

こんにちは、すきとほる疫学徒です。
ここ数年で注目を高めているリアルワールドデータ。
昨日公開した記事では、「僕たちにリアルワールドデータが必要な8つの理由」として、RCTと比較しながら、リアルワールドデータを用いることのポジティブな面を解説しました。
こんにちは、すきとほる疫学徒です。 ここ数年で注目を高めているリアルワールドデータ。 製薬企業のような環境におりますと、業界全体でリアルワールドデータへの期待値が高まっており、これまでリアルワールドデータと[…]

しかしながら、良いこともあれば悪いこともあるというのがこの世の常。
リアルワールドデータを使うことで、RCTの弱点が全て克服できてハッピー、リアルワールドデータ最強!なんてことはもちろんありません。
ということで今回は、RCTと比較しながら、リアルワールドデータを用いることのネガティブな面(注意しなければならない面)を解説していきたいと思います。

「RWD研究の支援をしてほしい」というご相談を多くの企業様から頂戴するので、企業様向けに正式に窓口を設置しました。
以下のアドレスに連絡頂ければ私に直通しますので、「1時間の無料相談」も含めてお気軽にご連絡ください(3営業日以内にお返事させて頂きます)。無料相談は大変ご盛況となっており、先着順にて対応させて頂いております。
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
私が経営するmMEDICI株式会社ではRWD利活用支援を事業の柱の一つとしており、以下の強みを有しています。「企業の」RWD研究においては日本トップクラスの解像度と経験値を有する自信がありますので、ぜひ無料相談でご体験くださいませ。
- 元大手外資の日本・グローバル出身の疫学専門家が全案件を担当するので、「企業の」RWD研究に高い解像度を有しています
- ただ成果物を納品するだけでなく、グローバルやKOLとの合意形成、社内プレゼン、規制当局対応などRWD研究の「プロセス」も全てまきとれます
- 企業のRWD研究を幾度となく経験しており、企画立案から論文化までの全フェーズを一気通貫で対応できます
- アカデミアのRWD研究者と広い繋がりを有しており、必要に応じた専門人材のアサインが可能です
- RWD研究だけでなく、事業立案、マーケ、広報、営業などのRWDビジネスも全て対応可能です
以下に私の実績を記載させて頂きます。
- 大手外資製薬2社にて、部門唯一の疫学専門家として活動をリード
- 「RWDビジネスの教科書」の書籍を出版(サイドバーをご覧ください)
- 企業でのRWD研究の経験は50本以上
- 製造販売後データベース調査のリード経験多数
- これまで製薬、CRO、コンサル、総合商社、ヘルステックなど10社以上の企業のRWD研究・RWDビジネスを支援
- 50組織以上にRWD研修を提供
- 全体統括・講師を勤めたJapan RWD Summitでは初回から約1,700名の集客を実現
無料相談では、以下のような内容を含め企業様の「RWD」と名のつく相談でしたら全て対応させて頂きます。
- このテーマでRWD研究はできるの?
- RWD研究っていくらくらいかかるの?
- RWD研究ってどんなプロセスでやれば良いの?
- 製造販売後データベース調査のやり方を教えてほしい
- RWD研究をするにはどんな専門家を雇えば良いの?
- 自社のRWDサービスを売りたいんだけど、強みはどこ?集客はどうすれば良い?
無料相談は先着順での対応となりますので、ご希望の企業様はぜひお早めのコンタクトをお願い致します!
お問合せ先:naoki.hirose@mmedici.co.jp(廣瀬個人アドレス)
なぜリアルワールドデータに注意せねばならないのか
昨日の記事「僕たちにリアルワールドデータが必要な8つの理由」でも理由を説明致しましたが、企業においてリアルワールドデータは注目を集めています。
その強みから「使ってみよう!」と判断する方もいれば、コストなどのビジネス的な理由から「使ってみよう!」と判断する方もいますし、中には「何か流行ってるし、凄いらしいから」という曖昧な理由でRWD研究の実施を決定する方もいらっしゃるでしょう。
しかしながら、リアルワールドデータの特徴を十分に理解しないままに研究を行うのは、非常に危険です。
RCTと違い、リアルワールドデータ、特に医療大規模データベース研究はデータベースへのアクセスさえ有していれば、比較的低コスト・短時間で研究ができてしまうので、ある意味気軽に研究が行えるようになっています(もちろん、データを集めてくださる方々の並々ならぬご尽力のおかげ、ですが)。
その反面、医療大規模データベースのようなリアルワールドデータを用いた研究では、コホートの選択、曝露やアウトカムの定義において大きなバイアスが入る余地が大きく、適切な研究デザインの下に実施されなかったRWD研究は、大きなバイアスを有した結果を提示してしまいます。
その結果を解釈した際に、疫学・生物統計学の専門家であれば、「あー、この曝露だとこんな感じでバイアスがかかってるから、ちょっと結果は慎重に解釈しないといけないな」と、バイアスの影響を差し引きながら解釈ができると思いますが、全ての方がそうではありません。
むしろ、そのような冷静な解釈ができるのは極一部の専門家のみであり、現場の医療職、患者の方々は、論文のアブストラクトや、それを基に作成されるニュース、リーフレットなどを読んで、「そうなのか!」と結果を解釈されるでしょう。
つまり、その結果が算出されるまでの科学的手法の質に関わらずに、公表された途端に結果だけが一人歩きしてしまうわけですね。
そうなると何が起こるでしょうか?
例えば、本当は薬剤Aは有害事象Xを引き起こすリスクがあるにも関わらず、Biasedな効果推定を行った結果、「薬剤Aと有害事象Xの間には関連があるとはいえない」という結果になり、有害事象Xが懸念されないままに薬剤Aが使用されてしまうかもしれません。
サリドマイドがその際たる例ですが、取り返しのつかない薬害が起こり得ます。
反対に、本当は薬剤Aは有害事象Yとは因果関係がないにも関わらず、Biasedな効果推定行った結果、「薬剤Aと有害事象Yとの間には関連がある」という結果になり、有害事象Yが強く懸念された結果、誤解に基づいて薬剤Aが市場から回収されてしまうかもしれません。
すると、本当は薬剤Aを使用すれば治療できていた患者さんが、害を被ってしまいます。
このように、薬剤疫学における誤った効果推定は、公衆衛生に対して直接的にネガティブなインパクトを与えるリスクを内包しています。
まさにその研究のためにオーダーメイドのデータ収集を行うRCTと比べ、リアルワールドデータ、特に診療行為や保険請求などの目的で集めたデータを2次的に援用する医療大規模データベース研究にはBiasedな効果推定に繋がるリスクがあちこちあり、正しく用いるには、こういったリスクを念頭に置き、適切なデザインを組む努力が必要になるのです。
「とりあえずリアルワールドデータ研究が流行ってるから、やってみよう」というように、専門家を入れずに、データがあるからという理由だけで研究をおこなってしまうのは非常に危険です。
では、リアルワールドデータを使用する際にはどのような点に注意せねばならないのか、細かく考えていきましょう。
コホート選択におけるデメリット
昨日のブログで、「RCTでは厳格な適格基準のもと、限定的な患者コホートを形成するが、RWD研究では実臨床で薬剤を使った全ての患者を対象にしうるので、RWD研究は通常RCTのコホートから漏れてしまう患者を対象にした研究ができる」とお伝えしました。
しかしながらRWD研究のこの”様々な患者をコホートに組み込める”というメリットの裏側には、”効果推定をおこなっているコホートが曖昧になってしまいやすい”というデメリットがあります。
たとえば、抗がん剤を例に考えてみましょう。
通常抗がん剤の臨床研究を行う際には、適格基準として癌のステージ、大きさ、部位、転移の有無、マカー、その他検査値などを明確に定義し、「これだ!」という患者のみをコホートに加えます。
一方、RWD研究、特に医療大規模データ研究(以下、Secondary RWD研究)ではこのように厳密な定義でコホート選択をすることは不可能です。
そもそも診療報酬請求データベースでは、これらのデータはほぼ取得不可能です(DPCデータであれば、入院患者に限れば入院時の癌のステージはわかりますが)。
電子カルテデータベースであれば、マーカー含め検査値データは入手できるかもしれませんが、RCTと比べると入力精度はかなり落ちます(実際に電子カルテデータベースで研究をしたことがある方は分かると思いますが、とんでもない値が結構入っています)。
その結果、Secondary RWD研究で癌患者を対象にコホートを組む場合、”過去1年間に癌病名が2回ついている”といった、”癌があるかどうか”レベルでの定義しかできない場合が殆どです*。
*仮に、特定の状態の癌にしか使用しない薬剤・検査・医療行為があれば、それらを使ってさらにspecificなコホート形成を行うことができますが。
さて、このようにRWD研究でコホートが曖昧になることで、どのようなデメリットが生じるのでしょか?
まず、その研究結果の外的妥当性を考えることが難しくなります。
外的妥当性とは、「コホートAで行った因果効果の推定が、コホートBにも外挿できるのか」ということであり、研究結果を実世界に活かす上で非常に大切な切り口です。
もしその研究結果が、実際に研究者が研究をおこなったコホートAでしか成立しないのだとしたら、研究の意義というのは極めて限定的なものになってしまいます。
このような外的妥当性を検討する上では、「自分が因果効果の推定を行ったコホートが、どのような集団であるのか」ということを明確に理解している必要があります。その理解がなければ、「コホートAに比べて、コホートBではどうか」といった比較ができませんので。
例えば、先ほどの抗がん剤の例で言えば、「癌Xを有する患者で因果効果を推定した」という研究を目の前に持ってこられても、臨床医は「え、癌Xを有するって言っても、癌の状態でぜんぜん患者違うんだけど。つまるところ、どんな状態の癌なら薬剤Aは効くの?具体的に教えてくれないと薬使えないよ」と思うかもしれませんね。
次なるデメリットとしては、効果修飾因子の影響を考えることが難しくなることがあります。
効果修飾因子とは、その因子があることで、曝露とアウトカムの因果効果が修飾される因子を指します(すいません、説明下手ですよね)。
例えば、薬剤Aと有害事象Xの因果関係を調べる際に、男性だけを対象に解析をしたところOdds ratio = 1.4という結果となりました。
一方で女性だけを対象に解析したところ、Odds raito = 2.5という結果になりました。
この時、性別という効果修飾因子があることにより、男性と女性で薬剤Aと有害事象Xの因果関係が異質なものになっていたことがわかります。
このように、効果修飾因子があるにも関わらず、それを考慮せずにOverallのコホートで解析をしてしまうと、誤った効果推定量を導いてしまうリスクがあるのです。
そのためには効果修飾因子によってコホートを層別化せねばなりませんが、そもそも効果修飾因子の測定ができていなければ、層別化することはもちろんできません。
外的妥当性の話と同じく、Seconddary RWD研究では入手できる患者情報に限りがあるため、このように適切に効果修飾因子を考慮できないことがあります。
サンプルサイズにおけるデメリット
昨日の記事では、「Secondary RWDはサンプルサイズが大きいから、RCTでは拾えない希少疾患も対象にできる」と書きました。
これはサンプルサイズが大きいことのメリット、つまりβエラー*の観点からのコメントでした。
*βエラーとは、真に関連があるにも関わらず、その関連を見逃してしまうエラーのことで、サンプルサイズが小さい時に発生します。
一方サンプルサイズが大きくなると、βエラーのリスクが下がる代わりに反対に統計的検出力が上がり過ぎてしまい、臨床的には意義のない僅かな差であっても、有意な差として拾い上げてしまうというデメリットがあります。
例えば、薬剤Aと薬剤Bを比較した際に、アウトカムである有害事象Xの発生割合がそれぞれ9.02%と9.01%だったとしましょう。
この時、サンプルサイズが100人であれば、P値上は”統計的有意差なし”と判定されますが、サンプルサイズが100万人もいれば、”有意差あり”として判定されてしまいます(シミュレーションしているわけではないので、あくまでもイメージです)。
しかしながら、統計的有意性と臨床的有意性は全く異なる概念です。
有害事象Xの種類にもよりますが、仮に有害事象Xが比較的ポピュラーな疾患だとしたら、薬剤Aと薬剤Bの間の0.01%のリスク差を検出することには殆ど意味はないでしょう。
ましてや、薬剤Aが薬剤Bより高価であり、頻回の服薬が必要であり、さらに他の有害事象の発生リスクが高いといった状況であれば、有害事象Xの0.01%のリスク差を重視して薬剤Aを選択するメリットはありません。
このように統計的有意性の指標であるP値はサンプルサイズに依存するということもあり、主たる医学雑誌を筆頭に使用が非推奨となってきましたが、それでもP値を意思決定の根拠とする医学雑誌、臨床の専門家もまだ少なくはないでしょう。
ですので、大規模なサンプルサイズを扱えるSecondary RWD研究においては、統計的有意性と臨床的有意性は違うということを念頭に置き、意義の乏しい差を”意義のある差だ”と誤解させないように丁寧に読者に結果を伝える姿勢が必要だと考えております(Statistically significant, but clinically insignificantなんて表現はたまに目にしますね)。
曝露定義におけるデメリット
RCTと違って、Secondary RWDを用いた際の最大のデメリット(と私が思っている)が、この曝露定義の難しさです。
治験においても効果推定の対象とする事象は、”薬剤の内服”ではなく”薬剤の処方”であることが多いですが、しかし治験では内服状態を詳細にモニタリングすることで、”薬剤の内服”と”薬剤の処方”を近似させるべく努力が行われております。
しかしながら、Secondary RWD研究ではそうもいきません。
手に入るデータは薬剤を処方したこと、もしくは調剤したことを示す処方・調剤データまでで、実際に患者がその薬剤を内服していたかどうかは完全にブラックボックスです。
また内服していたとしても、医師の指示通りに内服していたかも分かりませんし、そもそも医師が内服にあたり、どんな指示を出していたかも不明な場合が殆どです。
このような状況で推定される、”薬剤Aの効果”とは、一体どのような効果なのでしょうか?
また、曝露の有無を正しく測定できていなければ、測定バイアスにより因果効果が歪められてしまうことが報告されています。
こちらは、「曝露に測定ミスがあった際に、真実の因果効果がどれだけ歪められるか」ということを検証した研究の結果です。
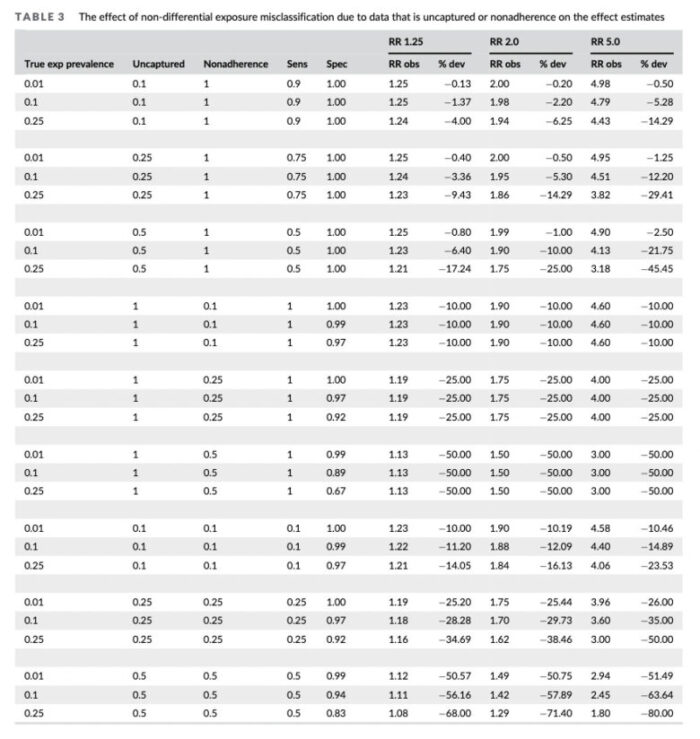
右の3行がそれぞれ真のリスク比を1.25、2.0、5.0とした時の観測されたリスク比ですが、どの結果も真のリスク比よりも小さいリスク比が観測されてしまっていることが分かると思います。
そのためSeconrary RWD研究では、慎重に曝露の扱いを検討せねばならないのです。
なお、曝露の誤測定や、望ましい定義方法に関する解説はこちらの記事で行なっておりますので、ぜひご覧ください。
こんにちは、すきとほる疫学徒です。 曝露の誤測定についてはこれまで幾つかの記事で紹介してきました。 それらの記事は曝露の誤測定が結果に与える影響をコンセプチュアルに説明することに注力していましたが、「実際に数字を見た[…]

こんにちは、すきとほる疫学徒です。 ここからしばらくは、薬剤疫学の曝露定義について一連の記事を書いていく予定です。 個人的には、2次的RWDを用いた薬剤疫学研究において、最も厄介なのがこの曝露定義だと思っています。 […]

アウトカム定義におけるデメリット
Secondary RWD研究において、クリアカットに曝露を定義することが難しいのと同様、アウトカムの定義にも難しさがあります。
通常RCTでは、判定委員会のような独立した組織を設け、曝露の有無をブラインドした状態で、事前に定義された条件に沿ってアウトカムの判定が行われます。
しかしながらSecondary RWD研究では、アウトカムは診療報酬請求や電子カルテ記載のものを信用する他なく、ブラインドも行わなければ、独立した組織による詳細な判定も行われません。
これにより、アウトカムの誤測定バイアスが生じ得ます。
診療報酬請求データは、保険償還を受けるためにデータですので、目的は「診療行為を正確に伝える」ことではなく、「望ましい保険償還を受け取る」ことにあります。
診療行為の記録は電子カルテで行われますので、極論を言ってしまえば、診療報酬請求データの病名が、真実の病名と異なっていたとしても、医師が患者を診療する上では大きなデメリットはないわけですね。
医師にとっては日常の仕事とは関連のないところにリソースを使ってまで、診療報酬請求データ上で正しい病名を記載することは強い負担になりますので、”正確な病名を記載する”とは反対の方向にインセンティブが働くわけです。
となると、癌の検査を実施するために事前に付与した”癌疑い”という病名を削除しないまま放置したり、正確にはICD-10: C34.1 “肺癌:上葉、気管支又は肺”である癌病名を、面倒だからC34″肺癌”までしかつけなかったりということが起こりうります。
また、診療報酬請求データでは、過去に付与された疾患も医師から転機(治療、死亡など)を入力されない限りは、アクティブな病名として掲載され続けますが、医師からすれば診療報酬請求データ上に20年前の腰痛や盲腸が残っていようが残っていまいが支障がありませんので、過去の病名が転機を付与されずに残存し続けるということも起こり得ます。
曝露のブラインドが行われないことのデメリットも考えてみましょう。
”もしかすると薬剤Aと有害事象Xに関連があるかもしれない”というニュースがテレビで流れたとすると、医師は薬剤Aと投与している患者において積極的に有害事象Xを見つけるよう、頻回のフォローアップをしたり、通常は行わないような検査をしたりするかもしれません。
これにより、本来は薬剤Aと薬剤Bで有害事象Xの発症頻度は同程度だったとしても、薬剤Aにおいて医師が積極的に有害事象Xを見つけようとした結果、見かけ上は薬剤Aにおいて有害事象が多く見つかってしまいます。
これもアウトカムの誤測定によるバイアスの一つです。
このようなアウトカムの誤測定バイアスを防ぐために、Secondary RWD研究を行う際には、バリデーション研究といって、Secondary RWD研究で定義したアウトカムが、どれだけ真のアウトカムを捉えられているかということを確認するための研究を行います。
こちらは、日本のDPCデータを用いたバリデーション研究の結果です。
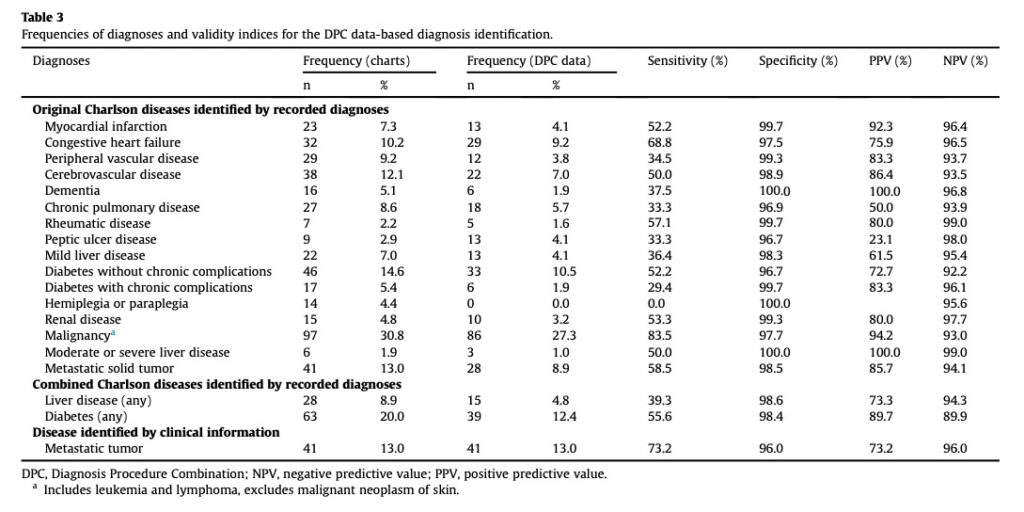
この結果を見ると、日本のDPC研究では、特異度とNPVは比較的高いが、感度とPPVは疾患によってはかなり低いものがあるということが分かるかと思います。
例えば、Myocardial infarctionは感度52.2%であり、これは”真実のMI患者のうち、データベース上では52.2%しか拾うことができなかった”ということを表します。
また、Chronic pulmonary diseaseはPPV50%であり、これは”データベース上でCPDと定義された患者のうち、真のCPD患者は50%しかいなかった”ということを表しています。
これらの妥当性指標に関して突っ込んだ話は、こちらの記事に書いていますので、ぜひご覧になってみてください。
こんにちは、すきとほる疫学徒です。 データベース研究においては、曝露やアウトカムを定義するために設定した条件(アルゴリズム)が「本当に見たいものを正しく定義できているか」というアルゴリズムの妥当性を考える必要があります。 […]

さて、上記のバリデーション研究の結果を見て「こんなに正答率が低いのか⁈」と驚かれた方もいらっしゃるのではないでしょうか?
そうなんです、Secondary RWDの病名を、そう簡単に信用してはいけないのです。
だから、Secondary RWD研究でアウトカム定義を決める際には、過去に行われたバリデーション研究や、その疾患の特性を鑑みながら、少しでも正確な定義を作成しようと努力するわけです。
「これがベストだ!」という単一の定義を見つけられれば幸運で、多くの研究では複数の定義を作成し、それぞれの研究結果を比較するなんてこともやります。
また、非常に多くのお金と時間がかかりますが、場合によってはSecondary RWD研究の前にバリデーション研究を実施し、望ましいアウトカム定義を作成する、なんてこともあります。
これだけアウトカム定義の決定に時間をかけるのは、Secondary RWD研究におけるアウトカム定義の作成が非常に難しいからであり、そして間違ったアウトカム定義を使用してしまうと、誤測定バイアスにより歪んだ結果を報告することに繋がってしまうからなのです。
比較群の選択におけるデメリット
Secondary RWDを用いて比較研究をする際に最も気をつけなければならないことが、「比較可能性(Comparavility)のある比較群を選択する」ということです。
RCTにおいては、ランダム化という人類が生み出した奇跡のような手法を用いることで、理論的には測定されていない交絡因子まで含めて2群間でのバランスを保つことができます。
一方、Secondary RWDでは現実世界でその薬剤を使用している患者のデータを2次的に使用するわけですから、ランダム化などできるわけがありませんよね。
というわけで、Secondary RWD研究では事前に比較を行いたい2群が本当に(交絡因子において)比較可能な類似した患者であるのかということを確認せねばなりませんが、肝心の交絡因子のデータが測定できていなければ、比較可能性の確認も何もありません。
未測定の交絡に対しては、「データはないが、バランシングできているだろう」という非常に強い仮定をおいて研究するしかないわけです。
比較可能性というのは因果推論が成立するための必須条件の一つですが、それだけ重要な条件にもかかわらず、「できているだろう」と仮定するしかないというのは、大変心もとなく感じるかもしれませんね。
こちらのシュミレーション研究では、2つの交絡因子と曝露の相関関係を何パターンか設定し、交絡因子の調整を行わなかった時、1つのみ調整した時、2つとも調整した時のOdds比を算出しました。なお、真のOdds比は1.0とされています。
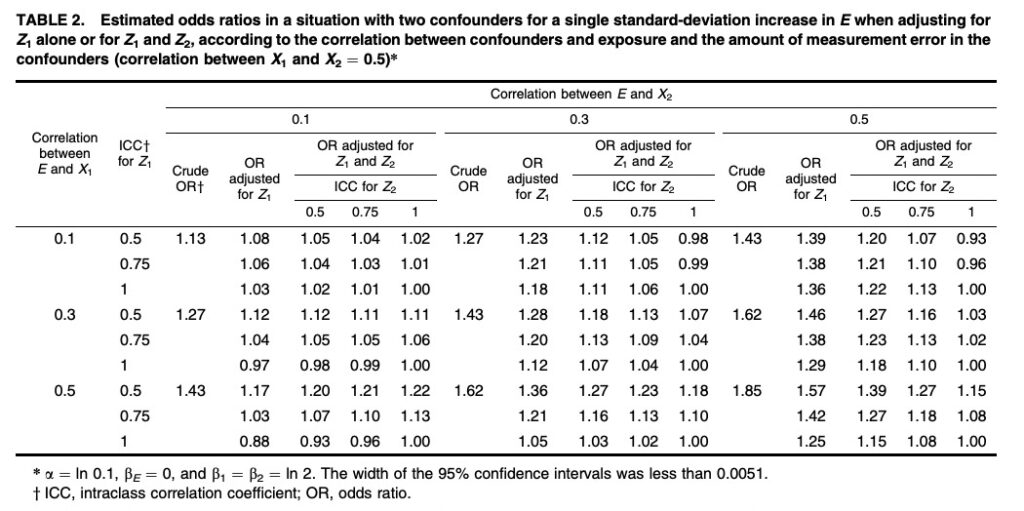
例えば、2つの交絡因子と曝露との相関係数がそれぞれ0.5となる箇所を眺めてみましょう。
すると、交絡因子を2つとも調整しなかった際のOdds比は1.85となり、真のOdds比1.0から大きく乖離していることが分かります。
このように、曝露もしくはアウトカムとの強い関連がある交絡因子を未測定なままに因果効果の推定を行なってしまうと、強くバイアスのかかった結果が導かれてしまうということがわかるでしょう。
なおSecondary RWD研究において、この未測定の交絡に対処するために、これまで様々な手法が研究者よって開発されてきました。
Difference-in-Difference、Regression discontinuityのような自然実験、E-value、Negative control designなどです。
ですので、Secondary RWD研究を実施する際には、こう言った手法を含め、「少しでも未測定の交絡に対処できる方法がないだろうか」とベストな手法を使用することを目指しながら研究を行う必要があるでしょう。
患者の追跡におけるデメリット
RCTにおいては、まず最初に対象者の選択を行い、その直後に治療を割り付けを実施、それと同時に患者を追跡し始める(Time zero)というように、この3つのタイミングが一致させることができます。
しかしながら、Secondary RWD研究ではここが一致しないことが珍しくありません。
例えば、対象者の選択が治療の割り付け・追跡開始よりも後に発生するパターンです。
有害事象である癌をアウトカムとした研究において、長期の誘導期間・潜在期間を考慮し、2年間の追跡期間を設定したとしましょう。
そして、2年未満しか追跡できなかった患者は、解析から除外したとします。すると、最終的に解析に含まれる対象者の選択は、治療の割り付け・追跡開始よりも後に発生していることになりますね。
この時、2年間追跡できた患者とできなかった患者の間で、アウトカムのリスク因子の分布が異なっていると、選択バイアスが発生します。
別の例では、まず治療の割り付けが起こり、そこからしばらく後に患者の追跡が開始される場合です。
薬剤疫学研究でいうPrevalent userですね。
通常RCTでは、「よーいドン」で治療の割り付けを行い、追跡を開始するため、追跡開始以前に治療に曝露しているということは起こり得ません。
しかしながらSecondary RWDでは、「データがないため、いつからか不明だが、薬剤に曝露し続けた患者」を対象に含むことがあります。
すると、こういった患者というのは「薬剤Aには副作用のリスクがあるにも関わらず、薬剤Aに曝露し続けられた患者(less susceptible patients)」になり、ここでも選択バイアスが生じてしまいます。
ここでは深く突っ込みませんが、このようなPrevalent user biasとその対処法については、こちらの記事で解説しているので、ぜひご覧ください。
こんにちは、すきとほる疫学徒です。 本日は、薬剤疫学分野で観察研究を行う際に注意しなければならないバイアス、Prevalent user biasを取り上げ、その理論的背景、具体例、そして対処法について解説していきたいと思[…]

このような事態を避けるためには、治療割り付けのタイミングの前後で十分な期間のデータが取得できていなければなりません。
しかしながら、病院ベースのSecondary RWDではその病院以外での治療実態は完全に不明ですので、前後のデータが取得できません。
同様に保険者ベースのSecondary RWDであったとしても、結婚や転職をしてしまえば別の保険に移ってしまうため、患者追跡をすることができません。
こちらの研究では、追跡開始以前に何ヶ月の期間を取れば、Prevalent userを除外し、New userだけを解析に含められるかというシュミレーションを行いました。
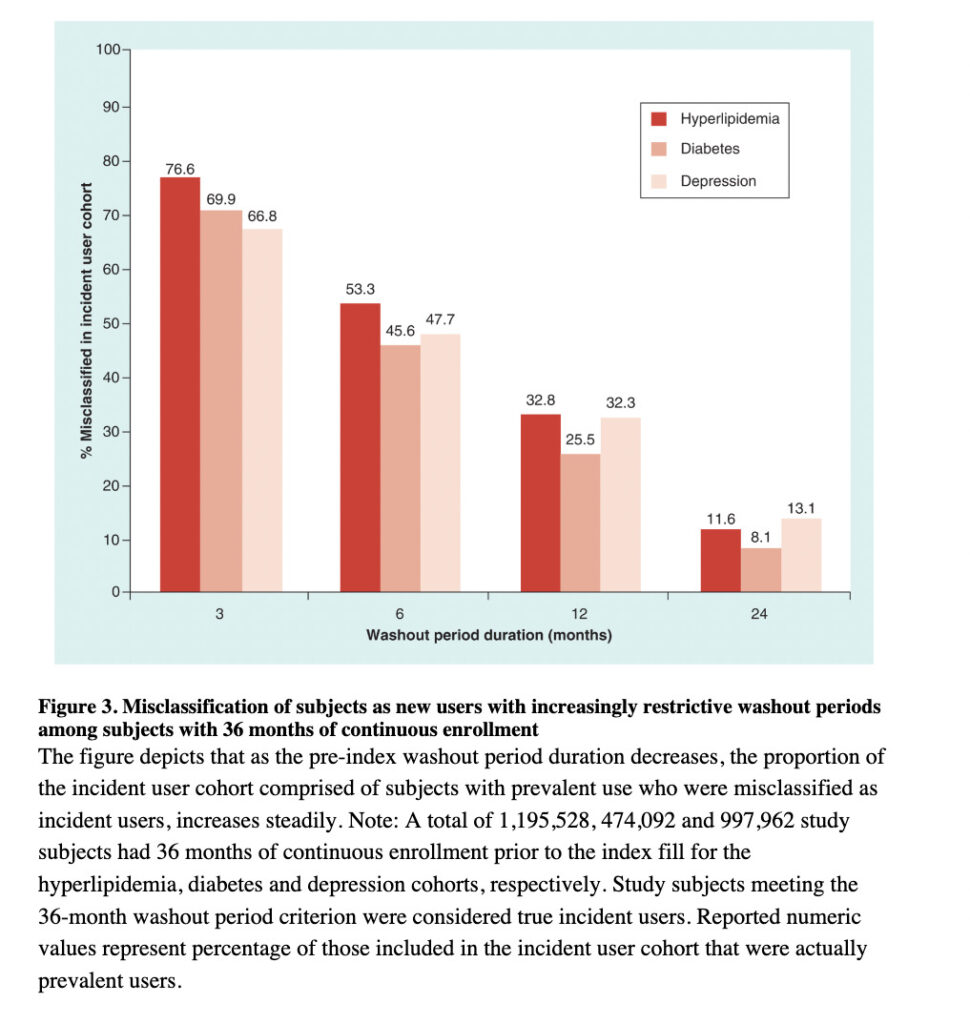
ご覧のように、Washout periodを3ヶ月しか取らなかった場合には、70%前後ものPrevalent userの患者が、誤ってNew userとして定義されてしまっていることが分かります。
Washout periodを24ヶ月にした場合には、10%前後に抑えることができて(?)いますが、しかしこの場合は”追跡前に24ヶ月のデータを有する患者”にコホートが限定されてしまい、非常に多くの患者がコホートから除外されてしまいました。
恣意的な結果の報告によるデメリット
これは全てのSecondary RWD研究がそうというわけではなく、研究のプロセス上、Secondary RWD研究はRCTよりも結果の恣意的な報告が起こる余地があるという話です。
RCTにおいては、研究を実施する前に公にプロトコールや解析計画を登録し、イレギュラーな事態がない限りは予定した計画に沿って研究を進める必要性があります。
また、RCTのように大規模な研究では、非常に膨大な数の人間が研究に関与するため、一個人の研究者によって恣意的に患者選択をおこなったり、解析結果を歪めたり、報告する結果を選択したりということが起こりにくいプロセスになっています。
しかしながら、Secondary RWD研究においては、現時点ではRCTのように事前にプロトコールや解析計画を提出する必要がありません(製薬企業が製造販売後安全性調査の目的で行うSecondary RWD研究は、PMDAに事前のプロトコール・解析計画提出が求められているため、この限りではありません)。
またデータへのアクセスさえあれば、研究メンバーが筆頭著者一人だけであっても解析、論文執筆、公表と全てのプロセスをこなすことができます。
そして、殆どのJournalが、実際に解析を行ったデータや、そのコードの提出を義務付けているわけではありません。
そうなると、プロセス上は「とりあえず解析して、いちばん研究者にとって都合の良いデザインを見つけておいて、後付けでそのデザインを選択する」ということが可能になってしまうわけですね。
つまり、Secondary RWD研究における結果の報告というのは、報告者である研究者への信頼を基に「真である」と判断するしかないのです。
終わりに
さて、いかがでしたでしょうか?
前回の記事に引き続き、今回はRCT比較した際のSecondary RWD研究のデメリットを説明してきました。
データさえ集めてしまえば比較的シンプルに解析が行えるRCTと異なり(RCTはそこに行くまでに膨大な時間と人手とお金をかけているわけですから)、Secondary RWDではデータが集まってからが勝負です。
目の前にどれだけ贅沢な食材があっても、その味を生かすも殺すも料理人である研究者の腕次第といったところでしょうか。
しかも、医学分野の研究というのは人の生き死にに直結する研究なわけですから、Secondary RWDを用いた研究をする際には、今回ご説明した様々なパートにおける落とし穴を理解し、慎重にそれを回避するようにデザインを組んでいかねばなりません。
ですので、「使えるデータがあるから」という理由だけで研究をスタートするのではなく、まずはしかるべき専門家に相談し、そして研究の実現可能性を慎重に検討し、「いける」と判断ができてようやく研究に取り掛かるのが良いでしょう。
ちなみに、こうした研究の実現可能性の調べ方はこちらの記事に始まる3つの記事で解説しております。
こんにちは、すきとほる疫学徒です。 製薬企業で疫学研究をしておりますと、色々なところでデータベース事業者さんからお声をかけて頂くことがあるのですが、ここ数年でデータベース事業者さんや、事業者さんが扱う医療大規模データベース[…]

・落とし穴に気づかず研究をしてしまうと、バイアスまみれの結果を導いてしまいかねない
・本当にこのRWDを用いて研究ができるか、まずは慎重に実現可能性をチェックしなければならない
すきとほる疫学徒からのお願い
本ブログは、読者の方が自由に記事の金額を決められるPay What You Want方式を採用しています。
「勉強になった!」、「次も読みたい!」と本ブログに価値を感じてくださった場合は、以下のボタンをクリックし、ご自身が感じた価値に見合うだけの寄付を頂戴できますと幸いです。
もちろん価値を感じなかった方、また学生さんなど金銭的に厳しい状況にある方からのご寄付は不要です。
引き続き情報発信していく活力になりますので、ぜひお気持ちに反しない範囲でご寄付をお願い致します!





