

こんにちは、すきとほる疫学徒です。
事後解析ってなに?
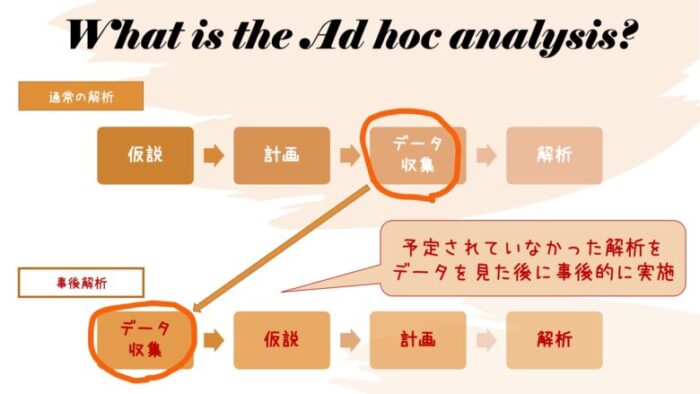
事後解析は英語でPost-hoc AnalysesまたはAd-hoc Analysesと呼ばれ、「研究計画当初は予定していなかったが、事後的に追加された解析」を意味します。
通常の解析は、上の図のように
仮説を敷き、
その仮説を検証するための研究計画を立て、
データを収集し、
最後に解説する。
という順番で研究が進みますが、事後解析の場合は研究が進んだ段階で「そうだ、こんな解析もやってみよう」という発想が生まれますので、
データを収集し、
その途中、もしくは完了後に「もしかすると」という仮説が生まれ、
解析を行う、
という手順で研究が進みます。
さてそんな事後解析ですが、医学研究において行うことはあまり推奨されていません。
なぜでしょうか?
大きく3つの理由をこれから解説していきたいと思います。
事後解析が推奨されない理由
チェリーピッキングの可能性

全ての研究は、実行に移す前に研究計画を公的に登録し、第三者が閲覧可能にすることが良しとされています。
なぜだと思いますか?
それは、「事前の研究計画の登録がないと、好き放題にデータをこねくり回し、研究者に都合の良い結果が出た解析だけを公表する」ということが理論的に可能になってしまうからです。
これを専門用語でチェリーピッキングと言います。
たとえば、何らかの疾患に対する治療薬を開発している際に、
「メインのアウトカムにしていた疾患による死亡では有効性が示せなかったけれども、入院期間の短縮には効果がありそうだから、予定していなかったけどこっちもアウトカムとして追加しちゃおう」とか、
「患者全体だと有効性が示せなかったけれども、男性や高齢者だけなら示せそうだから、そこだけに絞った解析もやっちゃおう」とかですね。
もちろん、事後解析=チェリーピッキングが行われている、というわけではありません。
収集を終えたデータを見るなかで新たな仮説が生まれ、その仮説に基づいて行った研究が重要な発見につながるということは、珍しいことではないからです。
そのような事後解析を論文に掲載する場合には、
- 事後解析であることを明示する
- なぜ事後解析を行ったか明確に理由を記述する
という2点が必要になります。
大切なことなので繰り返しますが、「事後解析=100%研究不正である」というわけではありません。
しかしながら事後解析の難しさとして、チェリーピッキングを行ったかどうかが第三者からは判断不可能であるということが挙げられます。
データは研究者の手元にしかありませんので、研究者がそのデータに対してどんな解析を行ったかということは露わになりません。
もしかすると、見たい効果が見れるまで、手当たり次第に対象集団やアウトカムの定義を変えて山のように解析を行っているかも知れない。
そして、さも見たい効果がみれた解析だけを公表し、そこに医学的にそれっぽい理由を後付けしてしまえば、読者は「そうか、然るべき理由があって然るべき解析を事後的に実施し、それで有効性が示されたのか」と納得させられてしまうかも知れません。
このように、事後解析においてはチェリーピッキングが理論的に可能になってしまうという状況そのものが問題になります。
なおこちらも繰返しになりますが、事後解析でが問題になるのは「チェリーピッキングが可能になりうる」という状況そのものであって、「事後解析=チェリーピッキングである」というわけではありませんので、ご注意ください。
検定の多重性
研究者でない方には意外かもしれませんが、医学研究の結果というものは常に誤りである可能性を含んでいます。
この誤りの一つがαエラーと呼ばれるもので、端的にいうと「本当は因果関係がないのに、誤って因果関係があると判断してしまうリスク」のことを指します。
コイントスの例を使って具体的に説明しましょう。
あなたの目の前に裏と表のあるコインがあったとします。
そのコインは、裏と面が同じ確率で出るフェアなコインなのか、それともどちらかに偏っているアンフェアなコインなのかはあなたには分かりません。
そんなあなたにあるお題が提示されました。
「このコインを10回トスして、これがフェアなコインかアンフェアなコインかを判断しなさい」
さて、どうしましょうか?
あなたはこう考えます。
「フェアなコインであれば、裏と表はそれぞれ5回ずつでるだろう」
「でも、偶然どちらかに偏るということもあるかもしれない」
「そうだ、たとえば裏に9回、表に1回という結果が出たら、”偏ったコイン”と定義することにしよう」
こうすれば、10回のトスを通して「偏ったコインかどうか」を決めることができますね。
コイントスとは全く場面設定は違いますが、「ある薬がある病気に効くかどうかを判断しなさい」と言われた時も同じことが行えます。
「この薬に本当に効果があるならば、投与していない人に比べて投与した人では、X 倍は病状が良くなる人が多いだろう」というような仮説を事前に設定して研究を行うわけですね。
でも、ちょっと待ってください。
あなたは「裏に9回、表に1回という結果が出たら、”偏ったコイン”と定義することにしよう」と決めました。
しかし、「本当は偏りがないコインだけど、10回コインをトスしたら偶然にも裏が9回連続で出てしまった」ということだって起こり得ますよね?
これが先ほど紹介したαエラーと呼ばれるものです。
つまり、「コインに偏りはないのに、偏りがあると誤って判定してしまうリスク」、薬の話に置き換えるならば「薬に効果がないのに、効果があると誤って判定してしまうリスク」ですね。
さて、このαエラーですが、起こるリスクを研究者が調整することができます。
コイントスで言えば、「X回裏が出たら、偏ったコインと判定しよう」のX回の部分をいじることでαエラーのリスクが変わります。
そして、医学研究においてはαエラーを5%で設定するのが通常です。
だいぶ前置きが長くなってしまいましたが、ここからがこのチャプターのタイトルである検定の多重性の説明になります。
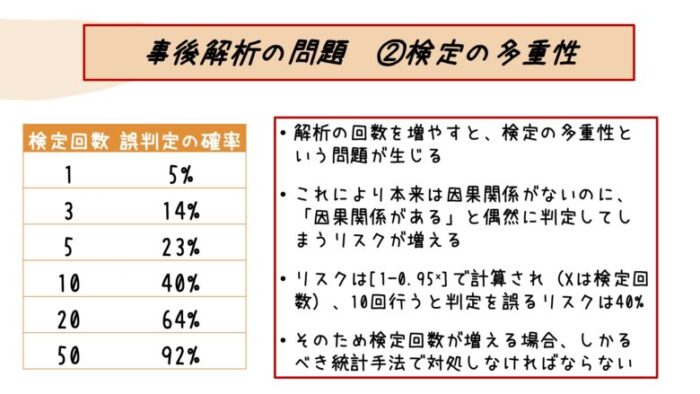
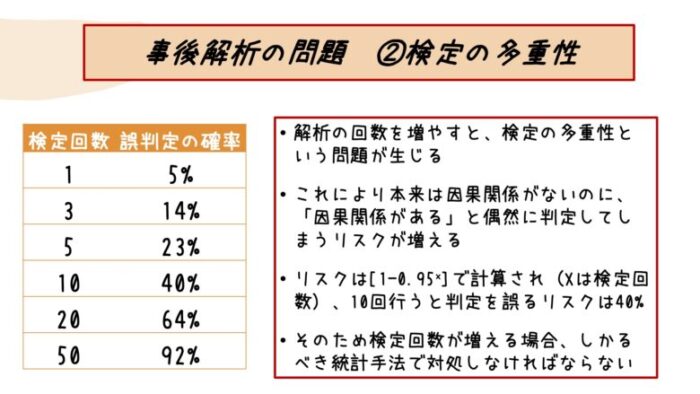
検定を繰り返す(多重にする)と、このαエラーのリスクはどうなると思いますか?
コイントスで言うならば、「10回コインをトスして裏表の数を数えるという作業を、何度も行う」ということです。
「1回の検定(コイントス10回)でαエラーのリスクが5%なんだったら、何回やっても5%なんじゃないの?」と思う方もいらっしゃるかもしれません。
いえいえ、実はそうではないのです。
中学校の確率のお勉強を思い出すと良いかも知れません。
2回の検定を行った際、その双方においてエラーが起こるリスクは、
1 – 0.95^2(2乗)
で表現されます。
つまり、
9.75%ですね。
どうやら、1回の検定でαエラーが起こるリスクの5%よりもリスクが大きくなっていることがわかります。
考えてみれば当たり前ですが、
1回の検定でαエラーが起こらないリスク
10回全ての検定でαエラーが起こらないリスク
この2つのリスクが同じなわけはないですよね。
後者は10回も検定を繰り返しているのですから、そのどこかでエラーが起こるリスクも上昇しています。
このように、検定を繰り返せば繰り返すほどαエラー、つまり「因果関係がないのに誤って因果関係があると判定してしまうリスク」は上昇していくのです。
これが検定の多重性です。
こちらの表のように、何と検定を10回繰り返すだけでαエラーが起こるリスクは40%にもなってしまいます。
事後解析においては、当然ながら実施する検定が増えるわけですから、αエラーが起こるリスクも増えますね。
こんな時にはどうしたら良いのか?
実は統計学には、この検定の多重性を解決するために作られた手法がいくつか存在します。
別のトピックなのでここでは詳しくは話しませんが、事後解析によって検定回数が増えてしまっている研究に遭遇した場合には、「きちんと統計学的な手法によって検定の多重性が調整されているかどうか」という目線でクリティークすると良いでしょう。
仮説の不在
医学研究は、「データを集めて解析すれば、いつでも同じ結論が導かれる」というものではありません。
研究のデザイン、つまり研究の対象集団、データの集め方、曝露やアウトカムの定義の仕方、解析の仕方によって、研究結果とはいとも簡単に変わってしまう脆弱なものです。
では、どのように研究デザインを設定してあげれば良いのか。
そこで必要不可欠なのが、研究者が抱いている研究結果に対する”仮説”です。
「薬剤Xをこの程度、この集団に投与した場合、これくらいの期間観察すれば、投与されなかった集団と比べて、これくらいの効果が得られるだろう」というものが仮説になります。
全ての研究デザインはこの仮説に沿って設定され、仮説に応じた研究デザインになっているかどうかによって研究デザインの適切性が判断されます。
通常の研究では、まず入念に仮説を練り、それに応じた研究デザインを組むことができます。
しかしながら、事後解析の場合は既に研究が走ってしまった後から仮説が生まれるわけですので、通常の研究とは手順が全く逆になってしまうんですね。
すると、新たに生まれた仮説に対して研究デザインがマッチしていない、つまり不適切な研究デザインになってしまっていると言う問題が生じます。
終わりに
いかがでしたでしょうか?
以下3つの観点から事後解析が潜在的に孕んでいる問題をお伝えしました。
- チェリーピッキング
- 検定の多重性
- 仮説の不在
ただ、再三のお伝えになりますが、「事後検定=研究不正」というわけではありません。
事後検定によって非常に重要な医学的知見が得られたというケースもたくさん存在します。
大切なことは「事後解析は、いくつかの理由で不適切な研究につながってしまう潜在的なリスクを孕んでいるから、研究者は丁寧に対処し、また読者は慎重に結果をクリティークせねばならない」というこです。
すきとほる疫学徒からのお願い
本ブログは、全ての記事をフリーで公開しており、「対価を払ってやってもいいよ」と思ってくださった方のみに、その方が相応しいと思っただけの対価をお支払い頂けるPay What You Want方式を採用しています。
教育に投資できる方だけがさらに知識を身につけ、そうでない方との格差が開いていくという状況は、容認されるべきではないと考えているからです(そもそも私程度の記事によって知識の格差が広がると考えていることが、勘違いかもしれませんが)。
私自身も高校卒業後は大学・大学院の学費、生活費と自分で工面する中で、親の支援を得られる友人たちがバイトをせずに学習に集中したり、海外留学や旅行などの経験を積んだりする様子を見て、非常に悔しい想いをした経験があるので、そういった悔しさも本ブログの原動力の一つになっています。
読者の皆様におかれましては、「勉強になった!」、「次も読みたい!」と本ブログに価値を感じてくださった場合のみ、ご本人の状況が許す限りにおいて、以下のボタンからご自身が感じた価値に見合うだけの寄付を頂戴できますと幸いです。
もちろん価値を感じなかった方、また学生さんなど金銭的に厳しい状況にある方からのご寄付は一切不要です。






