトカムを測定するためには定義が必要です。
ですので、アウトカムはただ病名を書いて終わりではなく、「その病名をどう定義するか」まで含めて書かなければ正確な記載にはなりません。
例えばステージⅢの肺がんでしたら、TNM分類に応じて設定されますよね。
TNM分類のように世界共通で使われる基準でよければ「ステージⅢの肺がん」とだけ書いても解釈の幅はないかもしれません。
しかしそうではなく、国によって診断基準に差がある疾病をアウトカムにしたとしましょう。
すると、その疾病を診断する際の検査値や画像検査などの基準を書かなければ、人によって解釈に幅が出てしまい、特異的なアウトカム定義にはなりません。
なぜこれだけ特異的なアウトカム定義にこだわるのでしょうか?
なぜなら、アウトカムの定義によって感度・特異度が変わり、それに応じて研究結果として出てくる発症頻度・リスク比などの数値が大きく変わるからです。
たとえば、Baseline期間が6ヶ月か9ヶ月かでも結果が大きく変わる時だってあるよ
そのため、アウトカムを定義する差異にはただ疾病名とその診断基準を書くだけでなく、「その診断基準にしたことで感度・特異度はどうなり、それにより研究結果がどのような影響を受けるか」ということを考えながら記載せねばなりません。
たとえばこちらの研究は、同じ疾患に対して複数の定義を作成し、感度・特異度などの妥当性指標がどう変化するかを比べています。
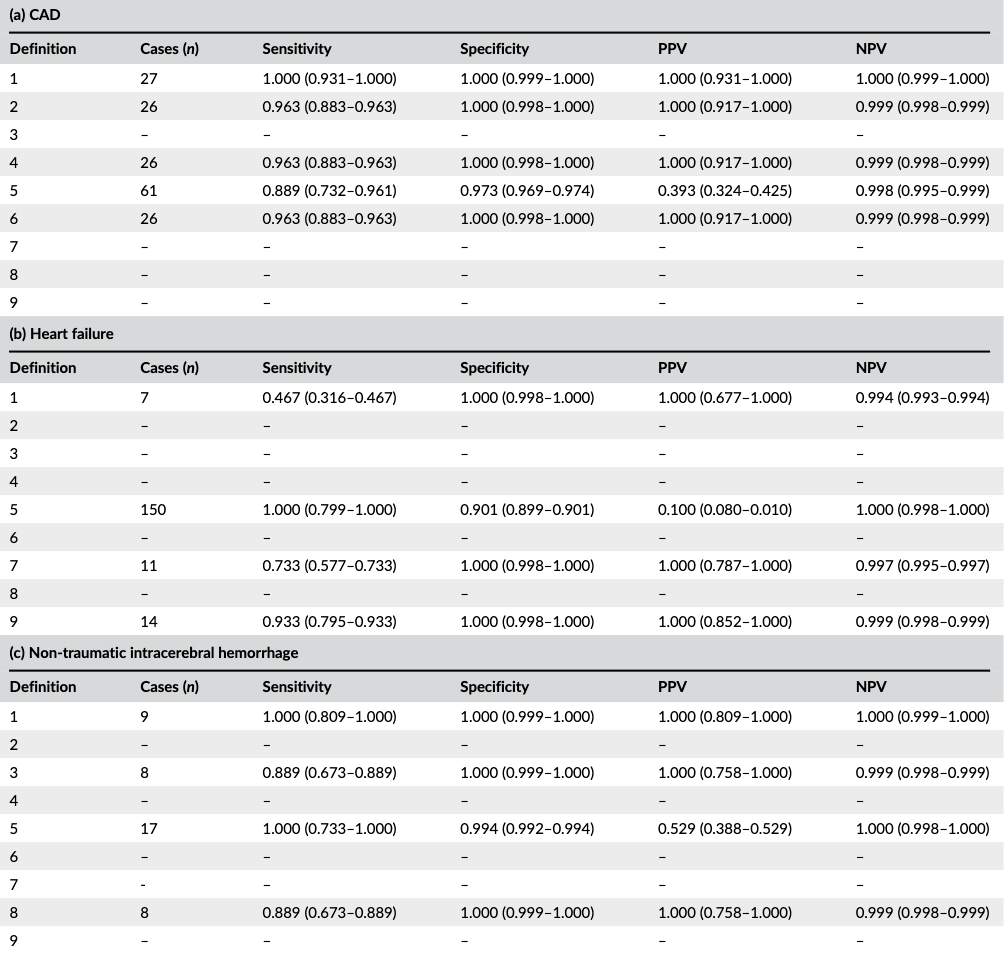
アウトカム定義によってぜんぜん感度・特異度・PPV・NPVが変わるでしょ?
・さらに、その定義にすることで感度・特異度がどう変わるかを念頭におかねばならない
・なぜなら感度・特異度が変わると研究結果も大きく変わりうるから
④Outcomeの尺度を定義する
アウトカムの定義とアウトカムの測定尺度の定義は別物です。
ややこしいよね…
アウトカムの尺度とは、Prevalence(%)やIncidence rate(Person-year)などどんな指標でアウトカムを計算するかという尺度ですね。
この尺度について、印象的な一文が本記事が底本にしているガイドラインにあったので紹介しましょう。
like the proverbial blind men feeling the elephant, our choice of measure of occurrence might give us only part ofthe complete picture about the distribution of the outcome in the target population.
日本語にすると、
目の見えない人が像を感じるということわざのように、発生頻度の尺度を選択しても、それはTarget populationにおけるアウトカムの分布に関する全体像の一部だけを切り取ったものに過ぎないかもしれない。

モチラボ. 3分でわかる『群盲像を評す(ぐんもうぞうをひょうす)』の教訓より引用
記述疫学で主に使うアウトカムの尺度はPrevalence、Incidence rate、Cummulative incidenceでしょう。
- Prevalence (%): ある一時点の疾病の保有者割合を示す
- Incidence rate(Person-year): Index時点で疾病のない集団における疾病が発生する速度、時間の概念が含まれる
- Cumulative incidence (%): Index時点で疾病のない集団における一定期間の疾病の発症者割合を示す
記載の甘い研究計画書ですと「疾患Aの発症頻度を明らかにする」とだけ書かれ、どのような尺度を使うのかが明確ではない場合があります。
これはNGです。
上のリストの通り、尺度によってまったく描き出される結果が変わるので、どんな尺度を使うのかは明確にせねばなりません。
日本語で書くと曖昧表現になりやすいので、英語で書くことをお勧めします。
あと、「Occurrence」は上の3種類の全てを含んだ曖昧表現なので、使うべきではありません。
終わりに
いかがでしたでしょうか?
「ただの記述疫学研究」と思われるかもしれませんが、記述疫学研究も比較研究と同じように研究デザインへの深い理解が必要とされます。
そうでなければ、世界のどのような側面を切り取りたいのかが曖昧になり、得られる結果も解釈は難しくなるでしょう。
一般化可能性の縮小、選択バイアス、そして誤測定バイアスなどは記述疫学でも当然生じます。
適切にそれらをコントロールし、より意味のある結論を読者に届けるためには、クリアカットに各種定義を決めなければなりません。
記述疫学、シンプルだからこそ研究者の腕の良し悪しが明確に反映される、とてもやりがいのある研究デザインですよね。
こちらのまとめ記事では、記述疫学だけでなく疫学研究のさまざまな場面で必須となる知識を紹介しています。
リアルワールドデータについて [sitecard subtitle=合わせて読みたい url=https://nothing-without-poison.com/epi16/ target[…]

「企業の疫学専門家になりたい!」という方向けに、3万字近くかけて必要な全てを解説したオールインワンのnote記事を執筆しました。
現役の企業の疫学専門家の目線からこんなことが解説されているので、ぜひご覧ください。
- 必要な専門性のリストとそのレベル
- 専門性を身につけるための参考書
- おすすめの大学院
- 就活対策と私の就活経験
- 就職後にパフォーマンスを発揮するための工夫
すきとほるからのお願い
本ブログは、読者の方が自由に記事の金額を決められるPay What You Want方式を採用しています。
学生さんや経済的に厳しい方からはお金を取りたくなく、それが経済格差に起因する学力格差へと繋がると考えるからです。
仕事の合間に記事を書く時間を見つけるのはちょっぴり大変ですが、今後も皆様の「研究生活をほんのり豊かに」できる記事をお届けし続けたいと思っております。
なのでお金に余裕があり、そして「勉強になった!」、「次も読みたい!」と本ブログに価値を感じてくださった場合は、以下のボタンをクリックし、ご自身が感じた価値に見合うだけの寄付を頂戴できますと幸いです。
励みになるので、ご寄付はとてもありがたいです!
引き続き情報発信していく活力になりますので、ぜひお気持ちに反しない範囲でご寄付をお願い致します!






