

こんにちは、すきとほる疫学徒です。
”ゼロから始める 僕の、私の、初めての疫学研究”は、これまで疫学研究をほとんど行ったことがない方を対象に、「ゼロから研究を立ち上げ、掲載までもっていく」力を身につけて頂くためのシリーズ記事です。
疫学研究の土台となるClinical Question/Research Questionの作り方に始まり、研究計画の作り方、解析のやり方(これは別シリーズ、”初心者のためのRで医療ビックデータ解析”で解説中)、論文の書き方、投稿先の決定の仕方、レビュワーコメントへの対処の仕方など、疫学研究を完遂させる上で必要なノウハウを、ひととおりカバーするつもりです。
本シリーズで紹介する疫学研究の実践法は、あくまでも一つの型でしかありません。
取り掛かりやすさを優先するために、本シリーズでは研究実践において使えるフレームワークをいくつか紹介していくことになると思いますが、そのフレームワークが全ての疫学研究にうまくハマるわけではありませんし、状況によってはフレームワークから離れて思考を展開した方が良い場合もあります。
そうしたフレームワークの活用も含めて、研究者の数ほど研究方法があると思っておりますが、本シリーズは守・破・離で言えば”守”に該当するフェーズであると思っています。
「何から始めたらいいか分からない」という初心者が、最初の一歩として世界中で使われるフレームワークを活用しながら、疫学研究に取りかかるための橋渡しになれれば嬉しいと思っております。
本記事はパート3にあたりますので、未読の方はこちらからご覧ください。

「RWD研究の支援をしてほしい」というご相談を多くの企業様から頂戴するので、企業様向けに正式に窓口を設置しました。
以下のアドレスに連絡頂ければ私に直通しますので、「1時間の無料相談」も含めてお気軽にご連絡ください(3営業日以内にお返事させて頂きます)。無料相談は大変ご盛況となっており、先着順にて対応させて頂いております。
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
私が経営するmMEDICI株式会社ではRWD利活用支援を事業の柱の一つとしており、以下の強みを有しています。「企業の」RWD研究においては日本トップクラスの解像度と経験値を有する自信がありますので、ぜひ無料相談でご体験くださいませ。
- 元大手外資の日本・グローバル出身の疫学専門家が全案件を担当するので、「企業の」RWD研究に高い解像度を有しています
- ただ成果物を納品するだけでなく、グローバルやKOLとの合意形成、社内プレゼン、規制当局対応などRWD研究の「プロセス」も全てまきとれます
- 企業のRWD研究を幾度となく経験しており、企画立案から論文化までの全フェーズを一気通貫で対応できます
- アカデミアのRWD研究者と広い繋がりを有しており、必要に応じた専門人材のアサインが可能です
- RWD研究だけでなく、事業立案、マーケ、広報、営業などのRWDビジネスも全て対応可能です
以下に私の実績を記載させて頂きます。
- 大手外資製薬2社にて、部門唯一の疫学専門家として活動をリード
- 「RWDビジネスの教科書」の書籍を出版(サイドバーをご覧ください)
- 企業でのRWD研究の経験は50本以上
- 製造販売後データベース調査のリード経験多数
- これまで製薬、CRO、コンサル、総合商社、ヘルステックなど10社以上の企業のRWD研究・RWDビジネスを支援
- 50組織以上にRWD研修を提供
- 全体統括・講師を勤めたJapan RWD Summitでは初回から約1,700名の集客を実現
無料相談では、以下のような内容を含め企業様の「RWD」と名のつく相談でしたら全て対応させて頂きます。
- このテーマでRWD研究はできるの?
- RWD研究っていくらくらいかかるの?
- RWD研究ってどんなプロセスでやれば良いの?
- 製造販売後データベース調査のやり方を教えてほしい
- RWD研究をするにはどんな専門家を雇えば良いの?
- 自社のRWDサービスを売りたいんだけど、強みはどこ?集客はどうすれば良い?
無料相談は先着順での対応となりますので、ご希望の企業様はぜひお早めのコンタクトをお願い致します!
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
実現可能性調査ってなに?
実現可能性調査とは、英語でFeasibility Checkといい、立案したReasearch Questionに適切に回答できる研究を実施できるかどうかという調査です。
さまざまな観点から実現可能性調査を行なっていくことになりますが、イメージを掴んでいただくためにすごく極端な例を出すと、
”医療データベースXを使って、薬剤Aと薬剤Bとでどちらが骨折のリスクが高いかを比較しようとしたが、医療データベースXには薬剤Bの使用患者が1人もいなかった”
という感じですね。
このような状態ですと、どれだけ緻密な研究デザインを考えようとも、そもそもこのResearch Questionに答えることができないということになります。
では、どうして実現可能性調査が重要なのでしょうか?
一つ目の理由は、「実現可能性のない研究に着手してしまい、結果的にお金、時間、人などのコストを無駄にすることを避けるため」です。
たとえば、
「薬剤A/B間で肺塞栓リスクを比較するために、5,000万払って医療大規模データベースを購入したぞ!」
「あれれ、医療大規模データベースには、肺塞栓を定義するだけの十分な情報がないぞ!」
という具合ですね。
こうなると、プロジェクトに参加していた研究者の時間もお金も全てが無駄になってしまいます。
ただ、こちらの”コストの無駄を避けるため”という一つ目の理由の方はまだ良いんですよ。
極端な表現をすると、失敗しても困るのは研究者たち本人、自己責任の範疇で済む話ですから。
でも、二つ目の理由は違います。
実現可能性調査が重要な二つ目の理由、それは「実現可能性がない、つまり適切にバイアスを排除できないにも関わらず研究が実施されてしまい、そのバイアスまみれの結果が”真”として世に広まってしまうことを避けるため」です。
研究の実現可能性には、大きく二つのレベルに分かれると思っております。
- 比較群の患者が全く存在しないなど、一切研究の実施が不可能な場合
- 何らかの結果は導けるが、適切にバイアスを排除することが不可能な場合
1の場合は誰の目で見ても「研究無理じゃん、やーめよ」となるので大きな問題にはなりません。
しかし、曲者は2の場合。
特に医療大規模データベース研究の場合は、(バイアスの影響を考えなければ)データはあるわけですから、やろうと思えば何らかの結果が出てしまうんですよね。
仮にバイアスだらけの不適切な結果であったとしても。
そんなバイアスまみれの研究がしっかりとJournalの査読で弾かれれば良いのですが、査読者の実力が不十分だったときには、そうしたバイアスまみれの研究もしれーっと世に出てしまうことだってあるわけです。
そして、一度世に出た結果は一人歩きを始めます。
疫学・統計学を修めていない臨床家・患者の中には、「論文に載っている=真」として、結果を拡大解釈してしまう方もいらっしゃいます。
SNSを見ていれば、専門家とは思えない方々が、英語論文を自動翻訳して、結果や考察の一部のみを切り取って、自身の主張の根拠としているシーンも珍しくないでしょう。
バイアスにまみれた誤った研究結果に基づき、臨床家や患者さん自身が意思決定をしてしまったら、それはその人の生き死にに関わる重大な問題を引き起こすかもしれません。
では、その時の責任は誰にあるのか?
もちろん、(知ってか知らずか)バイアスにまみれた研究結果を、つまり本当なら世に出すべきではない研究結果を公開してしまった研究者自身でしょう。
だから、研究者は研究を始める前に入念に実現可能性を調査して、「この研究で生じうるバイアスは適切に制御されているか」、「されていないのだとしたら、果たして許容可能なラインのバイアスかどうか」という点を、何度もなんども自分に問うていかねばならないわけですね。
先ほどもお伝えしました通り、この姿勢は医療データベース研究においてはことさら重要となります。
医療データベース研究をやっていますと、残念ながら「データはあるし、面白そうだからとりあえずやってみるか」という軽い気持ちで研究をしてしまい、そのまま論文投稿をするということが可能になってしまうわけですね。
これは絶対にやってはいけません。
バイアスの大小など気にもせず、しれーっと論文を投稿するとどうなるのか、実際の研究を例にご紹介しましょう。
疫学研究で特に気をつけねばならないバイアスの一つに、誤測定バイアスがあります。
これは、研究で測定できた曝露やアウトカムの値と、真の値の間にズレがあることで生じうるバイアスです。
さて、研究者らは”小児がワクチンを推奨スケジュール通りに接種した時とそうでない時の、対象疾患の発症に対する因果効果を比較する”という設定において、意図的に誤測定バイアスを作り出し、それが結果にどう影響するかを趣味レーションしました。
こちらは、真のリスク比を0.5とした時(つまり、推奨スケジュール通りの接種で疾患発症リスクが半減する)のシュミレーション結果です。
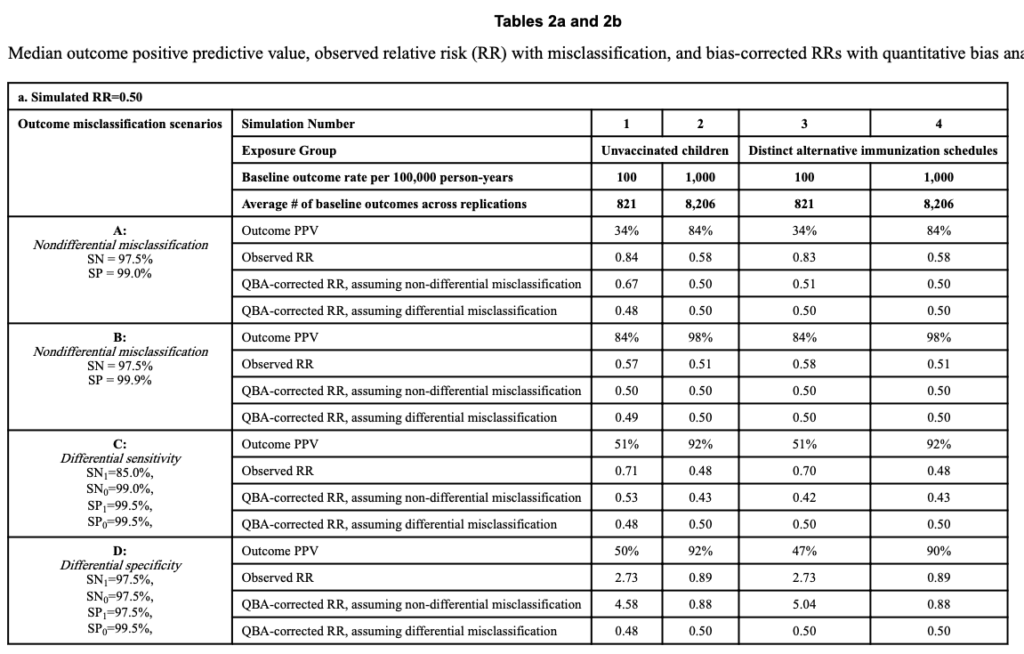
ややこしい数字が並んでいて目がチカチカしますが、左のA~Dが誤測定バイアスのインパクトを変えた際のそれぞれのシュミレーション結果です。
肝心のリスク比がどうなったかというと、それぞれのシュミレーションの”Observed RR”というところを見てみましょう。
BやCなど誤測定バイアスのインパクトが小さいシュミレーションでは、リスク比は真の値からは僅かにズレるのみです。
しかし、Dなどは測定されたリスク比が2.73と全く逆の結果(つまり、リスクが3倍近くになる)になってしまっているものもあります。
さて、もしこんなバイアスまみれの研究結果が世に出てしまったらどうなるでしょうか?
ワクチンの推奨スケジュール通りの接種は、本当は疾患発症リスクを半減するにも関わらず、人々は「推奨スケジュール通りの接種でリスクが3倍近く上がってるじゃないか、ふざけるな!そんなの中止だ!」と激怒するかもしれません。
その結果、人々からは疾患発症リスクを半減にしていたはずのワクチン接種の機会が奪われてしまい、大きく健康を損なわせることになってしまうのです。
だからこそ、研究を世に出す研究者たちは、その結果に責任を持ち、より正しい結果のみを世に出すように努力せねばならないわけですよね。
その努力の一つが、今回ご紹介する実現可能性調査なのです。
実現可能性調査の方法は、次の章でご紹介しますが、その前に大切なことを一点お伝えさせてください。
実現可能性調査を実施するときには、必ずその分野のドメインの専門家、疫学の専門家、統計の専門家の3者を入れて行いましょう。
決してその分野の研究に慣れていない方々だけで行なってはいけません。
実現可能性調査もまた、疫学研究の一部であり、高度な専門性を必要とする技能になります。
どこにバイアスの余地があるのか、
そのバイアスを制御する方法はないのか、
制御できないとしたら、そのバイアスは許容されうるレベルかどうか
そうした点から、専門家は入念な実現可能性調査を行います。
ですので、実現可能性調査を行う際には、ぜひとも身の回りの各種専門家にご相談してみてください。
実現可能性調査のやり方
さて、ここからは実現可能性調査の方法を解説していきましょう。
とは言ったものの、実は詳細な調査方法は既に他の記事で解説済みです。
詳細はそれぞれの記事を見て欲しいのですが、「3本分も読めんわー!」という方向けに、特に押さえておきたいポイントをお伝えします。
サンプルサイズ
研究をやるためには、当然ながら研究対象となる患者のデータがなければなりません。
特定の疾患の有病割合が知りたいといった記述疫学においてはサンプルサイズを気にする必要はありませんが、比較研究を行う際には入念にサンプルサイズを調査しなければなりません。
しかし、シンプルにサンプルサイズといっても調べるのはそう簡単ではありません。
例えば、新薬Aと同クラスの薬剤群Xの間で有害事象である骨折のリスクを比較することを計画していたとしましょう。
このとき、ただ単に使用を検討しているデータベースにおいて、「新薬Aと同クラスの薬剤群Xの使用者数」を出すだけでは不十分です。
さらに、以下のような点に注意する必要があります。
Inclusion/Exclusion criteriaを適合する
実際研究を行う際には、解析に使用できるのはInclusion/Exclusion criteriaを適合し、残った患者のみになります。
ただ単に薬剤Aの使用者数だけなら10,000人いたけれども、Inclusion/Exclusion criteriaを適合したところ、患者数が2,000人まで減ってしまったとしたら、前者だけでの見積もりは大幅に実際とずれることになります。
経年変化を見る
サンプルサイズはTotalではなく経年で算出しましょう。
なぜなら、それによって患者数の将来推計を行うことができるからです。
製造販売後調査においては未来数年間に渡ってデータを集め続けますが、このときに「何年後には患者数はX人にまで増加/減少しているだろう」という予測が経たねば、解析を実施する未来時点でのサンプルサイズを推計することはできません。
薬剤曝露の定義を複数設定する
薬剤疫学では、曝露の定義方法もいくつか存在します。
詳細は以下をご覧ください。
Gold StandardであるIncident New User Design(完全にそのクラスの薬剤に対して未治療の患者だけを集める)ができるのか、
それともPrevalent New User Designなのか、
比較群は薬剤クラスなのか、単剤なのか、それとも薬剤未使用者なのか、
実際の研究では単一の曝露定義を用いることは稀で、感度分析によって複数定義のもとでの結果を導出することになりますが、サンプルサイズの調査においても、それぞれの曝露定義でどのようにサンプルサイズが変化するかということを調べねばなりません。
振り向き期間・追跡期間は十分か
何らかの曝露・介入からアウトカム発症までを追う際には、その作用機序から考えて、アウトカム8章までに必要な期間は最低限追跡できねばなりませんね。
たとえば、有害事象としての骨折を見る際に、追跡期間が平均30日では十分に骨折を観察することはできないでしょう。
*そういったことは下記のブログに書いています。
ですので、それぞれの曝露・介入定義を設定したときに患者の追跡期間がどれくらいなのかということを調べる必要があります。
この際も、ただ単に各患者のデータが発生している期間だけを合計して平均値を算出するだけでは不十分です。
例えば、MDVのような病院ベースの医療データベースでは「一定期間の診療報酬請求の発生がなければ、追跡を打ち切る」という条件設定が必要になります。
この際、「一定期間」をどう設定するかによっても当然ながら追跡期間は変化しますね。
対象とする曝露・介入、アウトカムによっても変わりえますが、この期間を30日、60日、90日とそれぞれ設定して、その時の追跡期間がどうなるかをしっかりとみてあげましょう。
また、これは追跡期間だけではなく、患者の背景情報を調べる際に用いる振り向き期間においても同じことが言えます。
曝露・アウトカムは妥当に定義できるか
曝露・アウトカムが正しく測定できているか、そしてどのようなアルゴリズムを用いればより適切に曝露・アウトカムが定義できるのか。
医療データベース研究では、そうして妥当な曝露・アウトカム定義を探らねばなりません。
例えば、ターゲットのアウトカムが肺塞栓であれば、
・先行研究で肺塞栓の病名妥当性・アルゴリズムを検証した研究はあるか
・その研究の結果は、今回の研究に適用可能か
・できなければ、臨床的妥当性などを考えることで、肺塞栓を妥当に定義することが可能か(例えば、日本のガイドライン上は肺塞栓の確定診断のためには絶対に検査Xを行う、または肺塞栓が生じた患者には絶対に薬剤Yを投与するなどの条件が成立しているならば、検査Xや薬剤Yを組み合わせることで、より適切に肺塞栓を定義することができます)
私の経験では、医療データベース研究の初心者の方は、この曝露・アウトカム定義の妥当性がやや甘くなりがちだなと思っております。
妥当性定義は、「〜だから大丈夫」と明確に反論できるだけの材料を揃えねばなりません。
「妥当性はよくわからない」は、「研究結果を気をつけて解釈しよう、リミテーションに書こう」ではなく、そのアウトカムに対しては医療データベース研究を行うことはできないのです。
いさぎよく諦めましょう。
「そのアウトカム、妥当性はあるんですか?」
と言われた際、
「わかりません」
などと返してしまえば、そこでジ・エンドです。
なぜなら、そもそもアウトカムの妥当性がわからない、つまり使用しているアウトカムの定義がどれだけ信用できるかどうか分からないのであれば、どんな研究結果が出てきたとしても、「でもそれって信用ならないんでしょう?」で一蹴されてしまいますから。
比較可能性
比較可能性とは、薬剤A/Bの2群間比較を行う際に、きちんと(交絡因子に対して)均質な患者群同士を比較できているかどうかということです。
今回は比較可能性の解説記事ではないので詳細は述べませんが、比較可能性がないままに比較研究を行ってしまうと、交絡バイアスの影響を受けてしまいます。
そのため疫学研究を行う際には、比較研究を実施する前に必ず両群間の背景因子のバランス状態を確かめましょう。
標準化差などを使うのが良いと思います。
また、傾向スコアマッチングやIPTWなどのバランシングメソッドを用いる場合には、適用後にバランシングが成功しているかどうかも確かめねばなりません。
バランシングができていれば、晴れて比較研究を実施、、、
とはならないんですね。
なぜなら、傾向スコアマッチングやIPTWといったバランシングメソッドで対処できる交絡因子は、測定された交絡因子のみであり、未測定の交絡因子に対するバランシングは行えていないからです。
しかしながら、医療データベース研究では手元にあるデータで勝負するしかありませんので、追加で変数を収集することはできません。
ですので、手元にあるデータで十分に交絡因子の調整を行えるかどうかを検討する必要があります。
また、例えば薬剤同士を比較する際には、それらの薬剤が実臨床でどのような患者に対して用いられているのかをヒアリングする必要があります。
信頼できる臨床医に確認し、「同じような患者像に用いている」ということがわかれば、臨床的妥当性の観点から比較可能性が上昇したと考えられます。
また、私は必ず当該薬剤に関する診療ガイドラインも併せてみるようにしています。
医療データベースでは手元にあるデータだけでは比較可能性の有無に確信を抱くことが難しい場合が少なくないので、こうして臨床的妥当性の観点からも比較可能性をアセスメントする必要があるわけですね。
終わりに
いかがでしたでしょうか?
今回は、疫学研究の実現可能性調査について解説しました。
これまで説明したPICO/FINERはわりかし色んな書籍で解説されているのですが、実現可能調査に関しては説明している書籍も少なく、皆さん困っているかもしれないと思い記事にしてみました。
研究結果に責任を持つのは著者自身。
実現可能性がない、バイアスにまみれた結果を世に出してしまい、それで臨床家や患者さんが不利益を被ったのなら、それは研究者自身の責任です。
そのような事態にならないように、慎重に、とにかく慎重に実現可能性調査を行っていきましょう。
すきとほる疫学徒からのお願い
本ブログは、全ての記事をフリーで公開しており、「対価を払ってやってもいいよ」と思ってくださった方のみに、その方が相応しいと思っただけの対価をお支払い頂けるPay What You Want方式を採用しています。
教育に投資できる方だけがさらに知識を身につけ、そうでない方との格差が開いていくという状況は、容認されるべきではないと考えているからです(そもそも私程度の記事によって知識の格差が広がると考えていることが、勘違いかもしれませんが)。
私自身も高校卒業後は大学・大学院の学費、生活費と自分で工面する中で、親の支援を得られる友人たちがバイトをせずに学習に集中したり、海外留学や旅行などの経験を積んだりする様子を見て、非常に悔しい想いをした経験があるので、そういった悔しさも本ブログの原動力の一つになっています。
読者の皆様におかれましては、「勉強になった!」、「次も読みたい!」と本ブログに価値を感じてくださった場合のみ、ご本人の状況が許す限りにおいて、以下のボタンからご自身が感じた価値に見合うだけの寄付を頂戴できますと幸いです。
もちろん価値を感じなかった方、また学生さんなど金銭的に厳しい状況にある方からのご寄付は一切不要です。






